シングルレートのリソース共有アーキテクチャ
この例では、HDL Coder™ でモデルからシングルレートのアーキテクチャを生成し、クロックレート パイプラインとリソース共有のコンテキストにおいて演算の実行を管理する方法を示します。設計内のブロックにリソース共有を適用すると、HDL Coder は、共有が行われる領域のサンプル レートに基づいて使用するアーキテクチャを決定します。最も速い基本サンプル レートで動作する設計領域でリソース共有が行われると、面積の最適化のためのリソース共有で説明されているように、HDL Coder は局所的なマルチレートのアーキテクチャを合成します。この例では、それよりも遅いサンプル レートで動作する領域に共有リソースがあるため、HDL Coder はクロックレート パイプラインを適用し、シングルレートのアーキテクチャを合成します。
クロックレート パイプラインは、遅いサンプル レートでデータの演算を行っている個別のロジック領域を設計から特定し、それよりも速いクロック レートでパイプラインとリソース共有のロジックを挿入する最適化です。このような場合、リソース共有は、シングル レートで動作し、レイテンシを伴う、時間多重化されたアーキテクチャとして実装されます。HDL Coder は、依存関係にある演算を実行し、追加のレイテンシを管理するために、適切なスケジューリング ロジックを合成します。
モデルの検査
モデル hdlcoder_singlerate_sharing を開いて更新します。
load_system('hdlcoder_singlerate_sharing'); open_system('hdlcoder_singlerate_sharing/Subsystem'); set_param('hdlcoder_singlerate_sharing', 'SimulationCommand', 'update');

このモデルには、オーバーサンプリングの制約がオーバーサンプリング係数パラメーターによって定義されています。これは、FPGA クロック レートを Simulink の基本サンプル時間の何倍の速度にするかを指定するパラメーターです。このモデルでは、コマンド ラインを使用してプロパティ Oversampling を設定することで、オーバーサンプリング係数を 30 に設定しています。これは、クロックレート パイプラインが適用された領域の実行が完了するまでに 30 クロック サイクルかかることを意味します。
HDL コードの生成と検証モデルの検査
関数 hdlsaveparams を使用して、個々のブロックとサブシステムに対する最適化オプションを一覧表示します。シングルレートの共有アーキテクチャを確認するために、コードと検証モデルを生成します。
hdlsaveparams('hdlcoder_singlerate_sharing/Subsystem'); makehdl('hdlcoder_singlerate_sharing/Subsystem');
%% Set Model 'hdlcoder_singlerate_sharing' HDL parameters
hdlset_param('hdlcoder_singlerate_sharing', 'GenerateValidationModel', 'on');
hdlset_param('hdlcoder_singlerate_sharing', 'HDLSubsystem', 'hdlcoder_singlerate_sharing');
hdlset_param('hdlcoder_singlerate_sharing', 'Oversampling', 30);
% Set SubSystem HDL parameters
hdlset_param('hdlcoder_singlerate_sharing/Subsystem', 'DistributedPipelining', 'on');
hdlset_param('hdlcoder_singlerate_sharing/Subsystem/Sum_piped', 'Architecture', 'Tree');
% Set Sum HDL parameters
hdlset_param('hdlcoder_singlerate_sharing/Subsystem/Sum_piped', 'OutputPipeline', 2);
% Set SubSystem HDL parameters
hdlset_param('hdlcoder_singlerate_sharing/Subsystem/share', 'SharingFactor', 2);
% Set SubSystem HDL parameters
hdlset_param('hdlcoder_singlerate_sharing/Subsystem/stream1', 'StreamingFactor', 2);
% Set Delay HDL parameters
hdlset_param('hdlcoder_singlerate_sharing/Subsystem/stream1/Delay', 'UseRAM', 'on');
% Set SubSystem HDL parameters
hdlset_param('hdlcoder_singlerate_sharing/Subsystem/stream2', 'StreamingFactor', 4);
### Begin compilation of the model 'hdlcoder_singlerate_sharing'...
### Working on the model <a href="matlab:open_system('hdlcoder_singlerate_sharing')">hdlcoder_singlerate_sharing</a>
### Generating HDL for <a href="matlab:open_system('hdlcoder_singlerate_sharing/Subsystem')">hdlcoder_singlerate_sharing/Subsystem</a>
### Using the config set for model <a href="matlab:configset.showParameterGroup('hdlcoder_singlerate_sharing', { 'HDL Code Generation' } )">hdlcoder_singlerate_sharing</a> for HDL code generation parameters.
