GPU パフォーマンスの測定と向上
GPU パフォーマンスの測定
GPU でのコードのパフォーマンスの測定
コードのパフォーマンスの重要な測定項目に実行時間があります。GPU でのコードの実行時間を測定する最良の方法は、関数 gputimeit を使用することです。この関数を使用すると、関数を複数回実行することで変動が平均化され、オーバーヘッドが補正されます。また、関数 gputimeit では、必ず GPU でのすべての演算が完了してから時間が記録されます。
たとえば、サイズが N 行 N 列の乱数行列 A の LU 分解を関数 lu で計算するのにかかる時間を測定します。この測定を実行するには、関数 lu の関数ハンドルを作成し、その関数ハンドルを gputimeit に渡します。
N = 1000;
A = rand(N,"gpuArray");
f = @() lu(A);
numOutputs = 2;
gputimeit(f,numOutputs)コードの時間の測定には、tic と toc も使用できます。ただし、tic と toc の場合、GPU でのコードの実行時間の正確な情報を取得するには、演算が完了するまで待ってから呼び出さなければなりません。これを行うには、gpuDevice オブジェクトを入力として指定して関数 wait を使用します。たとえば、tic、toc、および wait を使用して、行列 A の LU 分解の計算時間を測定します。
D = gpuDevice; wait(D) tic [L,U] = lu(A); wait(D) toc
コードの各部分の所要時間は、MATLAB® プロファイラーを使用して確認できます。コードのプロファイリングの詳細については、profile およびパフォーマンス向上のためのコードのプロファイリングを参照してください。プロファイラーはコードのパフォーマンスのボトルネックを特定するのに便利ですが、GPU の使用時に一般に発生するオーバーラップ実行については考慮されないため、GPU コードの正確な時間は測定できません。
次の表を参考に、使用する時間測定方法を決めてください。
| 時間測定方法 | 適したタスク | 制限 |
|---|---|---|
gputimeit | 個々の関数の時間測定 |
|
tic および toc | 複数のコード行やワークフロー全体の時間測定 |
|
| MATLAB プロファイラー | パフォーマンスのボトルネックの特定 | プロファイラーでは各コード行が個別に実行され、GPU の使用時に一般に発生するオーバーラップ実行については考慮されません。プロファイラーは GPU コードの正確な時間を測定する方法としては使用できません。 |
GPU のベンチマーク
GPU の強みと弱みの特定や各種 GPU のパフォーマンスの比較には、ベンチマーク テストが便利です。次のベンチマーク テストを使用して GPU のパフォーマンスを測定します。
倍精度の行列計算について、PCI バスの速度、GPU メモリの読み取り/書き込み、ピーク計算のパフォーマンスなど、GPU に関する詳細な情報を取得するには、GPU のメモリ帯域幅と処理能力の測定の例を実行します。
単精度と倍精度でメモリ使用量や計算量が多いタスクをテストするには、
gpuBenchを使用します。gpuBenchは、アドオン エクスプローラーまたは MATLAB Central File Exchange からダウンロードできます。詳細については、https://www.mathworks.com/matlabcentral/fileexchange/34080-gpubench を参照してください。
GPU パフォーマンスの改善
MATLAB の GPU 計算の目的は、コードの高速化です。コードの記述や GPU ハードウェアの構成に関するベスト プラクティスを実装することで、GPU でのパフォーマンスを改善できます。パフォーマンスを改善するためのさまざまな方法を以下に示します。実装が簡単なものから順番に示してあります。
次の表を参考に、使用する方法を決めてください。
| パフォーマンス改善方法 | この方法を使用する状況 | 制限 |
|---|---|---|
GPU 配列の使用 – サポートされる関数に GPU 配列を渡してコードを GPU で実行する | 全般に適用可能 | 関数が |
MATLAB コードのプロファイリングと改善 – コードをプロファイリングしてボトルネックを特定する | 全般に適用可能 | GPU でのコードのパフォーマンスの測定セクションで説明したように、プロファイラーは GPU でのコードの実行時間の正確な測定には使用できません。 |
計算のベクトル化 – for ループを行列演算とベクトル演算に置き換える | for ループ内でベクトルまたは行列の演算を行うコードを実行する場合 | 詳細については、ベクトル化の使用を参照してください。 |
単精度での計算の実行 – 使用するデータの精度を下げて計算を少なくする | 値の範囲の縮小や精度の低下を許容できる場合 | 線形代数問題などの一部の種類の計算には、倍精度の処理が必要な場合があります。 |
|
|
サポートされている関数と他の制限の詳細については、 |
