深層学習用のデータセット
これらのデータセットを使用して、深層学習の応用を開始します。
メモ
これらのデータ セットの説明で使用されているコードの中には、サポート ファイルとして例に添付されている関数を使用しているものがあります。これらの関数を使用するには、例をライブ スクリプトとして開きます。
イメージ データセット
| データ セット | 説明 | タスク |
|---|---|---|
数字
| 数字データ セットは、10,000 個の手書き数字の合成グレースケール イメージで構成されています。各イメージは 28 x 28 ピクセルで、イメージが表す数字 (0 ~ 9) を示すラベルが関連付けられています。各イメージには特定な角度の回転が付けられています。イメージを配列として読み込むと、そのイメージの回転角度も読み込まれます。 関数 [XTrain,YTrain,anglesTrain] = digitTrain4DArrayData; [XTest,YTest,anglesTest] = digitTest4DArrayData; このデータを深層学習用に処理する方法を示す例については、深層学習における学習の進行状況の監視および回帰用の畳み込みニューラル ネットワークの学習を参照してください。 | イメージ分類とイメージ回帰 |
関数 unzip("DigitsData.zip"); dataFolder = "DigitsData"; imds = imageDatastore(dataFolder, ... IncludeSubfolders=true, ... LabelSource="foldernames"); このデータを深層学習用に処理する方法を示す例については、分類用のシンプルな深層学習ニューラル ネットワークの作成を参照してください。 | イメージ分類 | |
Omniglot
| Omniglot データ セットには 50 個のアルファベットの文字セットが含まれていて、そのうち 30 セットが学習用に、20 セットがテスト用に分けられています[1]。それぞれのアルファベットには、Ojibwe (カナダ先住民文字) の 14 個の文字から Tifinagh の 55 個の文字まで、数多くの文字が含まれています。そして、それぞれの文字には 20 個の手書きの観測値があります。 https://github.com/brendenlake/omniglotから Omniglot データ セットをダウンロードして解凍します。 downloadFolder = tempdir; url = "https://github.com/brendenlake/omniglot/raw/master/python"; urlTrain = url + "/images_background.zip"; urlTest = url + "/images_evaluation.zip"; filenameTrain = fullfile(downloadFolder,"images_background.zip"); filenameTest = fullfile(downloadFolder,"images_evaluation.zip"); dataFolderTrain = fullfile(downloadFolder,"images_background"); dataFolderTest = fullfile(downloadFolder,"images_evaluation"); if ~exist(dataFolderTrain,"dir") fprintf("Downloading Omniglot training data set (4.5 MB)... ") websave(filenameTrain,urlTrain); unzip(filenameTrain,downloadFolder); fprintf("Done.\n") end if ~exist(dataFolderTest,"dir") fprintf("Downloading Omniglot test data (3.2 MB)... ") websave(filenameTest,urlTest); unzip(filenameTest,downloadFolder); fprintf("Done.\n") end 学習データとテスト データをイメージ データストアとして読み込むには、関数 imdsTrain = imageDatastore(dataFolderTrain, ... 'IncludeSubfolders',true, ... 'LabelSource','none'); files = imdsTrain.Files; parts = split(files,filesep); labels = join(parts(:,(end-2):(end-1)),'_'); imdsTrain.Labels = categorical(labels); imdsTest = imageDatastore(dataFolderTest, ... 'IncludeSubfolders',true, ... 'LabelSource','none'); files = imdsTest.Files; parts = split(files,filesep); labels = join(parts(:,(end-2):(end-1)),'_'); imdsTest.Labels = categorical(labels); このデータを深層学習用に処理する方法を示す例については、Train a Twin Neural Network to Compare Imagesを参照してください。 | イメージ類似度 |
花
| Flowers データ セットには、5 つのクラス ("デイジー"、"タンポポ"、"バラ"、"ヒマワリ"、および "チューリップ") に属する 3670 個の花のイメージが含まれています[2]。 http://download.tensorflow.org/example_images/flower_photos.tgzから Flowers データ セットをダウンロードして解凍します。このデータセットは約 218 MB です。 url = 'http://download.tensorflow.org/example_images/flower_photos.tgz'; downloadFolder = tempdir; filename = fullfile(downloadFolder,'flower_dataset.tgz'); dataFolder = fullfile(downloadFolder,'flower_photos'); if ~exist(dataFolder,'dir') fprintf("Downloading Flowers data set (218 MB)... ") websave(filename,url); untar(filename,downloadFolder) fprintf("Done.\n") end 関数 imds = imageDatastore(dataFolder, ... 'IncludeSubfolders',true, ... 'LabelSource','foldernames'); このデータを深層学習用に処理する方法を示す例については、敵対的生成ネットワーク (GAN) の学習を参照してください。 | イメージ分類 |
食品イメージのサンプル
| 食品イメージのサンプル データ セットには、9 つのクラス ("シーザー サラダ"、"カプレーゼ サラダ"、"フライド ポテト"、"グリーク サラダ"、"ハンバーガー"、"ホット ドッグ"、"ピザ"、"刺身"、および "寿司") に属する 978 個の写真が含まれています。 関数 fprintf("Downloading Example Food Image data set (77 MB)... ") filename = matlab.internal.examples.downloadSupportFile('nnet', ... 'data/ExampleFoodImageDataset.zip'); fprintf("Done.\n") filepath = fileparts(filename); dataFolder = fullfile(filepath,'ExampleFoodImageDataset'); unzip(filename,dataFolder); このデータを深層学習用に処理する方法を示す例については、tsne を使用したネットワークの動作の表示を参照してください。 | イメージ分類 |
CIFAR-10
(典型例) | CIFAR-10 データ セットには、10 個のクラス ("飛行機"、"自動車"、"鳥"、"猫"、"鹿"、"犬"、"蛙"、"馬"、"船"、および "トラック") に属する 32 x 32 ピクセルのカラー イメージが 60,000 個含まれています[7]。1 つのクラスにつき 6,000 個のイメージがあります。 このデータ セットは、50,000 個のイメージから成る学習セットと 10,000 個のイメージから成るテスト セットに分かれています。このデータセットは、新しいイメージ分類モデルのテストに最も広く使用されているデータセットのひとつです。 https://www.cs.toronto.edu/%7Ekriz/cifar-10-matlab.tar.gzから CIFAR-10 データ セットをダウンロードして解凍します。このデータセットは約 175 MB です。 url = 'https://www.cs.toronto.edu/~kriz/cifar-10-matlab.tar.gz'; downloadFolder = tempdir; filename = fullfile(downloadFolder,'cifar-10-matlab.tar.gz'); dataFolder = fullfile(downloadFolder,'cifar-10-batches-mat'); if ~exist(dataFolder,'dir') disp("Downloading CIFAR-10 dataset (175 MB)... "); websave(filename,url); untar(filename,downloadFolder); disp("Done.") end loadCIFARData を使用して、このデータを数値配列に変換します。この関数にアクセスするには、例をライブ スクリプトとして開きます。[XTrain,YTrain,XValidation,YValidation] = loadCIFARData(downloadFolder); このデータを深層学習用に処理する方法を示す例については、イメージ分類用の残差ネットワークの学習を参照してください。 | イメージ分類 |
MathWorks® Merch
