強化学習を使用した PMSM のベクトル制御
この例では、強化学習の制御設計法を使用して永久磁石同期モーター (PMSM) のベクトル制御 (FOC) を実装する方法を示します。この例では FOC の原理を使用します。ただし、PI コントローラーの代わりに強化学習 (RL) エージェントを使用します。FOC の詳細については、ベクトル制御を参照してください。
次の図は、強化学習エージェントを含む FOC のアーキテクチャを示しています。強化学習エージェントの詳細については、強化学習エージェント (Reinforcement Learning Toolbox)を参照してください。
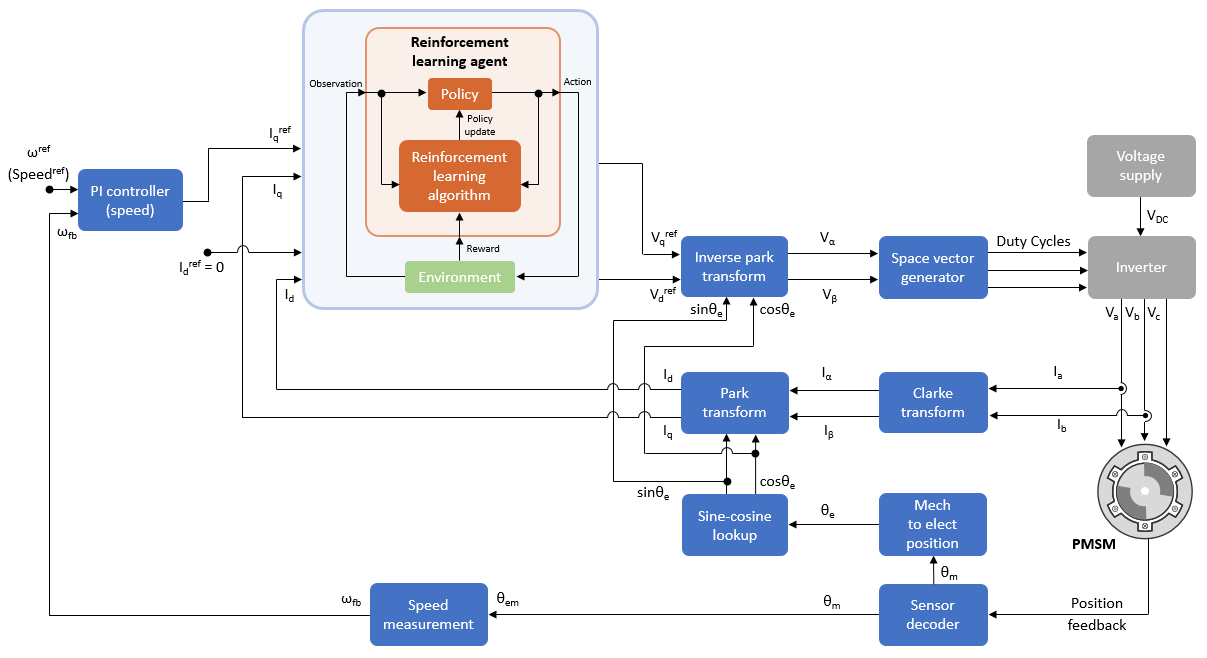
強化学習エージェントは、d 軸と q 軸の電流を調整し、モーターを必要な速度で駆動させる対応する固定子電圧を生成します。
強化学習エージェントを使用する FOC アルゴリズムの速度追跡性能は PI コントローラーベースの FOC と同等になります。
モデル
この例には mcb_pmsm_foc_sim_RL モデルが含まれています。
メモ: このモデルはシミュレーションにのみ使用できます。
このモデルには、強化学習エージェントを使用する FOC のアーキテクチャが含まれています。openExample コマンドを使用して Simulink® モデルを開くことができます。
openExample('mcb/FieldOrientedControlOfPMSMUsingReinforcementLearningExample','supportingFile','mcb_pmsm_foc_sim_RL.slx');
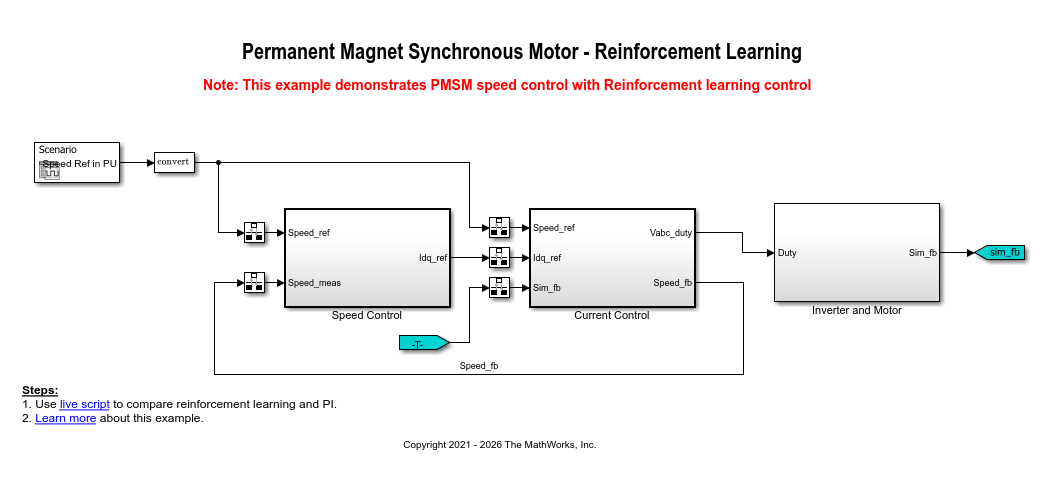
モデルを開くと、モーター パラメーターなどの構成済みのパラメーターがシミュレーション用にワークスペースに読み込まれます。それらのパラメーターを確認および更新するには、mcb_pmsm_foc_sim_RL_data.m モデル初期化スクリプト ファイルを開きます。このスクリプトで使用できる制御パラメーターおよび変数の詳細については、Estimate Control Gains and Tune Control Parametersを参照してください。