| 多数の小さな行列に対して独立した行列演算を実行する関数を使用する場合 | すべての組み込みの MATLAB 関数がサポートされているわけではありません。サポートされている関数と他の制限の詳細については、 |
CUDA コードを含む MEX ファイルの記述 – GPU 関数の追加ライブラリにアクセスする | NVIDIA® のライブラリや CUDA の高度な機能にアクセスする場合 | CUDA C++ フレームワークを使用して記述されたコードが必要です。 |
GPU パフォーマンスのためのハードウェアの構成 – ハードウェアを最適に利用する | 全般に適用可能 |
|
GPU 配列の使用
コードで使用しているすべての関数が GPU でサポートされている場合、必要な変更は gpuArray を呼び出して入力データを GPU に転送することだけです。gpuArray の入力をサポートする MATLAB 関数のリストについては、GPU での MATLAB 関数の実行を参照してください。
GPU メモリのデータは gpuArray オブジェクトに格納されます。MATLAB および他の多くのツールボックスに含まれているほとんどの数値関数が gpuArray オブジェクトをサポートしているため、通常は最小限の変更でコードを GPU で実行できます。これらの関数は gpuArray 入力を受け取り、GPU で計算を実行して gpuArray 出力を返します。一般に、これらの関数は CPU で実行される標準の MATLAB 関数と同じ引数とデータ型をサポートしています。
ヒント
オーバーヘッドを減らすには、ホスト メモリと GPU の間でのデータ転送の回数を制限します。可能であれば配列を GPU で直接作成します。詳細については、GPU 配列の直接作成を参照してください。データを表示または保存する必要がある場合や gpuArray オブジェクトをサポートしていないコードで使用する必要がある場合も、同じようにgatherを使用して GPU からホスト メモリにデータを再度転送するだけです。
MATLAB コードのプロファイリングと改善
MATLAB コードを変換して GPU で実行できるようにする場合、最初は既に高いパフォーマンスを実現している MATLAB コードを使用するのが最善です。CPU で適切に動作するコードを記述するためのガイドラインの多くは、GPU で実行されるコードのパフォーマンスの改善にも役立ちます。CPU コードは MATLAB プロファイラーを使用してプロファイリングできます。CPU で長い時間を要するコード行については、改善が必要である可能性があります。gpuArray オブジェクトを使用して GPU に移行することも検討してください。コードのプロファイリングの詳細については、パフォーマンス向上のためのコードのプロファイリングを参照してください。
MATLAB プロファイラーでは各コード行が個別に実行されるため、GPU の使用時に一般に発生するオーバーラップ実行については考慮されません。アルゴリズム全体の時間の測定には、GPU でのコードのパフォーマンスの測定セクションで説明したように tic と toc、または gputimeit を使用してください。
計算のベクトル化
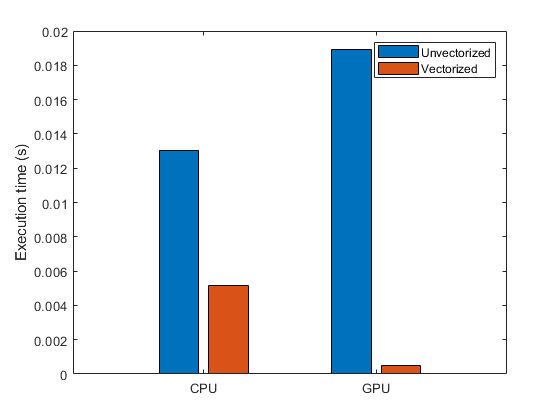
GPU では複数の結果を並列に計算するとパフォーマンスが向上するため、一般に GPU ではベクトル演算、行列演算、および高次元演算の方がスカラー演算よりもはるかにパフォーマンスが高くなります。高次元演算を使用するようにループを書き換えると、パフォーマンスが高まります。ループベースでスカラー指向のコードを、MATLAB 行列およびベクトル演算を使用するように変更するプロセスは "ベクトル化" と呼ばれます。ベクトル化の詳細については、ベクトル化の使用およびGPU とベクトル化された計算を使用したパフォーマンスの改善を参照してください。GPU とベクトル化された計算を使用したパフォーマンスの改善の例にある次のプロットは、CPU と GPU で実行される関数をベクトル化することでパフォーマンスがどれくらい向上するかを示しています。
単精度での計算の実行
GPU は倍精度浮動小数点演算装置 (FPU) よりも単精度 FPU の方が多い場合がほとんどであるため、倍精度の代わりに単精度で計算を実行することにより、GPU で実行されるコードのパフォーマンスを改善できます。一方、CPU 計算のパフォーマンスは、多くの場合、単精度のデータと倍精度のデータで同程度です。
single 関数を使用してデータを単精度に変換できます。また、rand などの作成関数を使用してデータを作成するときに、基となる型 "single" とデータ型 "gpuArray" を指定すると単精度の gpuArray データを直接作成できます。データを単精度に変換する方法と単精度データを直接作成する方法の詳細については、GPU での配列の確立を参照してください。
GPU での単精度計算に適する代表的なワークフローの例には、イメージ処理と機械学習があります。ただし、線形代数問題などの他の種類の計算には、一般に倍精度の処理が必要です。Deep Learning Toolbox™ の多くの演算は、既定では単精度で実行されます。詳細については、Deep Learning Precision (Deep Learning Toolbox)を参照してください。