| MathWorks Merch データ セットは、75 個の MathWorks の商品イメージから成る小さなデータ セットであり、5 つの異なるクラス ("帽子"、"立方体"、"トランプ"、"ドライバー"、および "トーチ") に属します。このデータセットを使用して転移学習やイメージ分類を素早く試すことができます。 イメージのサイズは 227 x 227 x 3 です。 MathWorks Merch データセットを解凍します。 filename = 'MerchData.zip'; dataFolder = fullfile(tempdir,'MerchData'); if ~exist(dataFolder,'dir') unzip(filename,tempdir); end 関数 imds = imageDatastore(dataFolder, ... 'IncludeSubfolders',true,'LabelSource','foldernames'); このデータを深層学習用に処理する方法を示す例については、転移学習入門および新しいイメージを分類するためのニューラル ネットワークの再学習を参照してください。 | イメージ分類 |
CamVid
| CamVid データ セットは、運転中の車両から得られた路上レベルのビューが含まれるイメージ コレクションです[8]。データセットは、イメージのセマンティック セグメンテーションを行うネットワークの学習に役立ちます。また、"車"、"歩行者"、"道路" を含む 32 個のセマンティック クラスについてピクセルレベルのラベルを提供します。 イメージのサイズは 720 x 960 x 3 です。 http://web4.cs.ucl.ac.uk/staff/g.brostow/MotionSegRecData/から CamVid データ セットをダウンロードして解凍します。このデータセットは約 573 MB です。 downloadFolder = tempdir; url = "http://web4.cs.ucl.ac.uk/staff/g.brostow/MotionSegRecData" urlImages = url + "/files/701_StillsRaw_full.zip"; urlLabels = url + "/data/LabeledApproved_full.zip"; dataFolder = fullfile(downloadFolder,"CamVid"); dataFolderImages = fullfile(dataFolder,"images"); dataFolderLabels = fullfile(dataFolder,"labels"); filenameLabels = fullfile(dataFolder,"labels.zip"); filenameImages = fullfile(dataFolder,"images.zip"); if ~exist(filenameLabels,"file") || ~exist(imagesZip,"file") mkdir(dataFolder) disp("Downloading CamVid data set images (557 MB)... "); websave(filenameImages, urlImages); unzip(filenameImages,dataFolderImages); disp("Done.") disp("Downloading CamVid data set labels (16 MB)... "); websave(filenameLabels,urlLabels); unzip(filenameLabels,dataFolderLabels); disp("Done.") end 関数 imds = imageDatastore(dataFolderImages,"IncludeSubfolders",true); classes = ["Sky" "Building" "Pole" "Road" "Pavement" "Tree" ... "SignSymbol" "Fence" "Car" "Pedestrian" "Bicyclist"]; labelIDs = camvidPixelLabelIDs; pxds = pixelLabelDatastore(dataFolderLabels,classes,labelIDs); このデータを深層学習用に処理する方法を示す例については、深層学習を使用したセマンティック セグメンテーション (Computer Vision Toolbox)を参照してください。 | セマンティック セグメンテーション |
車両
| 車両データセットは、1 個または 2 個のラベル付けされた車両インスタンスを含む 295 個のイメージで構成されています。この小さなデータ セットは YOLO の学習手順を調べるうえで役立ちますが、実際にロバストな検出器に学習させるにはラベル付けされたイメージがより多く必要になります。 イメージのサイズは 720 x 960 x 3 です。 車両データセットを解凍します。 filename = "vehicleDatasetImages.zip"; dataFolder = fullfile(tempdir,"vehicleImages"); if ~exist(dataFolder,"dir") unzip(filename,tempdir); end 解凍した MAT ファイルから、ファイル名と境界ボックスの table としてデータ セットを読み込み、ファイル名を絶対ファイル パスに変換します。 data = load("vehicleDatasetGroundTruth.mat");
vehicleDataset = data.vehicleDataset;
vehicleDataset.imageFilename = fullfile(tempdir,vehicleDataset.imageFilename);関数 filenamesImages = vehicleDataset.imageFilename;
tblBoxes = vehicleDataset(:,"vehicle");
imds = imageDatastore(filenamesImages);
blds = boxLabelDatastore(tblBoxes);
cds = combine(imds,blds);このデータを深層学習用に処理する方法を示す例については、YOLO v4 深層学習を使用したオブジェクトの検出 (Computer Vision Toolbox)を参照してください。 | オブジェクトの検出 |
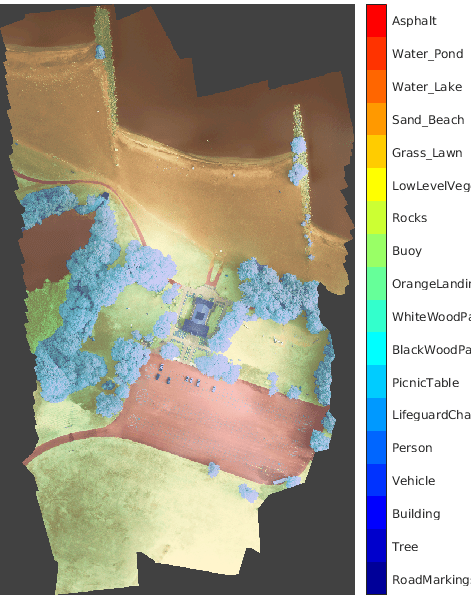
RIT-18
| RIT-18 データ セットには、ニューヨーク州にあるハムリン ビーチ州立公園の上空をドローンで撮影したイメージ データが含まれています[9]。このデータには、18 個のオブジェクト クラス ラベル ("路面標示"、"樹木"、"ビル" など) の付いた、ラベル付き学習セット、検証セットおよびテスト セットが含まれます。このデータセットは約 3 GB です。 https://home.cis.rit.edu/~cnspci/other/data/rit18_data.matから RIT-18 データ セットをダウンロードします。 downloadFolder = tempdir; url = "https://home.cis.rit.edu/~cnspci/other/data/rit18_data.mat"; filename = fullfile(downloadFolder,"rit18_data.mat"); if ~exist(filename,"file") disp("Downloading Hamlin Beach data set (3 GB)... "); websave(filename,url); disp("Done.") end このデータを深層学習用に処理する方法を示す例については、深層学習を使用したマルチスペクトル イメージのセマンティック セグメンテーション (Image Processing Toolbox)を参照してください。 | セマンティック セグメンテーション |
BraTS
| BraTS データ セットには、脳腫瘍、すなわち最も一般的な原発性悪性脳腫瘍である神経膠腫の MRI スキャンが格納されています[10]。 データ セットには 750 個の 4 次元ボリュームが格納されており、それぞれが 3 次元イメージのスタックを表します。各 4 次元ボリュームのサイズは 240 x 240 x 155 x 4 であり、最初の 3 つの次元は 3 次元ボリューム イメージの高さ、幅、奥行に対応します。4 番目の次元は異なるスキャン モダリティに対応します。このデータ セットは、ボクセル ラベルを含む 484 個の学習ボリュームと 266 個のテスト ボリュームに分割されています。このデータセットは約 7 GB です。 BraTS データセットを格納するディレクトリを作成します。 dataFolder = fullfile(tempdir,"BraTS"); if ~exist(dataFolder,"dir") mkdir(dataFolder); end Medical Segmentation Decathlon で [Download Data] リンクをクリックして BraTS データをダウンロードします。"Task01_BrainTumour.tar" ファイルをダウンロードします。 変数 このデータを深層学習用に処理する方法を示す例については、深層学習を使用した脳腫瘍の 3 次元セグメンテーション (Image Processing Toolbox)を参照してください。 | セマンティック セグメンテーション |
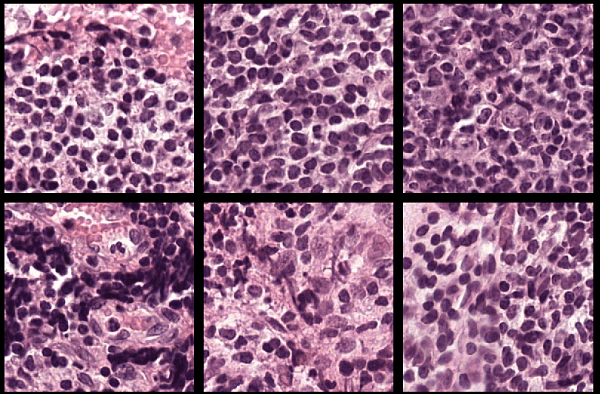
Camelyon16
| Camelyon16 チャレンジのデータには、2 つの独立したソースによるリンパ節ノードのスライド ガラス標本全体のイメージ (WSI) が合計 400 個含まれており、270 個の学習イメージと 130 個のテスト イメージに分かれています[11]。データ セットのサイズは約 451 GB です。 学習データセットは、正常なリンパ節ノードの 159 個の WSI と、腫瘍組織と正常組織を含むリンパ節ノードの 111 個の WSI で構成されています。通常、腫瘍組織の割合は正常組織に比べるとごくわずかです。腫瘍イメージには病変境界のグラウンド トゥルース座標が付属しています。 Camelyon16 学習データ セットを格納するフォルダーをローカル マシンに作成します。 dataDir = fullfile(tempdir,"Camelyon16","training"); trainNormalDir = fullfile(dataDir,"normal"); trainTumorDir = fullfile(dataDir,"tumor"); trainAnnotationDir = fullfile(dataDir,"lesion_annotations"); if ~exist(dataDir,"dir") mkdir(dataDir); mkdir(trainNormalDir); mkdir(trainTumorDir); mkdir(trainAnnotationDir); end データをダウンロードするには、データ セットの GigaDB Web サイトにアクセスし、テーブルで [ファイル] タブに移動します。[ファイル名] 列の名前をクリックして個々のファイルをダウンロードし、次の手順に従ってそれらのファイルを適切なサブフォルダーに移動します。