次のコマンドを実行して、Current Controller Systems サブシステムの内部にある強化学習の設定にアクセスできます。
open_system('mcb_pmsm_foc_sim_RL'); open_system('mcb_pmsm_foc_sim_RL/Current Control/Control_System/Closed Loop Control/Current Controller Systems');
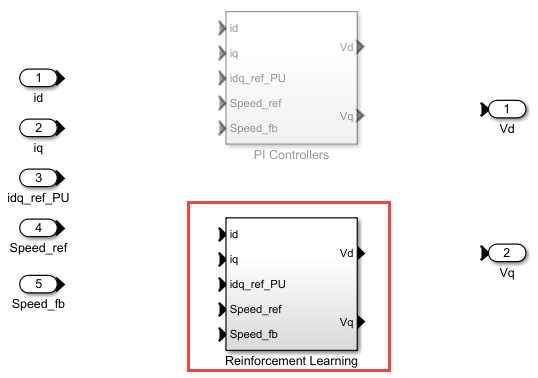
PMSM を制御するための強化学習エージェントの設定と学習の詳細については、Train TD3 Agent for PMSM Control (Reinforcement Learning Toolbox)を参照してください。
メモ:
強化学習エージェントの学習は計算量が多いプロセスであり、完了するまでに数時間かかることがあります。
この例のエージェントは、5 KHz の PWM 周波数を使用して学習させてあります。したがって、既定ではこの周波数がモデルで使用されます。この値を変更するには、別の PWM 周波数を使用して強化学習エージェントにもう一度学習させ、
mcb_pmsm_foc_sim_RL_data.mモデル初期化スクリプトでPWM_frequency変数を更新します。モデル初期化スクリプトは、次のコマンドを使用して開くことができます。
edit mcb_pmsm_foc_sim_RL_data;
必要な MathWorks 製品
Motor Control Blockset™
Reinforcement Learning Toolbox™
モデルのシミュレーション
次の手順に従ってモデルをシミュレートします。
1. mcb_pmsm_foc_sim_RL をクリックして、この例に含まれているモデルを開きます。
2. 次のコマンドを実行して、FOC のアーキテクチャ内にある Current Controller Systems サブシステムの Reinforcement Learning バリアントを選択します。
ControllerVariant='RL';Current Controller Systems サブシステムに移動して、Reinforcement Learning サブシステム バリアントがアクティブかどうかを確認できます。
