dissect
Nested Dissection 置換
説明
例
複数のメソッドを使用してスパース行列を並べ替え、並べ替えた行列の LU 分解によって発生した非スパース要素を比較します。
west0479 行列を読み込みます。これは 479 行 479 列の実数値スパース行列であり、共役固有値の実数および複素数のペアをもちます。スパース構造を表示します。
load west0479.mat
A = west0479;
spy(A)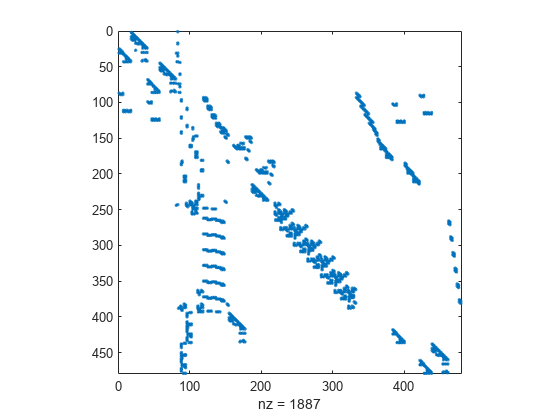
Nested Dissection 順序法を含む複数の異なる方法で、行列の列の置換を計算します。
p1 = dissect(A); p2 = amd(A); p3 = symrcm(A);
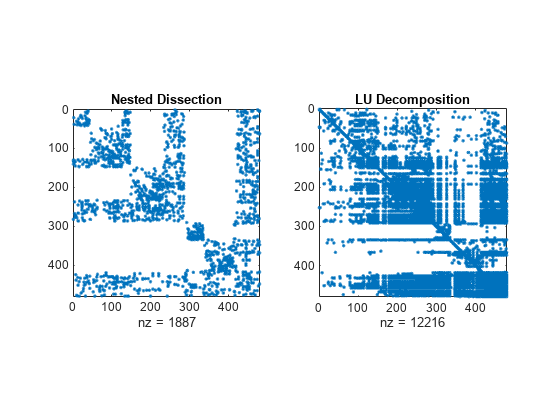
さまざまな並べ替えメソッドを使用して A の LU 分解のスパース構造を比較します。関数 dissect は、発生する非スパース要素数が最小になる並べ替えを生成します。
subplot(1,2,1) spy(A) title('Original Matrix') subplot(1,2,2) spy(lu(A)) title('LU Decomposition')
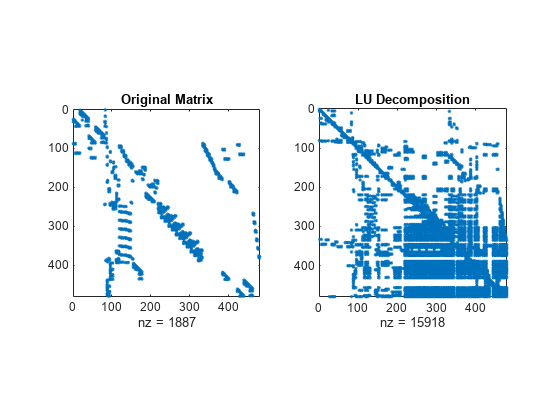
figure subplot(1,2,1) spy(A(p3,p3)) title('Reverse Cuthill-McKee') subplot(1,2,2) spy(lu(A(p3,p3))) title('LU Decomposition')
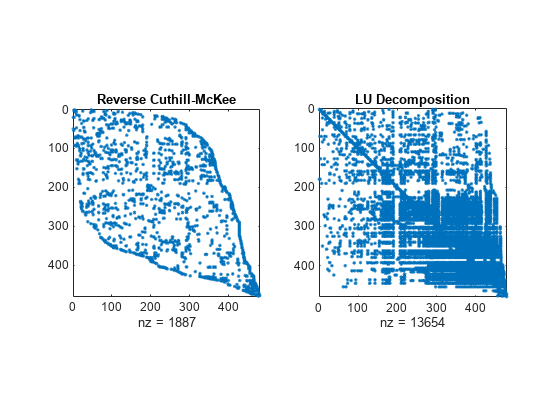
figure subplot(1,2,1) spy(A(p2,p2)) title('Approximate Minimum Degree') subplot(1,2,2) spy(lu(A(p2,p2))) title('LU Decomposition')
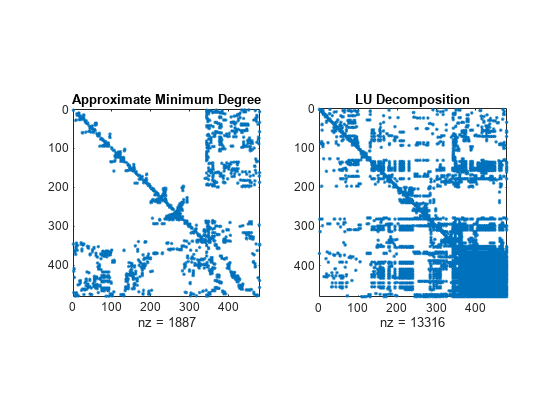
figure subplot(1,2,1) spy(A(p1,p1)) title('Nested Dissection') subplot(1,2,2) spy(lu(A(p1,p1))) title('LU Decomposition')
矢印の先端のように非ゼロ要素が配置された行列は、少数の密な列があるスパース行列です。'MaxDegreeThreshold' の名前と値のペアを使用して密な列をフィルター処理し、並べ替えた行列の末尾に配置します。
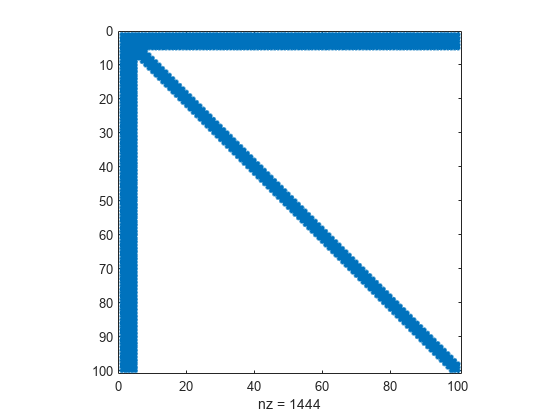
矢印の先端のように非ゼロ要素が配置されたスパース行列を作成して、スパース パターンを表示します。