パフォーマンスの実際の向上は、GPU カードおよび合計コア数に左右されます。単精度と倍精度を比較した GPU の相対的なパフォーマンスの近似測定を確認するには、デバイスの SingleDoubleRatio プロパティをクエリします。このプロパティは、デバイス上の倍精度 FPU に対する単精度 FPU の比率を示します。
gpu = gpuDevice; gpu.SingleDoubleRatio
ほとんどのデスクトップ GPU は倍精度の 24 倍または 32 倍の単精度浮動小数点演算装置を備え、64 倍のものもありますが、データ センター GPU のセンター GPU には 2 倍しかないもの (A100 および H100) もあります。
単精度と倍精度の処理能力を含む NVIDIA GPU カードの総合的なパフォーマンスの概要については、https://en.wikipedia.org/wiki/List_of_Nvidia_graphics_processing_unitsを参照してください。
要素単位関数のパフォーマンスの改善
要素単位の関数がある場合、その関数を arrayfun で呼び出すとパフォーマンスを改善できることがよくあります。GPU の arrayfun 関数を使って要素単位の MATLAB 関数をカスタム CUDA カーネルに変換すると、処理実行のオーバーヘッドを削減できます。多くの場合、コード全体が arrayfun でサポートされていなくても、コードのサブセットで arrayfun を使用できます。arrayfun を使用すると、ループや分岐のコード内で要素単位の演算を多数実行する関数、入れ子関数から親関数で宣言された変数にアクセスする入れ子にされた関数など、さまざまな要素単位の関数のパフォーマンスを改善できます。
arrayfun を使用した、要素単位の MATLAB 関数の GPU におけるパフォーマンス改善では、arrayfun の基本的な適用例を示します。モンテカルロ シミュレーションでの GPU arrayfun の使用では、ループ内で要素単位の演算を実行する関数のパフォーマンスを arrayfun を使用して改善する例を示します。GPU でのステンシル演算では、親関数で宣言された変数にアクセスする入れ子関数を arrayfun を使用して呼び出す例を示します。
小さな行列に対する演算のパフォーマンスの改善
多数の小さな行列に対して独立した行列演算を実行する関数がある場合、その関数を pagefun で呼び出すとパフォーマンスを改善できます。pagefun を使用すると、行列をループ処理する代わりに、行列演算を GPU で並列実行できます。pagefun による GPU 上の小さな行列問題のパフォーマンス改善の例は、多数の小さな行列に対して演算を行う場合に pagefun を使用してパフォーマンスを改善する方法を示しています。
CUDA コードを含む MEX ファイルの記述
MATLAB には GPU 対応関数の広範なライブラリが用意されていますが、MATLAB に類似するものがない追加関数のライブラリにもアクセスできます。例としては、NVIDIA Performance Primitives (NPP)、cuRAND ライブラリなどの NVIDIA ライブラリがあります。CUDA C++ フレームワークで記述した MEX ファイルを関数 mexcuda を使用してコンパイルできます。コンパイルした MEX ファイルを MATLAB で実行し、NVIDIA ライブラリから関数を呼び出すことができます。gpuArray 入力を受け取って gpuArray 出力を返す MEX 関数を記述して実行する方法の例については、CUDA コードを含む MEX 関数の実行を参照してください。
GPU パフォーマンスのためのハードウェアの構成
多くの計算は大量のメモリを必要とし、ほとんどのシステムではグラフィックスに絶えず GPU を使用するため、通常、計算とグラフィックスに同じ GPU を使用することは現実的でありません。
Windows® システムには、GPU デバイスの動作モデルが 2 種類あります。WDDM (Windows Display Driver Model) または TCC (Tesla Compute Cluster) です。コードのパフォーマンスを最適にするには、計算に使用するデバイスを、TCC モデルを使用するように設定します。GPU デバイスで使用されているモデルを確認するには、関数 gpuDevice で返された DriverModel プロパティを検査します。モデルの切り替えや TCC モデルをサポートする GPU デバイスの詳細については、NVIDIA のドキュメンテーションを参照してください。
GPU のメモリが不足する可能性を低減するため、1 つの GPU を MATLAB の複数のインスタンスで使用しないでください。使用可能な GPU デバイスと選択されている GPU デバイスを確認するには、関数 gpuDeviceTable を使用します。
参考
gpuDevice | gputimeit | tic | toc | gpuArray | arrayfun | pagefun | mexcuda