シーケンス データのカスタム ミニバッチ データストアを使用したネットワークの学習
この例では、カスタム ミニバッチ データストアを使用してメモリ外のシーケンス データで深層学習ネットワークに学習させる方法を説明します。
"ミニバッチ データストア" とは、バッチ単位でのデータの読み取りをサポートするデータストアの実装です。ミニバッチ データストアを使用して、メモリ外のデータを読み取るか、データのバッチを読み取る際に特定の前処理演算を実行します。ミニバッチ データストアは、深層学習アプリケーションの学習データ セット、検証データ セット、テスト データ セット、および予測データ セットのソースとして使用できます。
この例では、サポート ファイルとしてこの例に添付されているカスタム ミニバッチ データストア sequenceDatastore を使用します。データストア関数をカスタマイズして、このデータストアをデータに適応させることができます。独自のカスタム ミニバッチ データストアを作成する方法を示す例については、カスタム ミニバッチ データストアの開発を参照してください。
学習データの読み込み
[1] および [2] に記載のある Japanese Vowels データ セットを読み込みます。zip ファイル japaneseVowels.zip には可変長のシーケンスが含まれています。シーケンスは 2 つのフォルダー Train と Test に分割されています。これらのフォルダーには、学習シーケンスとテスト シーケンスがそれぞれ含まれています。これらの各フォルダーでは、シーケンスが 1 から 9 まで番号が付けられたサブフォルダーに分割されています。これらのサブフォルダーの名前はラベル名です。MAT ファイルは各シーケンスを表します。各シーケンスは行列で、行数が 12 (特徴ごとに 1 行) で、列数が可変 (タイム ステップごとに 1 列) です。行数はシーケンス次元で、列数はシーケンス長です。
シーケンス データを解凍します。
filename = "japaneseVowels.zip"; outputFolder = fullfile(tempdir,"japaneseVowels"); unzip(filename,outputFolder);
カスタム ミニバッチ データストアの作成
カスタム ミニバッチ データストアを作成します。ミニバッチ データストア sequenceDatastore はフォルダーからデータを読み取り、サブフォルダー名からラベルを取得します。
sequenceDatastore を使用してシーケンス データを含むデータストアを作成します。
folderTrain = fullfile(outputFolder,"Train");
dsTrain = sequenceDatastore(folderTrain)dsTrain =
sequenceDatastore with properties:
Datastore: [1×1 matlab.io.datastore.FileDatastore]
Labels: [270×1 categorical]
NumClasses: 9
SequenceDimension: 12
MiniBatchSize: 128
NumObservations: 270
LSTM ネットワーク アーキテクチャの定義
LSTM ネットワーク アーキテクチャを定義します。入力データのシーケンス次元を入力サイズとして指定します。100 個の隠れユニットを持つ LSTM 層を指定して、シーケンスの最後の要素を出力します。最後に、出力サイズがクラスの数に等しい全結合層を指定し、その後にソフトマックス層を配置します。
inputSize = dsTrain.SequenceDimension;
numClasses = dsTrain.NumClasses;
numHiddenUnits = 100;
layers = [
sequenceInputLayer(inputSize)
lstmLayer(numHiddenUnits,OutputMode="last")
fullyConnectedLayer(numClasses)
softmaxLayer];学習オプションを指定します。ソルバーを adam に指定し、GradientThreshold を 1 に指定します。ミニバッチ サイズを 27、最大エポック数を 75 に設定します。データストアによって関数 trainnet が必要とするサイズのミニバッチが確実に作成されるように、データストアのミニバッチ サイズも同じ値に設定します。
ミニバッチが小さく、シーケンスが短いため、学習には CPU が適しています。ExecutionEnvironment を cpu に設定します。GPU が利用できる場合に GPU で学習を行うには、ExecutionEnvironment を "auto" (既定値) に設定します。
miniBatchSize = 27; options = trainingOptions("adam", ... InputDataFormats="CTB", ... Metrics="accuracy", ... ExecutionEnvironment="cpu", ... MaxEpochs=40, ... MiniBatchSize=miniBatchSize, ... GradientThreshold=1, ... Verbose=false, ... Plots="training-progress"); dsTrain.MiniBatchSize = miniBatchSize;
関数trainnetを使用してニューラル ネットワークに学習させます。分類には、クロスエントロピー損失を使用します。
net = trainnet(dsTrain,layers,"crossentropy",options);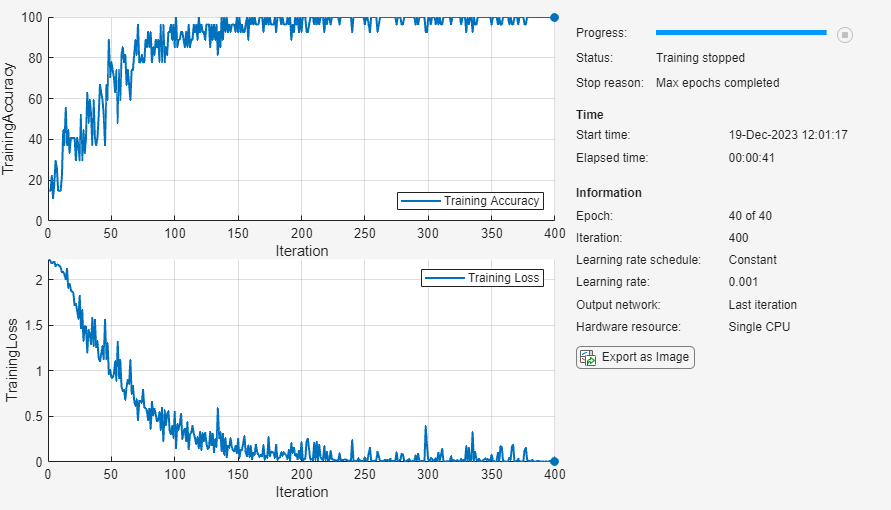
ネットワークのテスト
テスト データからシーケンス データストアを作成します。学習データの場合と同じミニバッチ サイズを指定します。
folderTest = fullfile(outputFolder,"Test");
dsTest = sequenceDatastore(folderTest);
dsTest.MiniBatchSize = miniBatchSize;testnet関数を使用してニューラル ネットワークをテストします。単一ラベルの分類では、精度を評価します。精度は、正しい予測の割合です。既定では、testnet 関数は利用可能な GPU がある場合にそれを使用します。実行環境を手動で選択するには、testnet 関数の ExecutionEnvironment 引数を使用します。関数が学習時と同じサイズおよび形式のミニバッチを確実に使用するようにするには、ExecutionEnvironment 引数、InputDataFormats 引数、および MiniBatchSize 引数を学習時と同じ値に設定します。
accuracy = testnet(net,dsTest,"accuracy", ... ExecutionEnvironment="cpu", ... InputDataFormats="CTB", ... MiniBatchSize=miniBatchSize)
accuracy = 92.4324
参照
[1] Kudo, M., J. Toyama, and M. Shimbo. "Multidimensional Curve Classification Using Passing-Through Regions." Pattern Recognition Letters. Vol. 20, No. 11–13, pp. 1103–1111.
[2] Kudo, M., J. Toyama, and M. Shimbo. Japanese Vowels Data Set. https://archive.ics.uci.edu/ml/datasets/Japanese+Vowels
参考
trainnet | trainingOptions | dlnetwork | lstmLayer | sequenceInputLayer