量子化
層の重み、バイアス、および活性化を、低い精度にスケーリングされた整数データ型に量子化します。その後、この量子化ネットワークから、GPU、FPGA、または CPU 展開用の C/C++ コード、CUDA® コード、または HDL コードを生成できます。
Deep Learning Toolbox™ Model Compression Library で利用可能な圧縮手法の詳細な概要については、Reduce Memory Footprint of Deep Neural Networksを参照してください。
関数
dlquantizer | 深層ニューラル ネットワークを 8 ビットにスケーリングされた整数データ型に量子化する |
dlquantizationOptions | Options for quantizing a trained deep neural network |
prepareNetwork | Prepare deep neural network for quantization (R2024b 以降) |
calibrate | 深層ニューラル ネットワークのシミュレーションと範囲の収集 |
quantize | Quantize deep neural network (R2022a 以降) |
validate | Quantize and validate a deep neural network |
quantizationDetails | ニューラル ネットワークの量子化詳細の表示 (R2022a 以降) |
estimateNetworkMetrics | Estimate network metrics for specific layers of a neural network (R2022a 以降) |
equalizeLayers | Equalize layer parameters of deep neural network (R2022b 以降) |
exportNetworkToSimulink | Generate Simulink model that contains deep learning layer blocks and subsystems that correspond to deep learning layer objects (R2024b 以降) |
アプリ
| ディープ ネットワーク量子化器 | Quantize deep neural network to 8-bit scaled integer data types |
トピック
量子化について
- 深層ニューラル ネットワークの量子化
量子化の影響とネットワーク畳み込み層のダイナミック レンジの可視化方法を学習します。 - Data Types and Scaling for Quantization of Deep Neural Networks
Understand effects of quantization and how to visualize dynamic ranges of network convolution layers.
展開前ワークフロー
- Prepare Data for Quantizing Networks
Learn about supported data formats for quantization workflows. - Quantize Multiple-Input Network Using Image and Feature Data
Quantize a network with multiple inputs. - Export Quantized Networks to Simulink and Generate Code
Export a quantized neural network to Simulink and generate code from the exported model. - Quantization-Aware Training with Pseudo-Quantization Noise
