colamd
列の近似最小次数置換
説明
例
Harwell-Boeing が所有するスパース行列のコレクションから MATLAB® のデモ ディレクトリに用意されているものとして、テスト行列 west0479 があります。これは、Westerberg に基づく 8 ステージの化学蒸留塔のモデルから導出された 479 次の行列です。spy プロットは、8 ステージである証拠を示しています。colamd による並べ替えは、この構造を攪乱させることになります。
load west0479 A = west0479; p = colamd(A); figure() subplot(1,2,1), spy(A,4), title('A') subplot(1,2,2), spy(A(:,p),4), title('A(:,p)')

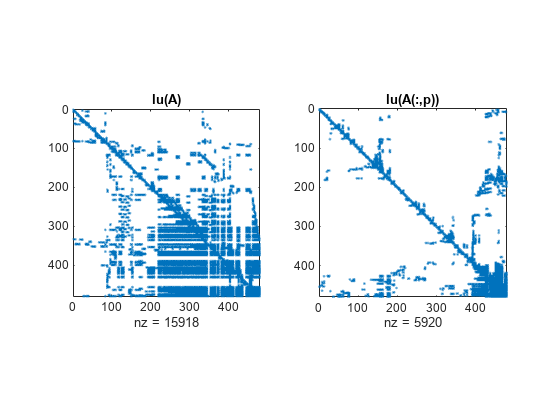
元の行列に対する LU 分解の spy プロットを並べ替え後の行列に対する LU 分解の spy プロットと比較すると、最小次数が、時間と保存の必要条件を 2.8 倍以上も低減させていることがわかります。非ゼロ要素の個数は、それぞれ 15918 個と 5920 個です。
figure() subplot(1,2,1), spy(lu(A),4), title('lu(A)') subplot(1,2,2), spy(lu(A(:,p)),4), title('lu(A(:,p))')
入力引数
出力引数
参照
[1] Davis, Timothy A., John R. Gilbert, Stefan I. Larimore, and Esmond G. Ng. “Algorithm 836: COLAMD, a Column Approximate Minimum Degree Ordering Algorithm.” ACM Transactions on Mathematical Software 30, no. 3 (September 2004): 377–380. https://doi.org/10.1145/1024074.1024080.