ディープ ネットワーク デザイナーへのデータのインポート
メモ
ディープ ネットワーク デザイナーを使用してデータをインポートし、ネットワークに学習させることは推奨されません。
ディープ ネットワーク デザイナーで学習データと検証データをインポートして可視化するには、従来の構文 deepNetworkDesigner("-v1") を使用します。
データのインポート
ディープ ネットワーク デザイナーでは、イメージ データストア、または各クラスからのイメージのサブフォルダーを含むフォルダーから、イメージ分類データをインポートできます。使用するデータストアのタイプに基づいてインポート方法を選択します。
ImageDatastore オブジェクトのインポート | その他のデータストア オブジェクトのインポート (ImageDatastore には非推奨) |
|---|---|
[データのインポート] 、 [イメージ分類データのインポート] を選択します。
| [データのインポート] 、 [カスタム データのインポート] を選択します。
|
データのタスク別のインポート
| タスク | データ型 | データのインポート方法 |
|---|---|---|
| イメージ分類 | クラスごとのイメージを含むサブフォルダーのあるフォルダー。クラス ラベルは、サブフォルダー名から取得されます。 | [データのインポート] 、 [イメージ分類データのインポート] を選択します。 |
たとえば、数字データを含むイメージ データストアを作成します。 unzip("DigitsData.zip"); dataFolder = "DigitsData"; imds = imageDatastore(dataFolder, ... IncludeSubfolders=true, ... LabelSource="foldernames"); | ||
たとえば、数字データを含む拡張されたイメージ データストアを作成します。 unzip("DigitsData.zip"); dataFolder = "DigitsData"; imds = imageDatastore(dataFolder, ... IncludeSubfolders=true, ... LabelSource="foldernames"); imageAugmenter = imageDataAugmenter( ... 'RandRotation',[1,2]); augimds = augmentedImageDatastore([28 28],imds, ... 'DataAugmentation',imageAugmenter); augimds = shuffle(augimds); | [データのインポート] 、 [カスタム データのインポート] を選択します。 | |
| セマンティック セグメンテーション | たとえば、 dataFolder = fullfile(toolboxdir('vision'), ... 'visiondata','triangleImages'); imageDir = fullfile(dataFolder,'trainingImages'); labelDir = fullfile(dataFolder,'trainingLabels'); imds = imageDatastore(imageDir); classNames = ["triangle","background"]; labelIDs = [255 0]; pxds = pixelLabelDatastore(labelDir,classNames,labelIDs); cds = combine(imds,pxds); | [データのインポート] 、 [カスタム データのインポート] を選択します。 |
| image-to-image 回帰 | たとえば、ノイズを含む入力イメージと初期状態の出力イメージを組み合わせて、image-to-image 回帰に適したデータを作成します。 unzip("DigitsData.zip"); dataFolder = "DigitsData"; imds = imageDatastore(dataFolder, ... IncludeSubfolders=true, ... LabelSource="foldernames"); imds = transform(imds,@(x) rescale(x)); imdsNoise = transform(imds,@(x) {imnoise(x,'Gaussian',0.2)}); cds = combine(imdsNoise,imds); cds = shuffle(cds); | [データのインポート] 、 [カスタム データのインポート] を選択します。 |
| 回帰 | 配列データストア オブジェクトを組み合わせて、回帰ネットワークの学習に適したデータを作成します。 [XTrain,~,YTrain] = digitTrain4DArrayData; ads = arrayDatastore(XTrain,'IterationDimension',4, ... 'OutputType','cell'); adsAngles = arrayDatastore(YTrain,'OutputType','cell'); cds = combine(ads,adsAngles); | [データのインポート] 、 [カスタム データのインポート] を選択します。 |
| シーケンスおよび時系列 | シーケンス データを予測子のデータストアから深層学習ネットワークに入力するには、シーケンスのミニバッチが同じ長さでなければなりません。関数 たとえば、すべてのシーケンスが最長のシーケンスと同じ長さになるようにシーケンスをパディングします。 [XTrain,YTrain] = japaneseVowelsTrainData;
XTrain = padsequences(XTrain,2);
adsXTrain = arrayDatastore(XTrain,'IterationDimension',3);
adsYTrain = arrayDatastore(YTrain);
