イメージ分類ネットワークのパラメーターの枝刈りと量子化
この例では、非構造化枝刈りを使用して、学習済みニューラル ネットワークのパラメーターを枝刈りする方法を示します。
新しいタスク用に転送学習を使用してイメージ分類ネットワークに再学習させたり、新しいネットワークに最初から学習させたりするような用途では、多くの場合、最適なネットワーク アーキテクチャが不明なため、ネットワークのパラメーターが過多になる可能性があります。パラメーター過多のネットワークには冗長な接続があります。枝刈りにより、ネットワークの精度に影響を与えることなく削除できる冗長な接続が特定されます。
この例では、非構造化枝刈りを使用し、2 つのパラメーター スコア メトリクス (Magnitude スコア [1] と Synaptic Flow スコア [2]) に基づいて値がゼロのパラメーターの数を増やします。値がゼロのパラメーターの数が増えると、ネットワークのスパース性が増加します。
この例では、以下の方法を説明します。
学習データを必要としない、学習後の反復的な非構造化枝刈りの実行
2 つの異なる枝刈りアルゴリズムのパフォーマンスの評価
枝刈り後に誘起された層ごとのスパース性の調査
枝刈りが分類精度に与える影響の評価
枝刈りされたネットワークの分類精度に対する量子化の影響の評価
この例では、シンプルな畳み込みニューラル ネットワークを使用して、ユーザーが書いた 0 ~ 9 の数字を分類します。学習と検証に使用されるデータの設定の詳細については、分類用のシンプルな深層学習ニューラル ネットワークの作成を参照してください。
ネットワークからフィルター全体を削除して接続を排除する構造化枝刈りを使用して、ネットワークを枝刈りすることもできます。構造化枝刈りと量子化を組み合わせると、推論速度が向上し、ネットワークのメモリ使用量が少なくなります。構造化枝刈りの例については、Prune Image Classification Network Using Taylor Scoresを参照してください。
事前学習済みのネットワークおよびデータの読み込み
学習データと検証データを読み込みます。分類タスク用として畳み込みニューラル ネットワークに学習させます。
[imdsTrain, imdsValidation] = loadDigitDataset; net = trainDigitDataNetwork(imdsTrain, imdsValidation); trueLabels = imdsValidation.Labels; classes = categories(trueLabels);
検証データを含む minibatchqueue オブジェクトを作成します。利用可能な場合に GPU でネットワークを評価するには、executionEnvironment を [auto] に設定します。既定では、minibatchqueue オブジェクトは、GPU が利用可能な場合、各出力を gpuArray に変換します。GPU を使用するには、Parallel Computing Toolbox™ とサポートされている GPU デバイスが必要です。サポートされているデバイスの詳細については、GPU 計算の要件 (Parallel Computing Toolbox)を参照してください。
executionEnvironment ="auto"; miniBatchSize = 128; imdsValidation.ReadSize = miniBatchSize; mbqValidation = minibatchqueue(imdsValidation,1,... 'MiniBatchSize',miniBatchSize,... 'MiniBatchFormat','SSCB',... 'MiniBatchFcn',@preprocessMiniBatch,... 'OutputEnvironment',executionEnvironment);
ニューラル ネットワークの枝刈り
ニューラル ネットワークの枝刈りの目的は、重要でない接続を特定して削除し、ネットワークの精度に影響を与えることなくネットワークのサイズを縮小することです。下図の左側のネットワークには、各ニューロンを次の層のニューロンにマッピングする接続があります。枝刈り後、ネットワークの接続数は元のネットワークより少なくなります。
![ParameterPruningExample_01[1].png](../../examples/deeplearning_shared/win64/ParameterPruningExample_01.png)
枝刈りアルゴリズムでは、ネットワーク内の各パラメーターにスコアを割り当てます。スコアは、ネットワーク内の各接続の重要度をランク付けします。次の 2 つの枝刈り手法のいずれかを使用して、スパース性目標を達成できます。
ワンショット枝刈り - 1 つのステップでのスコアに基づいて、指定した割合の接続を削除します。この方法では、スパース性に高い値を指定したときに層が崩壊する傾向があります。