このデータを深層学習用に処理する方法を示す例については、Preprocess Multiresolution Images for Training Classification Network (Image Processing Toolbox)を参照してください。 | イメージ分類 (大きなイメージ) |
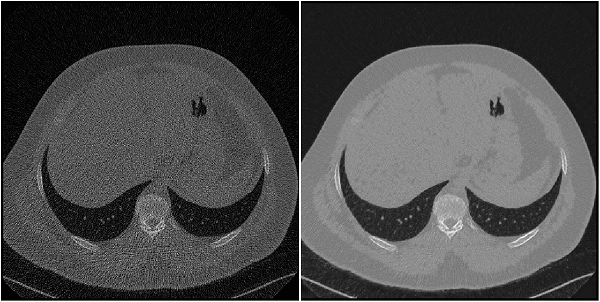
低線量 CT グランド チャレンジ
| 低線量 CT グランド チャレンジには、99 個の頭部スキャン (神経 (neuro) を意味する N のラベルが付いている)、100 個の胸部スキャン (胸部 (chest) を意味する C のラベルが付いている)、および 100 個の腹部スキャン (肝臓 (liver) を意味する L のラベルが付いている) について、通常線量 CT イメージおよびシミュレーションされた低線量 CT イメージのペアが含まれています[12][13]。このデータ セットは全体で約 1.2 TB です。 低線量 CT グランド チャレンジ データ セットの胸部ファイルを格納するディレクトリを作成します。
dataDir = fullfile(tempdir,"LDCT","LDCT-and-Projection-data"); if ~exist(dataDir,"dir") mkdir(dataDir); end データをダウンロードするには、The Cancer Imaging Archive の Web サイトに移動します。NBIA Data Retriever を使用して、"Images (DICOM, 952 GB)" データ セットの胸部ファイルをダウンロードします。データのダウンロード先の場所として、変数 このデータを深層学習用に処理する方法を示す例については、Unsupervised Medical Image Denoising Using CycleGAN (Image Processing Toolbox)を参照してください。 | image-to-image 回帰 |
Common Objects in Context (COCO)
(典型例) | COCO 2014 学習イメージ データセットは、82,783 個のイメージで構成されています。注釈データには、各イメージごとに最低 5 つの対応するキャプションが格納されています。 COCO データ セットを格納するディレクトリを作成します。 dataFolder = fullfile(tempdir,"coco"); if ~exist(dataFolder,"dir") mkdir(dataFolder); end https://cocodataset.org/#downloadで [2014 Train images] と [2014 Train/Val annotations] のリンクをクリックし、COCO 2014 の学習イメージとキャプションをそれぞれダウンロードして解凍します。 関数 filename = fullfile(dataFolder,"annotations_trainval2014","annotations", ... "captions_train2014.json"); str = fileread(filename); data = jsondecode(str); 構造体の このデータを深層学習用に処理する方法を示す例については、attention を使用したイメージ キャプションの生成を参照してください。 | イメージ キャプションの生成 |
IAPR TC-12
(典型例) | IAPR TC-12 ベンチマークは 20,000 個の静止した自然イメージで構成されています[14]。このデータ セットには、人物、動物、都市などの写真が含まれます。このデータ ファイルは約 1.8 GB です。 IAPR TC-12 データ セットをダウンロードします。 dataDir = fullfile(tempdir,"iaprtc12"); url = "https://www-i6.informatik.rwth-aachen.de/imageclef/resources/iaprtc12.tgz"; if ~exist(dataDir,"dir") disp("Downloading IAPR TC-12 data set (1.8 GB)..."); try untar(url,dataDir); catch % On some Windows machines, the untar command throws an error for .tgz % files. Rename to .tg and try again. fileName = fullfile(tempdir,"iaprtc12.tg"); websave(fileName,url); untar(fileName,dataDir); end disp("Done."); end 関数 imageDir = fullfile(dataDir,"images") exts = {".jpg",".bmp",".png"}; imds = imageDatastore(imageDir, ... "IncludeSubfolders",true,"FileExtensions",exts); このデータを深層学習用に処理する方法を示す例については、深層学習を使用したイメージの高解像度化 (Image Processing Toolbox)を参照してください。 | image-to-image 回帰 |
Zurich RAW to RGB
| Zurich RAW to RGB データ セットには、サイズが 448 x 448 の、空間的にレジストレーションされた RAW 学習イメージ パッチおよび RGB 学習イメージ パッチが 48,043 ペア登録されています[15]。このデータ セットには 2 つの異なるテスト セットが格納されています。一方のテスト セットは、サイズが 448 x 448 の、空間的にレジストレーションされた RAW イメージ パッチおよび RGB イメージ パッチ 1,204 ペアで構成されています。もう一方のテスト セットはレジストレーションされていないフル解像度 RAW イメージおよび RGB イメージで構成されています。このデータ セットは 22 GB です。 Zurich RAW to RGB データ セットを格納するディレクトリを作成します。 dataDir = fullfile(tempdir,"ZurichRAWToRGB");dataDir で指定されたディレクトリにデータを解凍します。解凍に成功すると、full_resolution、test、および train という 3 つのディレクトリが dataDir に作成されます。このデータを深層学習用に処理する方法を示す例については、深層学習を使用したカメラのデータ処理パイプラインの構築 (Image Processing Toolbox)を参照してください。 | image-to-image 回帰 |
See-In-The-Dark (SID)
| See-In-The-Dark (SID) データ セットには、レジストレーションされた同じシーンの RAW イメージのペアが用意されています[16]。各ペアは、露光時間が短く露光不足のイメージと、露光時間が長く露光が適切なイメージで構成されています。SID データ セットの Sony カメラ データのサイズは 25 GB です。
dataDir = fullfile(tempdir,"SID"); if ~exist(dataDir,"dir") mkdir(dataDir); end このデータ セットをダウンロードするには、https://storage.googleapis.com/isl-datasets/SID/Sony2025.zipのリンクに移動します。変数 このデータ セットには、学習用、検証用、およびテスト用のデータ セットにファイルを分割する方法が記述されたテキスト ファイルも用意されています。ファイル "Sony_train_list.txt"、"Sony_val_list.txt"、および "Sony_test_list.txt" を、変数 このデータを深層学習用に処理する方法を示す例については、Brighten Extremely Dark Images Using Deep Learning (Image Processing Toolbox)を参照してください。 | image-to-image 回帰 |
LIVE In the Wild
| LIVE In the Wild データ セットは、モバイル デバイスで撮影された 1,162 個の写真、および 7 個の追加の学習イメージで構成されています[17]。各イメージは、平均 175 人によって [1, 100] のスケールで評価されています。このデータ セットには、各イメージに対する主観的なスコアの平均値と標準偏差が格納されています。
imageDir = fullfile(tempdir,"LIVEInTheWild"); if ~exist(imageDir,"dir") mkdir(imageDir); end LIVE In the Wild Image Quality Challenge Database の説明に従って、データ セットをダウンロードします。変数 このデータを深層学習用に処理する方法を示す例については、Quantify Image Quality Using Neural Image Assessment (Image Processing Toolbox)を参照してください。 | イメージ分類 |
分類用のコンクリート亀裂イメージ
| 分類用のコンクリート亀裂イメージ データ セットは、次の 2 つのクラスで構成されます。路面に亀裂がない "Negative" イメージ、および路面に亀裂がある "Positive" イメージ[18][19]。このデータ セットには、クラスごとに 20,000 個のイメージが用意されています。データ セットのサイズは約 230 MB です。
dataDir = fullfile(tempdir,"ConcreteCracks"); if ~exist(dataDir,"dir") mkdir(dataDir); end データ セットをダウンロードするには、次のリンクに移動します。Concrete Crack Images for Classification。ダウンロードした ZIP ファイルを解凍して RAR ファイルを取得し、 このデータを深層学習用に処理する方法を示す例については、Detect Image Anomalies Using Pretrained ResNet-18 Feature Embeddings (Computer Vision Toolbox)を参照してください。 | イメージ分類 |
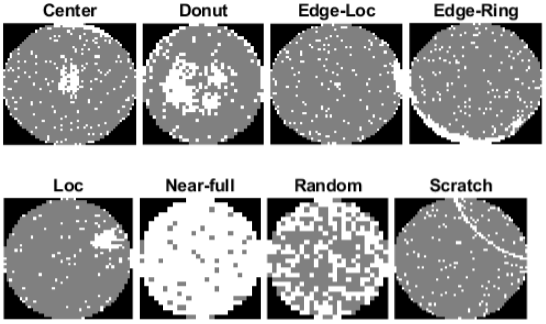