open_system('mcb_pmsm_foc_sim_RL/Current Control/Control_System/Closed Loop Control/Current Controller Systems');
メモ: このモデルでは、Reinforcement Learning サブシステム バリアントが既定で選択されています。
3. 次のコマンドを実行して、事前学習済みの強化学習エージェントを読み込みます。
load('rlPMSMAgent.mat');メモ: この例の強化学習エージェントは、0.2、0.4、0.6、および 0.8 PU の速度指令を使用するように学習させてあります。pu 単位系に関する詳細については、Per-Unit Systemを参照してください。
4. [シミュレーション] タブの [実行] をクリックして、モデルをシミュレートします。次のコマンドを使用してモデルをシミュレートすることもできます。
sim('mcb_pmsm_foc_sim_RL.slx');### The Lq is observed to be lower than Ld. ### ### Using the lower of these two for the Ld (internal variable) ### ### and higher of these two for the Lq (internal variable) for computations. ### ### The Lq is observed to be lower than Ld. ### ### Using the lower of these two for the Ld (internal variable) ### ### and higher of these two for the Lq (internal variable) for computations. ###
5. [シミュレーション] タブの [データ インスペクター] をクリックして、シミュレーション データ インスペクターを開きます。観測する信号を次の中から 1 つ以上選択し、速度追従とコントローラーの性能に関連するシミュレーション結果を解析します。