A = speye(100) + diag(ones(1,99),1) + diag(ones(1,98),2); A(1:5,:) = ones(5,100); A = A + A'; spy(A)
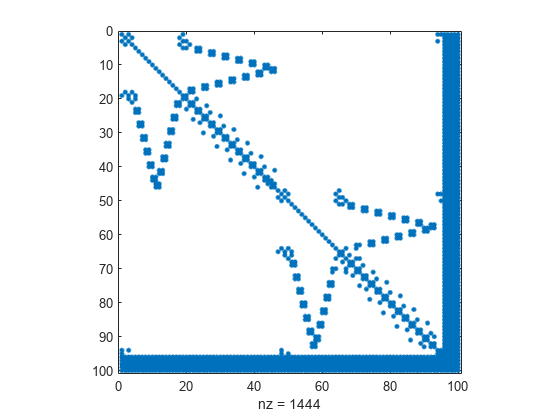
Nested Dissection 順序を計算して、非ゼロ要素が 10 個を超える列をフィルター処理して除外します。
p = dissect(A,'MaxDegreeThreshold',10);並べ替えた行列のスパース パターンを表示します。dissect は、並べ替えた行列の末尾に密な列を配置します。
spy(A(p,p))
入力引数
名前と値の引数
出力引数
アルゴリズム
[1]で説明される Nested Dissection 順序法アルゴリズムは、複数レベルのグラフ分割アルゴリズムで、スパース行列の非ゼロ要素を減らす順序付けの生成に使用されます。入力行列は、グラフの隣接行列として扱われます。このアルゴリズムは、頂点とエッジを縮約することでグラフを疎化し、より小さいグラフを並べ替えてから、洗練ステップを使用してその小さいグラフを密化し、元のグラフの並べ替えを生成します。
dissect の名前と値のペアにより、このアルゴリズムのさまざまな段階を制御できます。
疎化
この段階で、アルゴリズムは頂点の隣接ペアをまとめて縮約することで、元のグラフからより小さいグラフを連続して作成します。
'MaxDegreeThreshold'を使用して、グラフで連結度の高い頂点 (行列内の密な列) の順序を最後にすることで、これらの頂点をフィルター処理して除外できます。分割
グラフを疎化した後に、アルゴリズムは小さいグラフをすべて並べ替えます。各分割ステップで、アルゴリズムはグラフを均等な部分に分割しようと試みます。
'NumSeparators'はグラフを分割する区画数を指定し、'VertexWeights'はオプションで頂点に重みを割り当て、'MaxImbalance'は異なる区画間の重みの差に関するしきい値を指定します。洗練
最小のグラフを並べ替えた後に、アルゴリズムは以前まとめた頂点を細分化して投影を行い、グラフを元の大きさのサイズに戻します。各投影ステップの後に、頂点を区画間で移動して解の品質を向上させる洗練ステップを実行します。
'NumIterations'はこの密化段階で使用する洗練ステップの数を制御します。
参照
[1] Karypis, George and Vipin Kumar. "A Fast and High Quality Multilevel Scheme for Partitioning Irregular Graphs." SIAM Journal on Scientific Computing. Vol. 20, Number 1, 1999, pp. 359–392.
拡張機能
バージョン履歴
R2017b で導入