MIR WM-811K (ウェハー欠陥マップ)
| ウェハー欠陥マップ データ セットは、811,457 個のウェハー マップのイメージで構成され、そのうち 172,950 個のイメージにラベルが付けられています[20] [21]。各イメージのピクセル値は 3 つのみです。値 0 は背景を、値 1 は正しく動作するダイを、値 2 は欠陥があるダイをそれぞれ表します。ラベル付けされたイメージには、欠陥の空間パターンに応じて 9 つのラベルのいずれかが付けられています。このデータ セットのサイズは 3.5 GB です。
dataDir = fullfile(tempdir,"WaferDefects"); dataURL = "http://mirlab.org/dataSet/public/MIR-WM811K.zip"; dataMatFile = fullfile(dataDir,"MIR-WM811K","MATLAB","WM811K.mat"); if exist(dataMatFile,"file") ~= 2 unzip(dataURL,dataDir); end このデータは、構造体の配列として MAT ファイルに保存されています。データセットをワークスペースに読み込みます。 waferData = load(dataMatFile); waferData = waferData.data; このデータを深層学習用に処理する方法を示す例については、Classify Defects on Wafer Maps Using Deep Learning (Computer Vision Toolbox)を参照してください。 | イメージ分類 |
PCB 欠陥
| プリント基板 (PCB) 欠陥データ セットには、合成された欠陥をもつ PCB 素子に関する 1,386 個のイメージが格納されています[22] [23]。このデータには、6 種類の欠陥 (ホール欠損、欠け、断線、短絡、突起、残銅) が含まれています。各イメージでは、同じカテゴリに属する複数の欠陥がそれぞれ異なる場所に配置されています。このデータ セットでは、各イメージの各欠陥に関する境界ボックスと座標情報が用意されています。このデータ セットのサイズは 1.87 GB です。
dataDir = fullfile(tempdir,"PCBDefects"); imageDir = fullfile(dataDir,"PCB-DATASET-master"); if ~exist(imageDir,"dir") dataURL = "https://github.com/Ironbrotherstyle/PCB-DATASET/archive/refs/heads/master.zip"; unzip(dataURL,dataDir); delete(fullfile(imageDir,"*.m"),fullfile(imageDir,"*.mlx"), ... fullfile(imageDir,"*.mat"),fullfile(imageDir,"*.md")); end このデータを深層学習用に処理する方法を示す例については、YOLOX ネットワークを使用したプリント基板の欠陥の検出 (Computer Vision Toolbox)を参照してください。 | オブジェクトの検出 |
視覚的異常 (VisA)
| 視覚的異常 (VisA) データ セットは、3 つの分野の 12 の異なるオブジェクト サブセットをカバーする 10,821 個の高解像度カラー イメージ (9,621 個の正常サンプルと 1,200 個の異常サンプル) で構成されています[24][25]。サブセットのうち 4 つは、トランジスタ、コンデンサ、チップ、その他のコンポーネントを含む 4 つの異なるタイプの PCB に対応します。テスト セット内の異常なイメージには、さまざまな表面欠陥 (傷、へこみ、色の斑点、亀裂など) や構造的欠陥 (部品の誤配置や部品の欠落など) が含まれています。データ セットには欠陥タイプごとに 5 ~ 20 個のイメージが含まれており、一部のイメージには複数の欠陥が含まれています。 深層学習用に 4 つの PCB データ サブセットの 1 つをダウンロードします。このデータ サブセットには、
imageDir = fullfile(tempdir,"VisA"); if ~exist(imageDir,"dir") dataURL = "https://ssd.mathworks.com/supportfiles/vision/data/VisA.zip"; unzip(dataURL,dataDir); delete(fullfile(imageDir,"*.m"),fullfile(imageDir,"*.mlx"), ... fullfile(imageDir,"*.mat"),fullfile(imageDir,"*.md")); end このデータを深層学習用に処理する方法を示す例については、Localize Industrial Defects Using PatchCore Anomaly Detector (Computer Vision Toolbox)を参照してください。 | イメージ分類 |
錠剤品質管理 (錠剤 QC)
| 錠剤 QC データ セットは、3 つのクラスのイメージ、すなわち、欠陥がない "正常" イメージ、錠剤に欠けがある "欠け" イメージ、錠剤に汚れがある "汚れ" イメージで構成されています。このデータ セットには、149 個の正常イメージ、43 個の欠けイメージ、138 個の汚れイメージが含まれています。このデータ セットのサイズは 3.57 MB です。
dataDir = fullfile(tempdir,"PillDefects"); imageDir = fullfile(dataDir,"pillQC-main"); if ~exist(imageDir,"dir") unzip("https://github.com/matlab-deep-learning/pillQC/archive/refs/heads/main.zip",dataDir); end 関数 imageDir = fullfile(dataDir,"pillQC-main","images"); imds = imageDatastore(imageDir,IncludeSubfolders=true,LabelSource="foldernames"); このデータを深層学習用に処理する方法を示す例については、説明可能 FCDD ネットワークを使用したイメージ異常の検出 (Computer Vision Toolbox)を参照してください。 | イメージ分類 |
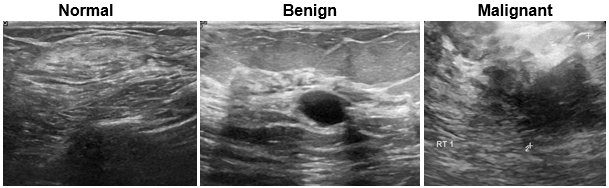
乳房超音波画像 (BUSI)
| 乳房超音波画像 (BUSI) データ セットには、2 次元の乳房超音波画像が含まれています[26]。このデータ セットには、133 個の正常なイメージ、良性腫瘍がある 487 個のイメージ、悪性腫瘍がある 210 個のイメージが含まれています。各超音波画像には、セマンティック セグメンテーション ネットワークに学習させるため、対応する腫瘍マスク イメージが用意されています。腫瘍マスクのラベルは、臨床放射線技師によってレビューされています。データ セットのサイズは約 197 MB です。 MathWorks の Web サイトから BUSI データ セットをダウンロードします。 zipFile = matlab.internal.examples.downloadSupportFile("image","data/Dataset_BUSI.zip"); filepath = fileparts(zipFile); unzip(zipFile,filepath) 関数 imageDir = fullfile(filepath,"Dataset_BUSI_with_GT"); imds = imageDatastore(imageDir,IncludeSubfolders=true,LabelSource="foldernames"); このデータを深層学習用に処理する方法を示す例については、Breast Tumor Segmentation from Ultrasound Using Deep Learning (Medical Imaging Toolbox)を参照してください。 | セマンティック セグメンテーション |
Child and Adolescent NeuroDevelopment Initiative (CANDI) 神経画像データ セット
| CANDI データ セット (サブセット HC_001) には、脳の MRI イメージ ボリューム、およびそれに対応するセグメンテーション ラベル イメージが含まれています[27]。データ セットの合計サイズは約 2.5 MB です。 MathWorks の Web サイトから CANDI データ セットをダウンロードします。 zipFile = matlab.internal.examples.downloadSupportFile("image","data/brainSegData.zip"); filepath = fileparts(zipFile); unzip(zipFile,filepath) dataDir = fullfile(filepath,"brainSegData"); このデータを深層学習用に読み込んで処理する方法を示す例については、Brain MRI Segmentation Using Pretrained 3-D U-Net Network (Medical Imaging Toolbox)を参照してください。 | セマンティック セグメンテーション |
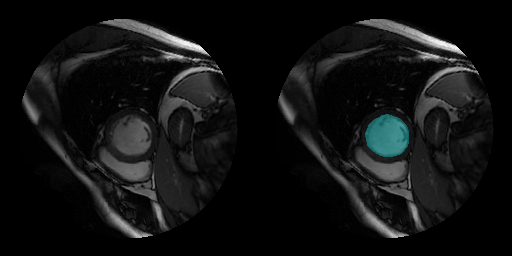
Sunnybrook Cardiac データ セット
| Sunnybrook Cardiac データ セットには、左心室のシネ MRI イメージとグラウンド トゥルース ラベルが含まれています[28]。このデータ セットには、複数の患者のさまざまな心臓病理に関するイメージが格納されています。MRI イメージは DICOM ファイル形式で保存され、ラベル イメージは PNG ファイル形式で保存されています。 このコードは、MathWorks の Web サイトから元のデータ セットのサブセットをダウンロードします。このサブセットには、45 人の患者から取得した MRI イメージとラベル イメージが含まれています。合計ダウンロード サイズは約 105 MB です。 zipFile = matlab.internal.examples.downloadSupportFile("medical","CardiacMRI.zip"); filepath = fileparts(zipFile); unzip(zipFile,filepath)
imageDir = fullfile(filepath,"Cardiac MRI");