反復枝刈り - 一連の反復ステップでスパース性目標を達成します。評価スコアがネットワーク構造に影響されやすい場合は、この方法を使用できます。スコアが反復ごとに再評価されるため、一連のステップを使用して、ネットワークのスパース性をインクリメンタルに強化できます。
この例では、反復枝刈り手法を使用して、スパース性目標を達成します。
反復枝刈り
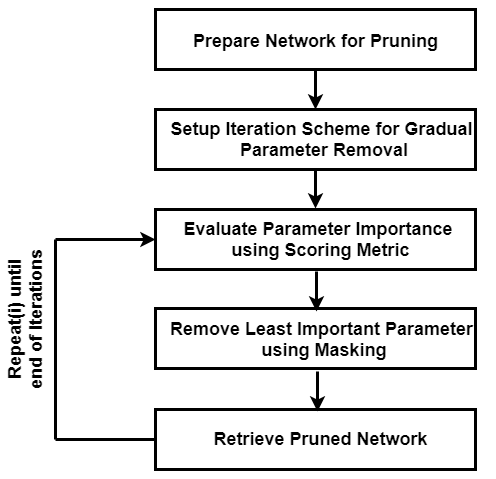
dlnetwork オブジェクトへの変換
この例では、Synaptic Flow アルゴリズムを使用します。このアルゴリズムでは、カスタム コスト関数を作成し、コスト関数に対する勾配を評価してパラメーター スコアを計算する必要があります。カスタム コスト関数を作成するには、最初に事前学習済みのネットワークをdlnetworkに変換します。
removeLayers を使用してソフトマックス層を削除します。
dlnet = net;
dlnet = removeLayers(dlnet,"softmax");
dlnet = initialize(dlnet);analyzeNetwork を使用して、ネットワーク アーキテクチャと学習可能なパラメーターを解析します。
analyzeNetwork(dlnet)
枝刈りする前に、ネットワークの精度を評価します。
accuracyOriginalNet = evaluateAccuracy(dlnet,mbqValidation,classes,trueLabels)
accuracyOriginalNet = 0.9888
学習可能なパラメーターをもつ層は、3 つの畳み込み層と 1 つの全結合層です。ネットワークは初期状態で、合計 21,578 個の学習可能なパラメーターで構成されます。
numTotalParams = sum(cellfun(@numel,dlnet.Learnables.Value))
numTotalParams = 21578
numNonZeroPerParam = cellfun(@(w)nnz(extractdata(w)),dlnet.Learnables.Value)
numNonZeroPerParam = 8×1
72
8
1152
16
4608
32
15680
10
スパース性は、ゼロの値をもつネットワーク内パラメーターの割合として定義されます。ネットワークのスパース性をチェックします。
initialSparsity = 1-(sum(numNonZeroPerParam)/numTotalParams)
initialSparsity = 0
枝刈りする前は、ネットワークのスパース性はゼロです。
反復スキームの作成
反復枝刈りスキームを定義するには、スパース性目標と反復回数を指定します。この例では、線形に等間隔の反復を使用して、スパース性目標を達成します。
numIterations = 10; targetSparsity = 0.90; iterationScheme = linspace(0,targetSparsity,numIterations);
枝刈りループ
この例のカスタム枝刈りループは、反復ごとに次の手順を実行します。
各接続のスコアを計算します。
選択した枝刈りアルゴリズムに基づいて、ネットワーク内のすべての接続のスコアをランク付けします。
スコアが最も低い接続を削除するためのしきい値を決定します。
しきい値を使用して枝刈りマスクを作成します。
ネットワークの学習可能なパラメーターに枝刈りマスクを適用します。
ネットワーク マスク
枝刈りアルゴリズムでは、重み配列のエントリを直接ゼロに設定するのではなく、学習可能なパラメーターごとにバイナリ マスクを作成して、接続が枝刈りされるかどうかを指定します。マスクを使用すると、基となるネットワーク構造を変更せずに、枝刈りされたネットワークの動作を調査し、さまざまな枝刈りスキームを試すことができます。
たとえば、次の重みについて考えます。
testWeight = [10.4 5.6 0.8 9];
testWeight のパラメーターごとにバイナリ マスクを作成します。
testMask = [1 0 1 0];
testWeight にマスクを適用して、枝刈り後の重みを取得します。
testWeightsPruned = testWeight.*testMask
testWeightsPruned = 1×4
10.4000 0 0.8000 0
反復枝刈りでは、枝刈り情報を含む反復ごとにバイナリ マスクを作成します。重み配列にマスクを適用しても、配列のサイズやニューラル ネットワークの構造は変更されません。したがって、枝刈りステップが推論の高速化やディスク上のネットワーク サイズの圧縮に直接つながることはありません。
枝刈りされたネットワークの精度と元のネットワークを比較するプロットを初期化します。