Speed_refSpeed_fbiq_refiqid_refid
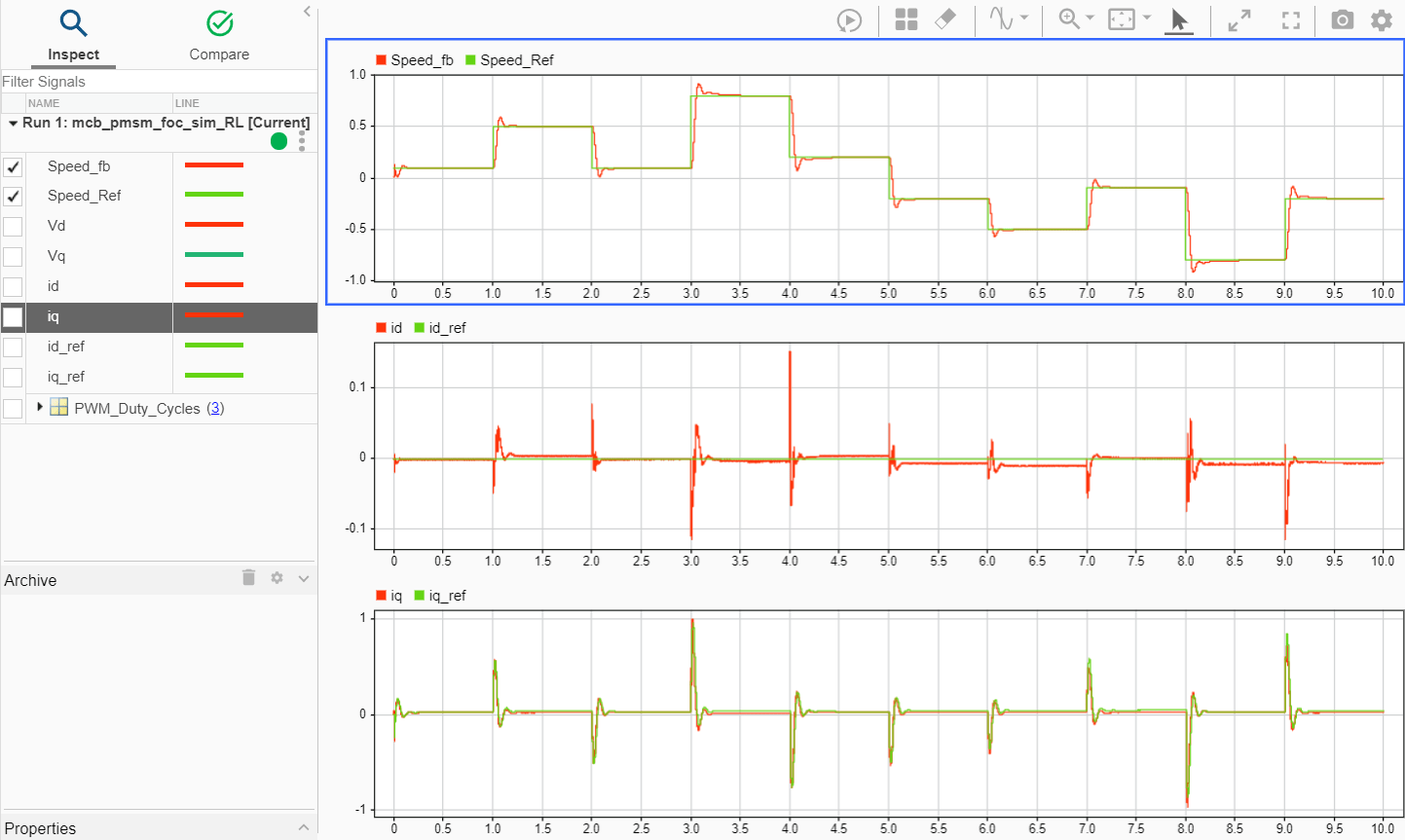
上記の例では、以下のようになります。
PI コントローラーと強化学習コントローラーの組み合わせにより、速度指令信号の変化に追従して必要な速度が達成されます。
2 番目と 3 番目のデータ インスペクター プロットは、学習済みの強化学習エージェントが電流コントローラーとして機能し、
IdとIqの両方の指令電流に正しく追従していることを示しています。ただし、IdとIqの電流の指令値と実際値の間に小さい定常偏差が存在します。
シミュレーションを使用した RL エージェントと PI コントローラーの比較
以下の手順に従って、PI コントローラーの速度追従とコントローラーの性能を解析し、それらを強化学習エージェントの性能と比較します。
1. mcb_pmsm_foc_sim_RL をクリックして、この例に含まれているモデルを開きます。
2. 次のコマンドを実行して、FOC のアーキテクチャ内にある Current Controller Systems サブシステムの PI Controllers バリアントを選択します。
ControllerVariant='PI';Current Controller Systems サブシステムに移動して、PI Controllers サブシステム バリアントがアクティブかどうかを確認できます。
open_system('mcb_pmsm_foc_sim_RL/Current Control/Control_System/Closed Loop Control/Current Controller Systems');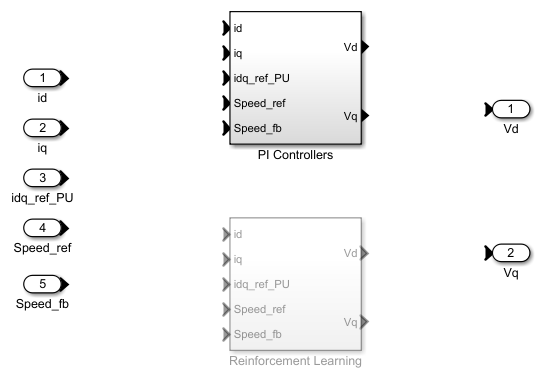
メモ: このモデルでは、Reinforcement Learning サブシステム バリアントが既定で選択されています。
3. [シミュレーション] タブの [実行] をクリックして、モデルをシミュレートします。次のコマンドを使用してモデルをシミュレートすることもできます。