cdsTrain = combine(adsXTrain,adsYTrain);パディングの量を減らすには、変換されたデータストアと補助関数を使用します。たとえば、ミニバッチのすべてのシーケンスがそのミニバッチにある最長のシーケンスと同じ長さになるようにシーケンスをパディングします。また、学習オプションでは同じミニバッチ サイズを使用しなければなりません。 [XTrain,TTrain] = japaneseVowelsTrainData; miniBatchSize = 27; adsXTrain = arrayDatastore(XTrain,'OutputType',"same",'ReadSize',miniBatchSize); adsTTrain = arrayDatastore(TTrain,'ReadSize',miniBatchSize); tdsXTrain = transform(adsXTrain,@padToLongest); cdsTrain = combine(tdsXTrain,adsTTrain); function data = padToLongest(data) sequence = padsequences(data,2,Direction="left"); for n = 1:numel(data) data{n} = sequence(:,:,n); end end データを短い順に並べ替えてパディングの量を減らしたり、パディングの向きを指定してパディングの影響を減らしたりすることもできます。シーケンス データのパディングの詳細については、シーケンスのパディングと切り捨てを参照してください。 カスタム データストア オブジェクトを使用してシーケンス データをインポートすることもできます。カスタム シーケンス データストアを作成する方法を示す例については、シーケンス データのカスタム ミニバッチ データストアを使用したネットワークの学習を参照してください。 | [データのインポート] 、 [カスタム データのインポート] を選択します。 |
| その他の拡張ワークフロー (数値特徴入力、メモリ外のデータ、イメージ処理、オーディオ処理および音声処理など) | データストア その他の拡張ワークフローでは、適切なデータストア オブジェクトを使用してください。たとえば、カスタム データストア、 たとえば、Image Processing Toolbox™ を使用して、 dataFolder = fullfile(toolboxdir('images'),'imdata'); imds = imageDatastore(dataFolder,'FileExtensions',{'.jpg'}); dnds = denoisingImageDatastore(imds,... 'PatchesPerImage',512,... 'PatchSize',50,... 'GaussianNoiseLevel',[0.01 0.1]); table 配列データの場合、ディープ ネットワーク デザイナーを使用して学習させるには、データを適切なデータストアに変換しなければなりません。たとえば、最初に予測子と応答を含む配列に table を変換します。次に、この配列を | [データのインポート] 、 [カスタム データのインポート] を選択します。 |
イメージ拡張
イメージ分類問題について、ディープ ネットワーク デザイナーは、学習データに適用する単純な拡張オプションを提供しています。[データのインポート] 、 [イメージ分類データのインポート] を選択して、[イメージ分類データのインポート] ダイアログ ボックスを開きます。反射、回転、再スケーリング、平行移動といった操作のランダムな組み合わせを学習データに適用するオプションを選択できます。
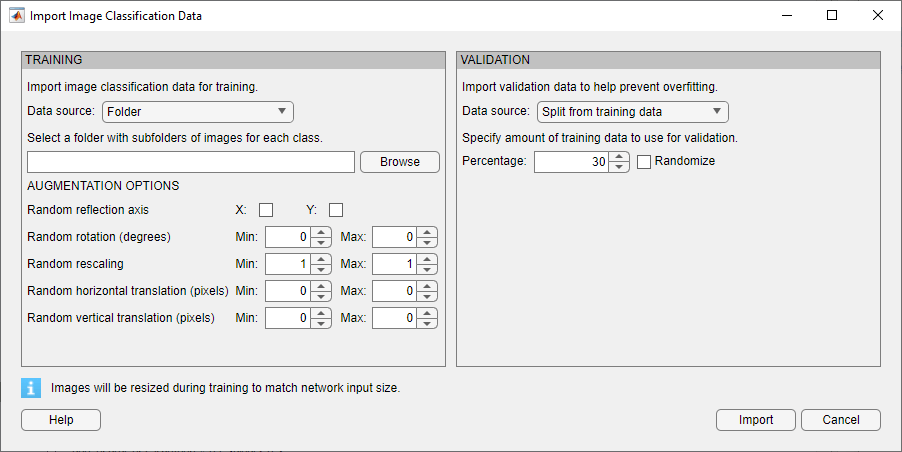
ディープ ネットワーク デザイナーが提供するイメージ前処理演算より一般的で複雑なイメージ前処理演算を実行するには、TransformedDatastore オブジェクトおよび CombinedDatastore オブジェクトを使用します。CombinedDatastore オブジェクトおよび TransformedDatastore オブジェクトをインポートするには、[データのインポート] 、 [カスタム データのインポート] を選択します。
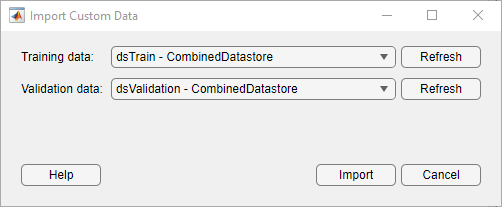
イメージ拡張の詳細については、イメージの深層学習向け前処理を参照してください。
検証データ
ディープ ネットワーク デザイナーでは、使用する検証データを学習中にインポートできます。損失や精度などの検証メトリクスを監視して、ネットワークが過適合または適合不足かどうかを評価し、必要に応じて学習オプションを調整できます。たとえば、検証損失が学習損失をはるかに上回っている場合、ネットワークは過適合している可能性があります。
ディープ ネットワーク デザイナーでは、次のように検証データをインポートできます。
ワークスペース内のデータストアから。
クラスごとのイメージのサブフォルダーを含むフォルダーから (イメージ分類データのみ)。
検証データとして使用する学習データの一部を分割することによって (イメージ分類データのみ)。学習を行う前に、一度、データを検証セットと学習セットに分割します。この手法はホールドアウト検証と呼ばれます。
検証データの学習データからの分割
学習データからホールドアウト検証データを分割する際、ディープ ネットワーク デザイナーは、各クラスから一定の割合の学習データを分割します。たとえば、cat と dog という 2 つのクラスをもつデータ セットがあり、検証用に学習データの 30% を使用することを選択したとします。ディープ ネットワーク デザイナーは、ラベル "cat" をもつイメージの最後の 30% とラベル "dog" をもつイメージの最後の 30% を検証セットとして使用します。
学習データの最後の 30% を検証データとして使用するのではなく、学習セットと検証セットに観測値をランダムに割り当てるという選択もできます。その場合、[イメージ データのインポート] ダイアログ ボックスの [ランダム化] チェック ボックスをオンにします。イメージをランダム化することで、非ランダムな順序で保存されたデータで学習したネットワークの精度を向上させることができます。たとえば、数字データ セットは、手書き数字の合成グレースケール イメージ 10,000 個で構成されています。このデータ セットには、同じスタイルの手書きイメージは各クラス内で隣り合うという、基となる順序があります。表示例を示します。

参考
ディープ ネットワーク デザイナー | TransformedDatastore | CombinedDatastore | imageDatastore | augmentedImageDatastore | splitEachLabel