Perform quantization-aware training with pseudo-quantization noise on the MobileNet-V2 network. (R2026a 以降)
展開
- Quantize Semantic Segmentation Network and Generate CUDA Code
Quantize a convolutional neural network trained for semantic segmentation and generate CUDA code. - Classify Images on FPGA by Using Quantized GoogLeNet Network (Deep Learning HDL Toolbox)
This example shows how to use the Deep Learning HDL Toolbox™ to deploy a quantized GoogleNet network to classify an image. - Compress Image Classification Network for Deployment to Resource-Constrained Embedded Devices
Reduce the memory footprint and computation requirements of an image classification network for deployment to resource-constrained embedded devices such as the Raspberry Pi®.
考慮事項
- 量子化ワークフローのシステム要件
深層ニューラル ネットワークの量子化に必要な製品を確認する。 - Supported Layers for Quantization
Learn which deep neural network layers are supported for quantization.
注目の例
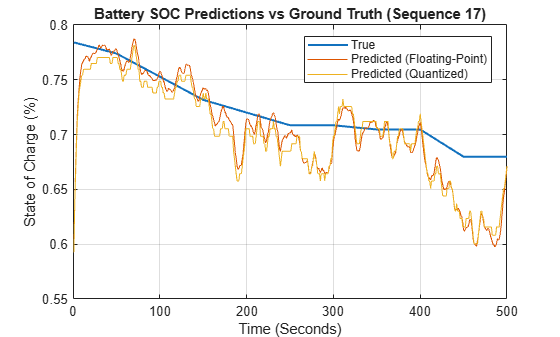
Quantize Deep Learning Network for Battery State of Charge Estimation
Quantize recurrent neural network trained for battery state of charge estimation.
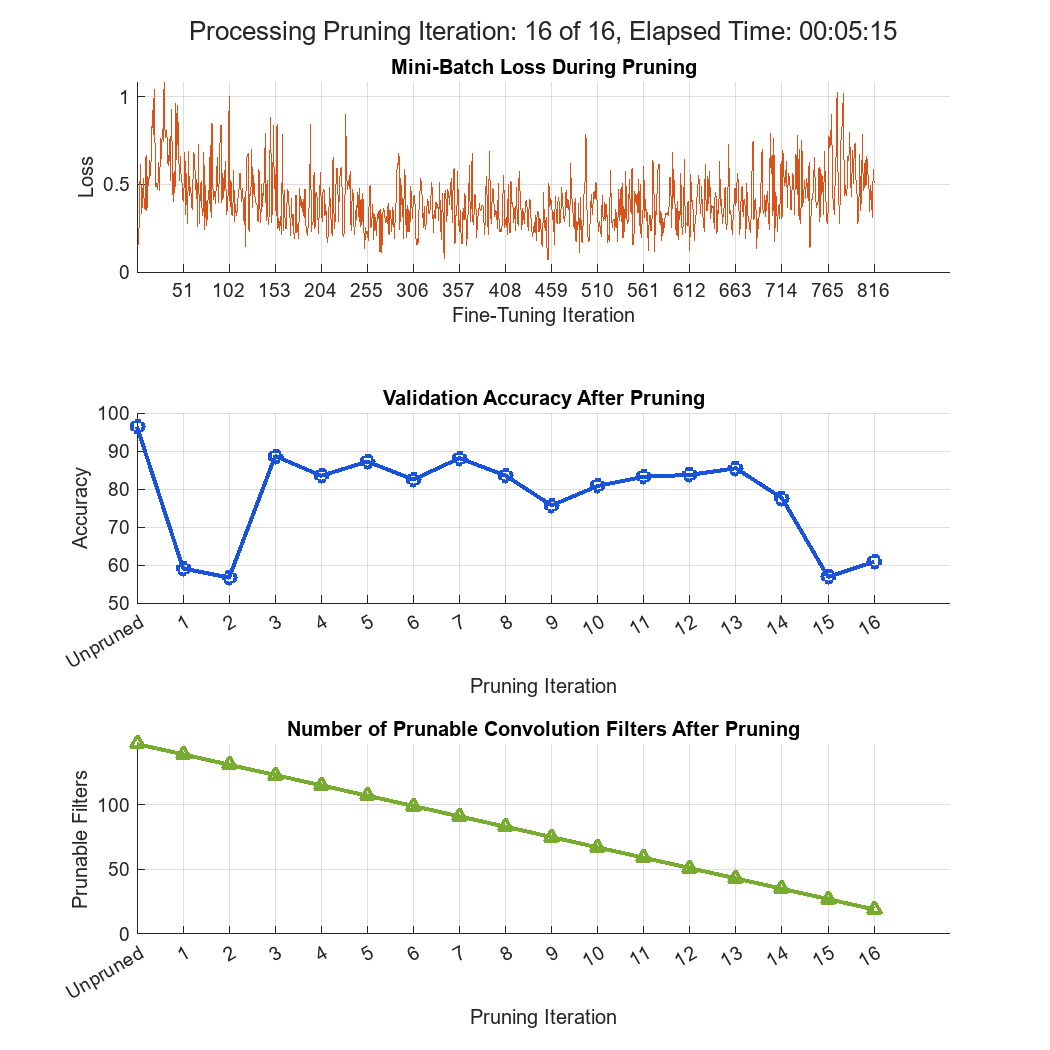
Prune and Quantize Convolutional Neural Network for Speech Recognition
Compress a convolutional neural network (CNN) to prepare it for deployment on an embedded system.
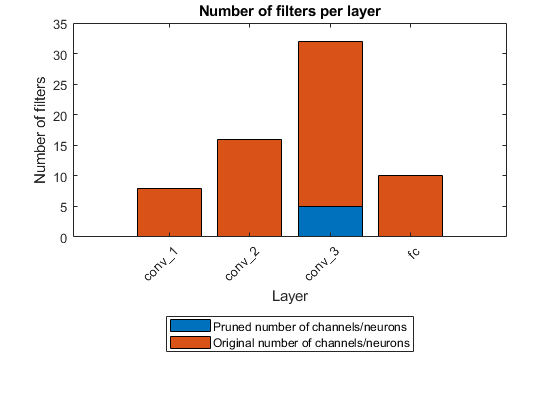
イメージ分類ネットワークのパラメーターの枝刈りと量子化
パラメーターの枝刈りと量子化を行ってネットワークのサイズを小さくする。

Prune and Quantize Semantic Segmentation Network
Reduce the memory footprint of a semantic segmentation network and speed-up inference by compressing the network using pruning and quantization.

オブジェクト検出器の層の量子化と CUDA コードの生成
この例では、畳み込み層に対して 8 ビット整数で推論計算を実行する SSD 車両検出器および YOLO v2 車両検出器の CUDA® コードを生成する方法を示します。

イメージ分類用の学習済み残差ネットワークの量子化と CUDA コードの生成
この例では、残差結合をもち、イメージ分類用に CIFAR-10 データで学習させた深層学習ニューラル ネットワークの畳み込み層で、学習可能パラメーターを量子化する方法を示します。