### Running HDL checks on the model 'hdlcoder_singlerate_sharing'.
### Begin compilation of the model 'hdlcoder_singlerate_sharing'...
### Working on the model 'hdlcoder_singlerate_sharing'...
### The DUT requires an initial pipeline setup latency. Each output port experiences these additional delays.
### Output port 1: 1 cycles.
### Working on... <a href="matlab:configset.internal.open('hdlcoder_singlerate_sharing', 'GenerateModel')">GenerateModel</a>
### Begin model generation 'gm_hdlcoder_singlerate_sharing'...
### Rendering DUT with optimization related changes (IO, Area, Pipelining)...
### Model generation complete.
### Generated model saved at <a href="matlab:open_system('hdlsrc/hdlcoder_singlerate_sharing/gm_hdlcoder_singlerate_sharing.slx')">hdlsrc/hdlcoder_singlerate_sharing/gm_hdlcoder_singlerate_sharing.slx</a>
### To highlight blocks that obstruct distributed pipelining, click the following MATLAB script: <a href="matlab:run('hdlsrc/hdlcoder_singlerate_sharing/highlightDistributedPipeliningBarriers')">hdlsrc/hdlcoder_singlerate_sharing/highlightDistributedPipeliningBarriers.m</a>
### To clear highlighting, click the following MATLAB script: <a href="matlab:run('hdlsrc/hdlcoder_singlerate_sharing/clearhighlighting.m')">hdlsrc/hdlcoder_singlerate_sharing/clearhighlighting.m</a>
### Generating new validation model: '<a href="matlab:open_system('hdlsrc/hdlcoder_singlerate_sharing/gm_hdlcoder_singlerate_sharing_vnl')">gm_hdlcoder_singlerate_sharing_vnl</a>'.
### Validation model generation complete.
### Begin VHDL Code Generation for 'hdlcoder_singlerate_sharing'.
### MESSAGE: The design requires 30 times faster clock with respect to the base rate = 0.1.
### Begin VHDL Code Generation for 'Subsystem_tc'.
### Working on Subsystem_tc as hdlsrc/hdlcoder_singlerate_sharing/Subsystem_tc.vhd.
### Code Generation for 'Subsystem_tc' completed.
### Working on hdlcoder_singlerate_sharing/Subsystem/share as hdlsrc/hdlcoder_singlerate_sharing/share.vhd.
### Working on hdlcoder_singlerate_sharing/Subsystem/stream1 as hdlsrc/hdlcoder_singlerate_sharing/stream1.vhd.
### Working on hdlcoder_singlerate_sharing/Subsystem/stream2 as hdlsrc/hdlcoder_singlerate_sharing/stream2.vhd.
### Working on crp_temp_MAC as hdlsrc/hdlcoder_singlerate_sharing/crp_temp_MAC.vhd.
### Working on hdlcoder_singlerate_sharing/Subsystem as hdlsrc/hdlcoder_singlerate_sharing/Subsystem.vhd.
### Generating package file hdlsrc/hdlcoder_singlerate_sharing/Subsystem_pkg.vhd.
### Code Generation for 'hdlcoder_singlerate_sharing' completed.
### Generating HTML files for code generation report at <a href="matlab:hdlcoder.report.openReportV2Dialog('/tmp/Bdoc26a_3146167_3699846/tp6829dcca/hdlcoder-ex08973016/hdlsrc/hdlcoder_singlerate_sharing', '/tmp/Bdoc26a_3146167_3699846/tp6829dcca/hdlcoder-ex08973016/hdlsrc/hdlcoder_singlerate_sharing/html/index.html')">index.html</a>
### Creating HDL Code Generation Check Report file:///tmp/Bdoc26a_3146167_3699846/tp6829dcca/hdlcoder-ex08973016/hdlsrc/hdlcoder_singlerate_sharing/Subsystem_report.html