sim('mcb_pmsm_foc_sim_RL.slx');### The Lq is observed to be lower than Ld. ### ### Using the lower of these two for the Ld (internal variable) ### ### and higher of these two for the Lq (internal variable) for computations. ### ### The Lq is observed to be lower than Ld. ### ### Using the lower of these two for the Ld (internal variable) ### ### and higher of these two for the Lq (internal variable) for computations. ###
4. [シミュレーション] タブの [データ インスペクター] をクリックして、シミュレーション データ インスペクターを開きます。観測する信号を次の中から 1 つ以上選択し、速度追従とコントローラーの性能に関連するシミュレーション結果を解析します。
Speed_refSpeed_fbiq_refiqid_refid
5. これらの結果を、RLAgent (Reinforcement Learning) サブシステム バリアントを使用して得られた前のシミュレーション実行結果と比較します。
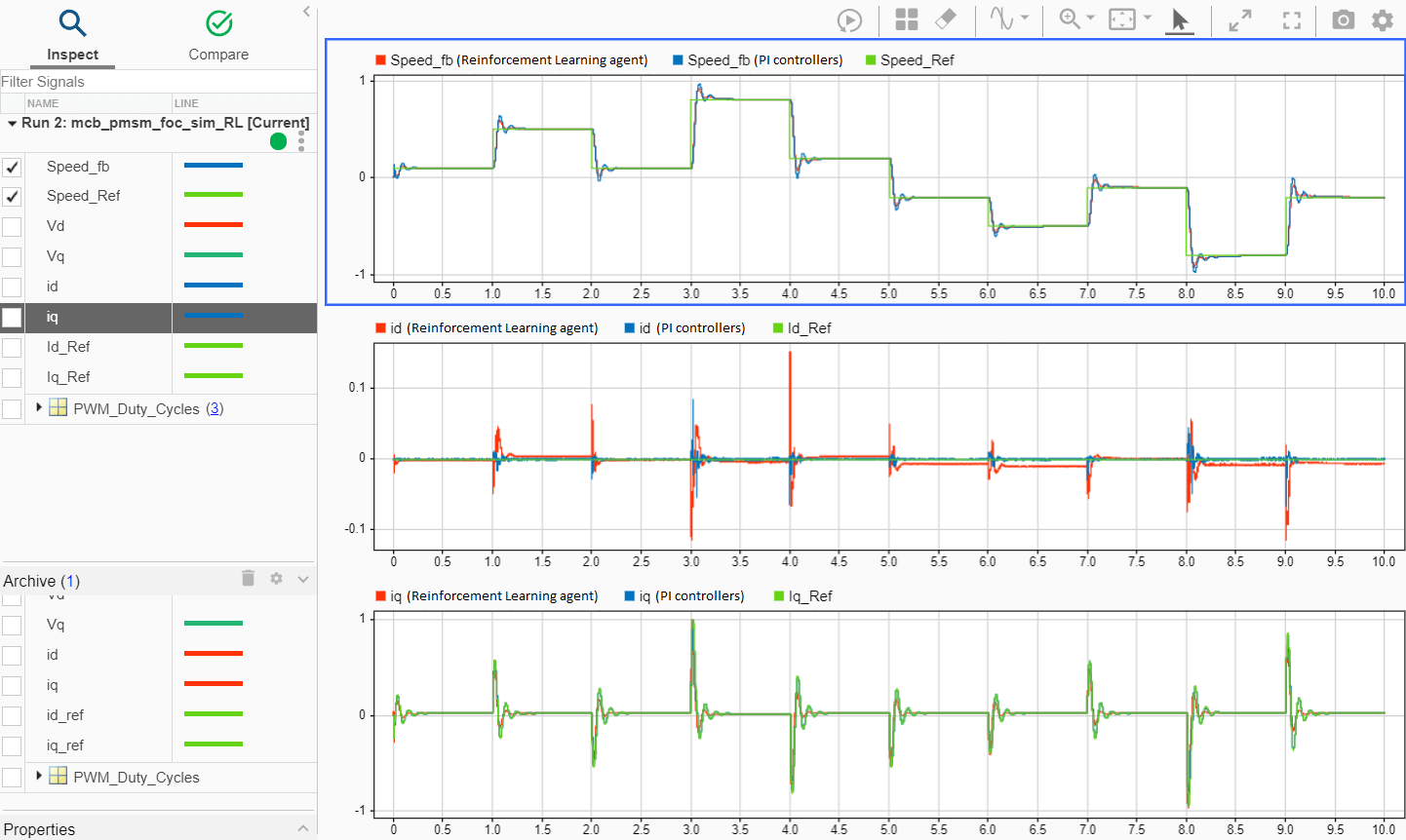
上記の例では、以下のようになります。
赤の信号は、RLAgent (Reinforcement Learning) サブシステム バリアントを使用して得られたシミュレーション結果を示しています。
青の信号は、PIControllers (PI Controllers) サブシステム バリアントを使用して得られたシミュレーション結果を示しています。
プロットは、強化学習エージェントの性能 (
Id指令電流の追従は例外) が PI コントローラーと同等であることを示しています。強化学習エージェントの電流追従性能は、エージェントにさらに学習させてハイパーパラメーターを調整することで改善できます。
メモ: 指令速度をさらに高い値に更新し、同じようにして強化学習エージェントと PI コントローラーの性能を比較することもできます。