このデータを深層学習用に処理する方法を示す例については、Cardiac Left Ventricle Segmentation from Cine-MRI Images Using U-Net Network (Medical Imaging Toolbox)を参照してください。 | セマンティック セグメンテーション |


















時系列と信号のデータセット
| データ | 説明 | タスク |
|---|---|---|
Japanese Vowels
| Japanese Vowels データ セットには、さまざまな話者による日本語母音の発話を表す前処理済みのシーケンスが含まれています[29][30]。
Japanese Vowels の学習データ セットとテスト データ セットを、それぞれ load JapaneseVowelsTrainData load JapaneseVowelsTestData このデータを深層学習用に処理する方法を示す例については、深層学習を使用したシーケンスの分類を参照してください。 | sequence-to-label 分類 |
水ぼうそう
| 水ぼうそうデータセットには、月に対応するタイム ステップと発生件数に対応する値を含む 1 つの時系列が含まれています。出力は cell 配列で、その各要素は 1 つのタイム ステップです。 関数 data = chickenpox_dataset;
data = [data{:}]'; | 時系列予測 |
人の行動
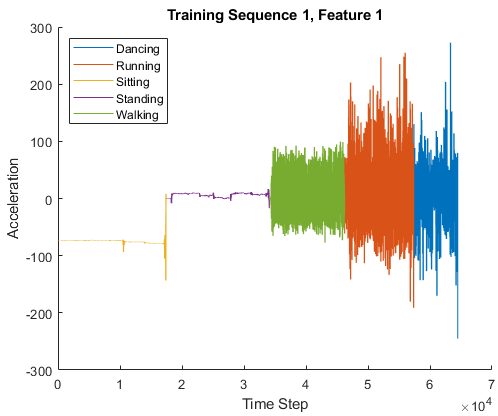
| 行動データセットには、体に装着したスマートフォンから得られたセンサー データの 7 つの時系列が含まれています。各シーケンスには 3 つの特徴があり、長さはさまざまです。3 つの特徴は、3 つの異なる方向での加速度計の測定値に対応します。 人の行動のデータセットを読み込みます。 dataTrain = load('HumanActivityTrain'); dataTest = load('HumanActivityTest'); XTrain = dataTrain.XTrain; YTrain = dataTrain.YTrain; XTest = dataTest.XTest; YTest = dataTest.YTest; このデータを深層学習用に処理する方法を示す例については、深層学習を使用した sequence-to-sequence 分類を参照してください。 | sequence-to-sequence 分類 |
Turbofan Engine Degradation Simulation
| Turbofan Engine Degradation Simulation データ セットの各時系列は、それぞれ異なるエンジンを表します[31]。開始時点では、各エンジンの初期摩耗の程度や製造上の差異は不明です。各時系列の開始時、エンジンは正常に運転していますが、時系列のある時点で故障が発生します。学習セットでは、システム障害が発生するまで、故障の規模が大きくなります。 このデータには、スペースで区切られた 26 列の数値のある zip 圧縮されたテキスト ファイルが含まれています。各行は 1 回の運転サイクルの間に取得されたデータのスナップショットで、各列は異なる変数です。各列は以下に対応します。
Turbofan Engine Degradation Simulation データ セットを格納するディレクトリを作成します。 dataFolder = fullfile(tempdir,"turbofan"); if ~exist(dataFolder,'dir') mkdir(dataFolder); end Turbofan Engine Degradation Simulation データ セットをダウンロードして解凍します。 filename = matlab.internal.examples.downloadSupportFile( ... "nnet","data/TurbofanEngineDegradationSimulationData.zip"); unzip(filename,dataFolder) 補助関数 filenamePredictors = fullfile(dataFolder,"train_FD001.txt"); [XTrain,YTrain] = processTurboFanDataTrain(filenamePredictors); filenamePredictors = fullfile(dataFolder,"test_FD001.txt"); filenameResponses = fullfile(dataFolder,"RUL_FD001.txt"); [XTest,YTest] = processTurboFanDataTest(filenamePredictors,filenameResponses); このデータを深層学習用に処理する方法を示す例については、深層学習を使用した sequence-to-sequence 回帰を参照してください。 | sequence-to-sequence 回帰、予知保全 |
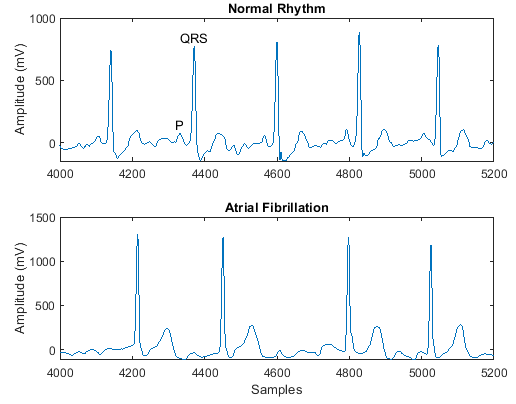
PhysioNet 2017 Challenge
| PhysioNet 2017 Challenge データ セットは、300 Hz でサンプリングされ、専門家グループによって別々のクラスに分けられた、一連の心電図 (ECG) 記録で構成されています[33]。 長短期記憶ネットワークを使用した ECG 信号の分類の例で使用されている ReadPhysionetData
data = load('PhysionetData.mat')
signals = data.Signals;
labels = data.Labels;このデータを深層学習用に処理する方法を示す例については、長短期記憶ネットワークを使用した ECG 信号の分類を参照してください。 | sequence-to-label 分類 |
Tennessee Eastman Process (TEP) シミュレーション
| このデータ セットは、Tennessee Eastman Process (TEP) のシミュレーション データから変換された MAT ファイルで構成されています[32]。 MathWorks のサポート ファイル サイトから、Tennessee Eastman Process (TEP) シミュレーション データ セットをダウンロードします (免責事項を参照してください)。このデータセットには、次の 4 つのコンポーネントがあります。故障なしの学習、故障なしのテスト、故障ありの学習、故障ありのテスト。各ファイルを別々にダウンロードします。 このデータ セットは約 1.7 GB です。 fprintf("Downloading TEP faulty training data (613 MB)... ") filenameFaultyTrain = matlab.internal.examples.downloadSupportFile('predmaint', ... 'chemical-process-fault-detection-data/faultytraining.mat'); fprintf("Done.\n") fprintf("Downloading TEP faulty testing data (1 GB)... ") filenameFaultyTest = matlab.internal.examples.downloadSupportFile('predmaint', ... 'chemical-process-fault-detection-data/faultytesting.mat'); fprintf("Done.\n") fprintf("Downloading TEP fault-free training data (36 MB)... ") filenameFaultFreeTrain = matlab.internal.examples.downloadSupportFile('predmaint', ... 'chemical-process-fault-detection-data/faultfreetraining.mat'); fprintf("Done.\n") fprintf("Downloading TEP fault-free testing data (69 MB)... ") filenameFaultFreeTest = matlab.internal.examples.downloadSupportFile('predmaint', ... 'chemical-process-fault-detection-data/faultfreetesting.mat'); fprintf("Done.\n") ダウンロードしたファイルを MATLAB® ワークスペースに読み込みます。 load(filenameFaultyTrain); load(filenameFaultyTest); load(filenameFaultFreeTrain); load(filenameFaultFreeTest); このデータを深層学習用に処理する方法を示す例については、深層学習を使用した化学的プロセスの故障検出を参照してください。 | sequence-to-label 分類 |
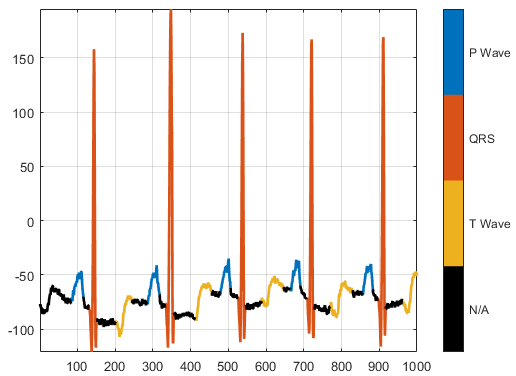
PhysioNet ECG Segmentation
| PhysioNet ECG Segmentation データ セットは、合計 105 人の患者からの約 15 分間の ECG の記録で構成されています[33][34]。各記録を取得するために、検査員は患者の胸部の異なる場所に 2 つの電極を配置して、2 チャネル信号にします。このデータベースは、自動化されたエキスパート システムによって生成される信号領域ラベルを提供します。 https://github.com/mathworks/physionet_ECG_segmentation から downloadFolder = tempdir; url = "https://github.com/mathworks/physionet_ECG_segmentation/raw/master/QT_Database-master.zip"; filename = fullfile(downloadFolder,"QT_Database-master.zip"); dataFolder = fullfile(downloadFolder,"QT_Database-master"); if ~exist(dataFolder,"dir") fprintf("Downloading Physionet ECG Segmentation data set (72 MB)... ") websave(filename,url); unzip(filename,downloadFolder); fprintf("Done.\n") end 解凍すると、一時ディレクトリにフォルダー
load(fullfile(dataFolder,'QTData.mat'))このデータを深層学習用に処理する方法を示す例については、深層学習を使用した波形セグメンテーションを参照してください。 | sequence-to-label 分類、波形セグメンテーション |