### HDL check for 'hdlcoder_singlerate_sharing' complete with 0 errors, 3 warnings, and 4 messages.
### HDL code generation complete.
生成された検証モデルのグローバルなレベルでは、HDL Coder は、これらの局所的に共有およびストリーミングされるサブシステムを、それぞれのレイテンシに応じてスケジュールします。スケジューリングの単位は、HDL Coder によって自動的に特定されてクロックレート パイプラインが適用された領域です。各領域で、スケジューリング ロジックのシーケンサーとして Counter Limited ブロックが使用されます。同一カウンターの生成を回避するために、HDL Coder は、同じサイズのカウンターを必要とするすべてのクロックレート パイプライン領域のモデルごとに 1 つのグローバル スケジューリング カウンターを生成します。カウンターはゼロから 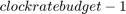 までカウントします。ここで、割り当ては、共有リソースのサンプル レートと FPGA クロック レートの比です。
までカウントします。ここで、割り当ては、共有リソースのサンプル レートと FPGA クロック レートの比です。
この例では、Oversampling プロパティは 30 であるため、割り当ては 30 です。HDL Coder は、ストリーミングおよび共有される各サブシステムの実行時間を時間間隔で割り当てます。その時間間隔の間だけアクティブになるように、サブシステムが Enabled サブシステム内にカプセル化されます。カウンターまたはシーケンサーの値で現在のタイム ステップを指定し、時間間隔を計算するロジックでそれらのサブシステムへのイネーブル入力を駆動します。
リソース共有またはストリーミングを指定する検証モデル内の各サブシステムについて、シングルレートのリソース共有アーキテクチャで時分割多重化が実装されます。たとえば、検証モデルのサブシステム gm_hdlcoder_singlerate_sharing_vnl/Subsystem/share を見てみます。SharingFactor = N の場合、共有アーキテクチャの実行に元の計算のサイクルで N-1 サイクルかかります。
検証モデルのサブシステム gm_hdlcoder_singlerate_sharing_vnl/Subsystem/share を開きます。
open_system('gm_hdlcoder_singlerate_sharing_vnl/Subsystem/share'); set_param('gm_hdlcoder_singlerate_sharing_vnl', 'SimulationCommand', 'update');

サブシステム gm_hdlcoder_singlerate_sharing_vnl/Subsystem/share には時間間隔 [2, 3] が割り当てられています。これは、Sum of Elements ブロック hdlcoder_singlerate_sharing/Subsystem/Sum_piped で HDL ブロック プロパティ [OutputPipeline] が 2 に設定されており、このブロックが DUT の入力とこのサブシステムへの入力の間のパスにあるためです。共有サブシステムはタイム ステップ 2 で実行を開始し、リソース共有プロパティ SharingFactor が 3 に設定されているため、完了までに 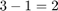 サイクルかかります。
サイクルかかります。gm_hdlcoder_singlerate_sharing_vnl/Subsystem/share/crp_temp_shared へのイネーブル入力は、グローバル カウンターが 2 以上で 3 以下のときにのみアサートされます。
HDL Coder は、ストリーミングおよび共有されるサブシステムに加え、状態をもつかマルチサイクルの演算を実装するブロックやサブシステムもスケジュールします。たとえば、設計で gm_hdlcoder_singlerate_sharing_vnl/Subsystem/crp_temp_MAC サブシステム内の Multiply-Accumulate ブロックが使用されています。このブロックは、2 つの 4 要素ベクトルのドット積を計算します。このロジックの実行には 4 サイクルかかり、時間間隔 [4, 7] でスケジュールされています。これは、入力から Multiply-Accumulate ブロックまでのパスに 2 つのストリーミング領域があるためです。最初のストリーミング領域 gm_hdlcoder_singlerate_sharing_vnl/Subsystem/stream1 は、ストリーミング係数が 2 であるため時間間隔 [0, 1] でスケジュールされています。2 番目のストリーミング領域 gm_hdlcoder_singlerate_sharing_vnl/Subsystem/stream2 は、ストリーミング係数が 4 であるため時間間隔 [1, 4] でスケジュールされています。
生成された検証モデルには元のモデルからの自明でない変更がありますが、HDL Coder が HDL コード用に合成して生成するシングルレートの共有アーキテクチャをモデル化しています。また、このモデルは、レイテンシの追加による違いを除いて、合成されたアーキテクチャの数値を元のモデルと比較します。詳細については、HDL Coder の遅延の均衡化と検証モデル ワークフローを参照してください。検証モデルを実行して、生成されたモデルと元のモデルの数値を各タイム ステップで比較します。不一致が見つかると、モデルからエラーがスローされます。