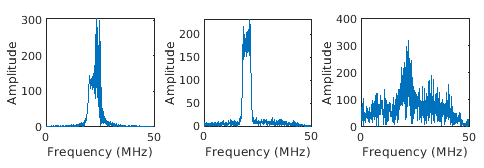
歩行者、自動車、自転車運転者の合成後方散乱
| Pedestrian and Bicyclist Classification Using Deep Learning (Radar Toolbox)の例で使用されている補助関数 補助関数 補助関数 これらの関数にアクセスするには、例をライブ スクリプトとして開きます。
numPed = 1; % Number of pedestrian realizations numBic = 1; % Number of bicyclist realizations numCar = 1; % Number of car realizations [xPedRec,xBicRec,xCarRec,Tsamp] = helperBackScatterSignals(numPed,numBic,numCar); [SPed,T,F] = helperDopplerSignatures(xPedRec,Tsamp); [SBic,~,~] = helperDopplerSignatures(xBicRec,Tsamp); [SCar,~,~] = helperDopplerSignatures(xCarRec,Tsamp); このデータを深層学習用に処理する方法を示す例については、Pedestrian and Bicyclist Classification Using Deep Learning (Radar Toolbox)を参照してください。 | sequence-to-label 分類 |
生成された波形
| Radar and Communications Waveform Classification Using Deep Learning (Radar Toolbox)の例で使用されている補助関数 補助関数 これらの関数にアクセスするには、例をライブ スクリプトとして開きます。
[wav, modType] = helperGenerateRadarWaveforms; このデータを深層学習用に処理する方法を示す例については、Radar and Communications Waveform Classification Using Deep Learning (Radar Toolbox)を参照してください。 | sequence-to-label 分類 |




ビデオのデータセット
| データ | 説明 | タスク |
|---|---|---|
HMDB (大規模人間動作データベース)
(典型例) | HMBD51 データセットには、"飲む"、"走る"、"腕立て伏せ" など、51 クラスの 7,000 個のクリップから成る約 2 GB のビデオ データが格納されています。 HMBD51 データ セットを HMDB51: A Large Video Database for Human Motion Recognition からダウンロードして解凍します。このデータセットは約 2 GB です。 RAR ファイルを解凍した後、深層学習を使用したビデオの分類の例で使用されている補助関数 dataFolder = fullfile(tempdir,"hmdb51_org");
[files,labels] = hmdb51Files(dataFolder);このデータを深層学習用に処理する方法を示す例については、深層学習を使用したビデオの分類を参照してください。 | ビデオ分類 |

テキストのデータセット
| データ | 説明 | タスク |
|---|---|---|
| 工場レポート
| 工場レポート データセットは、さまざまな属性 (変数 ファイル filename = "factoryReports.csv"; data = readtable(filename,'TextType','string'); textData = data.Description; labels = data.Category; このデータを深層学習用に処理する方法を示す例については、深層学習を使用したテキスト データの分類を参照してください。 | テキスト分類、トピック モデリング |
| シェイクスピアのソネット
| ファイル ファイル filename = "sonnets.txt";
textData = fileread(filename);
ソネットは 2 つの空白文字でインデントされ、2 つの改行文字で区切られています。 textData = replace(textData," ",""); textData = split(textData,[newline newline]); textData = textData(5:2:end); このデータを深層学習用に処理する方法を示す例については、深層学習を使用したテキストの生成を参照してください。 | トピック モデリング、テキスト生成 |
| arXiv メタデータ
| arXiv API はhttps://arxiv.orgに提出された科学分野の電子出版物のメタデータ (要旨や主題など) へのアクセスを提供します。詳細については、https://arxiv.org/help/apiを参照してください。 arXiv API を使用して、数学論文から概要とカテゴリ ラベルのセットをインポートします。 url = "https://export.arxiv.org/oai2?verb=ListRecords" + ... "&set=math" + ... "&metadataPrefix=arXiv"; options = weboptions('Timeout',160); code = webread(url,options); 返された XML コードを解析してさらに多くのレコードをインポートする方法を示す例については、深層学習を使用した複数ラベルをもつテキストの分類を参照してください。 | テキスト分類、トピック モデリング |
| Project Gutenberg の書籍
| Project Gutenberg から数多くの書籍をダウンロードできます。たとえば、関数 url = "https://www.gutenberg.org/files/11/11-h/11-h.htm";
code = webread(url);HTML コードには、 tree = htmlTree(code);
selector = "p";
subtrees = findElement(tree,selector);関数 textData = extractHTMLText(subtrees);
textData(textData == "") = [];このデータを深層学習用に処理する方法を示す例については、深層学習を使用した単語単位のテキスト生成を参照してください。 | トピック モデリング、テキスト生成 |
| 週末のアップデート
| ファイル 関数 filename = "weekendUpdates.xlsx"; tbl = readtable(filename,'TextType','string'); textData = tbl.TextData; このデータを処理する方法を示す例については、テキスト内のセンチメントの分析 (Text Analytics Toolbox)を参照してください。 | センチメント分析 |
| ローマ数字
| CSV ファイル CSV ファイル filename = fullfile("romanNumerals.csv"); options = detectImportOptions(filename, ... 'TextType','string', ... 'ReadVariableNames',false); options.VariableNames = ["Source" "Target"]; options.VariableTypes = ["string" "string"]; data = readtable(filename,options); このデータを深層学習用に処理する方法を示す例については、Attention を使用した sequence-to-sequence 変換を参照してください。 | sequence-to-sequence 変換 |
| 財務レポート
| 証券取引委員会 (SEC) は、Electronic Data Gathering, Analysis, and Retrieval (EDGAR) API を介した財務レポートへのアクセスを許可しています。詳細については、https://www.sec.gov/search-filings/edgar-search-assistance/accessing-edgar-dataを参照してください。 このデータをダウンロードするには、Generate Domain Specific Sentiment Lexicon (Text Analytics Toolbox)の例にサポート ファイルとして添付されている関数 year = 2019; qtr = 4; maxLength = 2e6; textData = financeReports(year,qtr,maxLength); このデータを処理する方法を示す例については、Generate Domain Specific Sentiment Lexicon (Text Analytics Toolbox)を参照してください。 | センチメント分析 |





オーディオ データセット
| データ | 説明 | タスク |
|---|---|---|
音声コマンド
| 音声コマンド データ セットは、12 のクラス ("yes"、"no"、"on"、"off" など) のいずれかのラベル、および不明なコマンドやバックグラウンド ノイズに対応するクラスのラベルが付けられた約 65,000 個のオーディオ ファイルで構成されています[35]。 https://storage.googleapis.com/download.tensorflow.org/data/speech_commands_v0.01.tar.gz から音声コマンド データセットをダウンロードして解凍します。このデータセットは約 1.4 GB です。
dataFolder = tempdir; ads = audioDatastore(dataFolder, ... 'IncludeSubfolders',true, ... 'FileExtensions','.wav', ... 'LabelSource','foldernames'); このデータを深層学習用に処理する方法を示す例については、深層学習を使用した音声コマンド認識モデルの学習を参照してください。 | オーディオ分類、音声認識 |
Mozilla Common Voice
| Mozilla Common Voice データセットは、録音音声および対応するテキスト ファイルで構成されています。データには、年齢やアクセントといった人口統計のメタデータも含まれています。 https://commonvoice.mozilla.org/から Mozilla Common Voice データ セットをダウンロードして解凍します。このデータセットはオープンなデータセットであるため、時間がたつにつれて大きくなる可能性があります。2019 年 10 月現在、このデータセットは約 28 GB です。 dataFolder = tempdir;
ads = audioDatastore(fullfile(dataFolder,"clips")); | オーディオ分類、音声認識 |
Free Spoken Digit Dataset
| Free Spoken Digit Dataset には、2019 年 1 月 29 日現在、4 人の話者が英語で発話した 0 ~ 9 の数字の録音が 2000 件含まれています。このバージョンでは、2 人の話者はアメリカ英語を話すネイティブ スピーカー、他の 2 人の話者はそれぞれベルギー フランス語なまりとドイツ語なまりの英語を話す非ネイティブ スピーカーです。データは 8000 Hz でサンプリングされます。 https://github.com/Jakobovski/free-spoken-digit-dataset から Free Spoken Digit Dataset (FSDD) の録音音声をダウンロードします。
dataFolder = fullfile(tempdir,'free-spoken-digit-dataset','recordings'); ads = audioDatastore(dataFolder); このデータを深層学習用に処理する方法を示す例については、ウェーブレット散乱と深層学習を使用した数字音声認識を参照してください。 | オーディオ分類、音声認識 |
Berlin Database of Emotional Speech
| Berlin Database of Emotional Speech には、10 人の俳優によって話された 535 個の発話が含まれています。これらの発話では、怒り、退屈、嫌悪、不安/恐怖、幸福、悲しみ、中立のいずれかの感情が表されています[36]。感情はテキストと無関係です。 ファイル名は、話者 ID、発話されたテキスト、感情、およびバージョンを表すコードです。Web サイトには、コードを解釈するためのヒント、および話者に関する追加の情報 (年齢など) が記載されています。 http://emodb.bilderbar.info/index-1280.html から、Berlin Database of Emotional Speech をダウンロードします。このデータセットは約 40 MB です。
dataFolder = tempdir;
ads = audioDatastore(fullfile(dataFolder,"wav"));
このデータを深層学習用に処理する方法を示す例については、音声感情認識を参照してください。 | オーディオ分類、音声認識 |
TUT Acoustic Scenes 2017
| TUT Acoustic Scenes 2017 データ セットは 15 の音響シーン ("バス"、"自動車"、"図書館" など) から取得した 10 秒間のオーディオ セグメントで構成されています。 TUT Acoustic scenes 2017, Development dataset および TUT Acoustic scenes 2017, Evaluation dataset から、TUT Acoustic Scenes 2017 データ セットをダウンロードして解凍します[37]。 このデータを深層学習用に処理する方法を示す例については、後期融合を使用した音響シーン認識を参照してください。 | 音響シーン分類 |



点群データ セット
| データ | 説明 | タスク |
|---|---|---|
WPI LiDAR データ | WPI LIDAR データは、Ouster OS1 センサーを使用して収集されています。これには、ハイウェイのシーンのオーガナイズド LiDAR 点群スキャンと、自動車やトラックのオブジェクトの対応するグラウンド トゥルース ラベルが含まれています。 このデータ セットには 1617 個の点群が含まれており、cell 配列内の このコードを実行してデータ セットをダウンロードします。 url = 'https://www.mathworks.com/supportfiles/lidar/data/WPI_LidarData.tar.gz'; outputFolder = fullfile(tempdir,'WPI'); lidarDataTarFile = fullfile(outputFolder,'WPI_LidarData.tar.gz'); if ~exist(lidarDataTarFile, 'file') mkdir(outputFolder); disp('Downloading WPI Lidar driving data (760 MB)...'); websave(lidarDataTarFile, url); untar(lidarDataTarFile,outputFolder); end lidarData = load(fullfile(outputFolder, 'WPI_LidarData.mat')); WPI_LidarData フォルダーを解凍することもできます。その場合は、コード内の変数 outputFolder を、ダウンロードしたファイルの場所に変更します。このデータを深層学習用に処理する方法を示す例については、PointSeg 深層学習ネットワークを使用した LIDAR 点群のセマンティック セグメンテーションを参照してください。 | セマンティック セグメンテーション |
PandaSet データ | PandaSet には、Pandar 64 センサーを使用して取得された、都市のさまざまなシーンに関する 2560 オーガナイズド LiDAR 点群スキャンが格納されています。このデータ セットでは、12 個の異なるクラスのセマンティック セグメンテーション ラベル、および 3 つのクラス (自動車、トラック、および歩行者) の 3 次元境界ボックスの情報が用意されています。このデータ セットのサイズは 5.2 GB です。 このコードを実行してデータ セットをダウンロードします。 url = 'https://ssd.mathworks.com/supportfiles/lidar/data/Pandaset_LidarData.tar.gz'; outputFolder = fullfile(tempdir,'Pandaset'); lidarDataTarFile = fullfile(outputFolder,'Pandaset_LidarData.tar.gz'); if ~exist(lidarDataTarFile, 'file') mkdir(outputFolder); disp('Downloading Pandaset Lidar driving data (5.2 GB)...'); websave(lidarDataTarFile, url); untar(lidarDataTarFile,outputFolder); end lidarData = fullfile(outputFolder,'Lidar'); labelsFolder = fullfile(outputFolder,'semanticLabels'); インターネット接続の速度によっては、ダウンロード プロセスに時間がかかることがあります。または、URL を指定して Web ブラウザーからデータ セットをローカル ディスクにダウンロードした後、 このデータを深層学習用に処理する方法を示す例については、SqueezeSegV2 深層学習ネットワークを使用した LiDAR 点群のセマンティック セグメンテーションおよびPointPillars 深層学習を使用した 3 次元 LIDAR オブジェクトの検出を参照してください。 | オブジェクト検出、セマンティック セグメンテーション |


参照
[1] Lake, Brenden M., Ruslan Salakhutdinov, and Joshua B. Tenenbaum. “Human-Level Concept Learning through Probabilistic Program Induction.” Science 350, no. 6266 (December 11, 2015): 1332–38. https://doi.org/10.1126/science.aab3050.
[2] The TensorFlow Team. "Flowers" https://www.tensorflow.org/datasets/catalog/tf_flowers.
[3] Kat, Tulips, image, https://www.flickr.com/photos/swimparallel/3455026124. Creative Commons License (CC BY).
[4] Rob Bertholf, Sunflowers, image, https://www.flickr.com/photos/robbertholf/20777358950. Creative Commons 2.0 Generic License.
[5] Parvin, Roses, image, https://www.flickr.com/photos/55948751@N00. Creative Commons 2.0 Generic License.
[6] John Haslam, Dandelions, image, https://www.flickr.com/photos/foxypar4/645330051. Creative Commons 2.0 Generic License.
[7] Krizhevsky, Alex. "Learning Multiple Layers of Features from Tiny Images." MSc thesis, University of Toronto, 2009. https://www.cs.toronto.edu/%7Ekriz/learning-features-2009-TR.pdf.
[8] Brostow, Gabriel J., Julien Fauqueur, and Roberto Cipolla. “Semantic Object Classes in Video: A High-Definition Ground Truth Database.” Pattern Recognition Letters 30, no. 2 (January 2009): 88–97. https://doi.org/10.1016/j.patrec.2008.04.005.
[9] Kemker, Ronald, Carl Salvaggio, and Christopher Kanan. “High-Resolution Multispectral Dataset for Semantic Segmentation.” ArXiv:1703.01918 [Cs], March 6, 2017. https://arxiv.org/abs/1703.01918.
[10] Isensee, Fabian, Philipp Kickingereder, Wolfgang Wick, Martin Bendszus, and Klaus H. Maier-Hein. “Brain Tumor Segmentation and Radiomics Survival Prediction: Contribution to the BRATS 2017 Challenge.” In Brainlesion: Glioma, Multiple Sclerosis, Stroke and Traumatic Brain Injuries, edited by Alessandro Crimi, Spyridon Bakas, Hugo Kuijf, Bjoern Menze, and Mauricio Reyes, 10670: 287–97. Cham, Switzerland: Springer International Publishing, 2018. https://doi.org/10.1007/978-3-319-75238-9_25.
[11] Ehteshami Bejnordi, Babak, Mitko Veta, Paul Johannes van Diest, Bram van Ginneken, Nico Karssemeijer, Geert Litjens, Jeroen A. W. M. van der Laak, et al. “Diagnostic Assessment of Deep Learning Algorithms for Detection of Lymph Node Metastases in Women With Breast Cancer.” JAMA 318, no. 22 (December 12, 2017): 2199. https://doi.org/10.1001/jama.2017.14585.
[12] McCollough, C.H., Chen, B., Holmes, D., III, Duan, X., Yu, Z., Yu, L., Leng, S., Fletcher, J. (2020). Data from Low Dose CT Image and Projection Data [Data set]. The Cancer Imaging Archive. https://doi.org/10.7937/9npb-2637.
[13] Grants EB017095 and EB017185 (Cynthia McCollough, PI) from the National Institute of Biomedical Imaging and Bioengineering.
[14] Grubinger, Michael, Paul Clough, Henning Müller, and Thomas Deselaers. "The IAPR TC-12 Benchmark: A New Evaluation Resource for Visual Information Systems." Proceedings of the OntoImage 2006 Language Resources For Content-Based Image Retrieval. Genoa, Italy. Vol. 5, May 2006, p. 10.
[15] Ignatov, Andrey, Luc Van Gool, and Radu Timofte. “Replacing Mobile Camera ISP with a Single Deep Learning Model.” ArXiv:2002.05509 [Cs, Eess], February 13, 2020. https://arxiv.org/abs/2002.05509. Project Website.
[16] Chen, Chen, Qifeng Chen, Jia Xu, and Vladlen Koltun. “Learning to See in the Dark.” ArXiv:1805.01934 [Cs], May 4, 2018. https://arxiv.org/abs/1805.01934.
[17] LIVE: Laboratory for Image and Video Engineering. https://live.ece.utexas.edu/research/ChallengeDB/index.html.
[18] Özgenel, Ç. F., and Arzu Gönenç Sorguç. “Performance Comparison of Pretrained Convolutional Neural Networks on Crack Detection in Buildings.” Taipei, Taiwan, 2018. https://doi.org/10.22260/ISARC2018/0094.
[19] Zhang, Lei, Fan Yang, Yimin Daniel Zhang, and Ying Julie Zhu. “Road Crack Detection Using Deep Convolutional Neural Network.” In 2016 IEEE International Conference on Image Processing (ICIP), 3708–12. Phoenix, AZ, USA: IEEE, 2016. https://doi.org/10.1109/ICIP.2016.7533052.
[20] Wu, Ming-Ju, Jyh-Shing R. Jang, and Jui-Long Chen. “Wafer Map Failure Pattern Recognition and Similarity Ranking for Large-Scale Data Sets.” IEEE Transactions on Semiconductor Manufacturing 28, no. 1 (February 2015): 1–12. https://doi.org/10.1109/TSM.2014.2364237.
[21] Jang, Roger. "MIR Corpora." http://mirlab.org/dataset/public/.
[22] Huang, Weibo, and Peng Wei. "A PCB dataset for defects detection and classification." arXiv preprint arXiv:1901.08204 (2019). https://arxiv.org/abs/1901.08204.
[23] Synthetic PCB Dataset. https://github.com/Ironbrotherstyle/PCB-DATASET.
[24] Zou, Yang, Jongheon Jeong, Latha Pemula, Dongqing Zhang, and Onkar Dabeer. "SPot-the-Difference Self-supervised Pre-training for Anomaly Detection and Segmentation." In Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part XXX, pp. 392-408. Cham: Springer Nature Switzerland, 2022. https://arxiv.org/pdf/2207.14315v1.
[25] Visual Anomaly (VisA) Dataset. https://github.com/amazon-science/spot-diff/tree/main.
[26] Al-Dhabyani, Walid, Mohammed Gomaa, Hussien Khaled, and Aly Fahmy. “Dataset of Breast Ultrasound Images.” Data in Brief 28 (February 2020): 104863. https://doi.org/10.1016/j.dib.2019.104863.
[27] Frazier, J. A., S. M. Hodge, J. L. Breeze, A. J. Giuliano, J. E. Terry, C. M. Moore, D. N. Kennedy, et al. “Diagnostic and Sex Effects on Limbic Volumes in Early-Onset Bipolar Disorder and Schizophrenia.” Schizophrenia Bulletin 34, no. 1 (October 27, 2007): 37–46. https://doi.org/10.1093/schbul/sbm120.
[28] Radau, Perry, Yingli Lu, Kim Connelly, Gideon Paul, Alexander J Dick, and Graham A Wright. “Evaluation Framework for Algorithms Segmenting Short Axis Cardiac MRI.” The MIDAS Journal, July 9, 2009. https://doi.org/10.54294/g80ruo.
[29] Kudo, Mineichi, Jun Toyama, and Masaru Shimbo. "Multidimensional Curve Classification Using Passing-through Regions." Pattern Recognition Letters 20, no. 11–13 (November 1999): 1103–11. https://doi.org/10.1016/S0167-8655(99)00077-X.
[30] Kudo, Mineichi, Jun Toyama, and Masaru Shimbo. Japanese Vowels Data Set. Distributed by UCI Machine Learning Repository. https://archive.ics.uci.edu/ml/datasets/Japanese+Vowels
[31] Saxena, Abhinav, Kai Goebel, Don Simon, and Neil Eklund. "Damage propagation modeling for aircraft engine run-to-failure simulation." In Prognostics and Health Management, 2008. PHM 2008. International Conference on, pp. 1-9. IEEE, 2008.
[32] Rieth, Cory A., Ben D. Amsel, Randy Tran, and Maia B. Cook. "Additional Tennessee Eastman Process Simulation Data for Anomaly Detection Evaluation." Harvard Dataverse, Version 1, 2017. https://doi.org/10.7910/DVN/6C3JR1.
[33] Goldberger, Ary L., Luis A. N. Amaral, Leon Glass, Jeffrey M. Hausdorff, Plamen Ch. Ivanov, Roger G. Mark, Joseph E. Mietus, George B. Moody, Chung-Kang Peng, and H. Eugene Stanley. "PhysioBank, PhysioToolkit, and PhysioNet: Components of a New Research Resource for Complex Physiologic Signals." Circulation 101, No. 23, 2000, pp. e215–e220. https://www.ahajournals.org/doi/full/10.1161/01.cir.101.23.e215.
[34] Laguna, Pablo, Roger G. Mark, Ary L. Goldberger, and George B. Moody. "A Database for Evaluation of Algorithms for Measurement of QT and Other Waveform Intervals in the ECG." Computers in Cardiology 24, 1997, pp. 673–676.
[35] Warden, Pete. "Speech Commands: A public dataset for single-word speech recognition", 2017. Available from http://download.tensorflow.org/data/speech_commands_v0.01.tar.gz. Copyright Google 2017. The Speech Commands Dataset is licensed under the Creative Commons Attribution 4.0 license, available here: https://creativecommons.org/licenses/by/4.0/legalcode.
[36] Burkhardt, Felix, Astrid Paeschke, Melissa A. Rolfes, Walter F. Sendlmeier, and Benjamin Weiss. "A Database of German Emotional Speech." Proceedings of Interspeech 2005. Lisbon, Portugal: International Speech Communication Association, 2005.
[37] Mesaros, Annamaria, Toni Heittola, and Tuomas Virtanen. "Acoustic scene classification: an overview of DCASE 2017 challenge entries." In 2018 16th International Workshop on Acoustic Signal Enhancement (IWAENC), pp. 411-415. IEEE, 2018.
[38] Hesai and Scale. PandaSet. https://pandaset.org/
参考
trainnet | trainingOptions | dlnetwork