figure plot(100*iterationScheme([1,end]),100*accuracyOriginalNet*[1 1],'*-b','LineWidth',2,"Color","b") ylim([0 100]) xlim(100*iterationScheme([1,end])) xlabel("Sparsity (%)") ylabel("Accuracy (%)") legend("Original Accuracy","Location","southwest") title("Pruning Accuracy") grid on
Magnitude 枝刈り
Magnitude 枝刈り [1] は、各パラメーターにその絶対値と等しいスコアを割り当てます。パラメーターの絶対値は、学習済みのネットワークの精度に対するパラメーターの相対的な重要度に対応すると仮定します。
マスクを初期化します。最初の反復では、パラメーターが枝刈りされておらず、スパース性は 0% です。
pruningMaskMagnitude = cell(1,numIterations);
pruningMaskMagnitude{1} = dlupdate(@(p)true(size(p)), dlnet.Learnables);以下は、Magnitude 枝刈りの実装です。枝刈りされたネットワークをその精度に基づいて柔軟に選択できるようにするため、ネットワークは、ループ内でさまざまなスパース性目標を満たすように枝刈りされます。
lineAccuracyPruningMagnitude = animatedline('Color','g','Marker','o','LineWidth',1.5); legend("Original Accuracy","Magnitude Pruning Accuracy","Location","southwest") % Compute magnitude scores scoresMagnitude = calculateMagnitudeScore(dlnet); for idx = 1:numel(iterationScheme) prunedNetMagnitude = dlnet; % Update the pruning mask pruningMaskMagnitude{idx} = calculateMask(scoresMagnitude,iterationScheme(idx)); % Check the number of zero entries in the pruning mask numPrunedParams = sum(cellfun(@(m)nnz(~extractdata(m)),pruningMaskMagnitude{idx}.Value)); sparsity = numPrunedParams/numTotalParams; % Apply pruning mask to network parameters prunedNetMagnitude.Learnables = dlupdate(@(W,M)W.*M, prunedNetMagnitude.Learnables, pruningMaskMagnitude{idx}); % Compute validation accuracy on pruned network accuracyMagnitude = evaluateAccuracy(prunedNetMagnitude,mbqValidation,classes,trueLabels); % Display the pruning progress addpoints(lineAccuracyPruningMagnitude,100*sparsity,100*accuracyMagnitude) drawnow end

SynFlow 枝刈り
枝刈りに Synaptic Flow 保存 (SynFlow) [2] スコアを使用します。この手法を使用して、ReLU などの線形活性化関数を使用するネットワークを枝刈りできます。
マスクを初期化します。最初の反復では、パラメーターが枝刈りされておらず、スパース性は 0% です。
pruningMaskSynFlow = cell(1,numIterations);
pruningMaskSynFlow{1} = dlupdate(@(p)true(size(p)),dlnet.Learnables);スコアの計算に使用する入力データは、1 を含む単一のイメージです。GPU を使用している場合は、データを gpuArray に変換します。
dlX = dlarray(ones(net.Layers(1).InputSize),'SSC'); if (executionEnvironment == "auto" && canUseGPU) || executionEnvironment == "gpu" dlX = gpuArray(dlX); end
以下のループは、枝刈り用の反復 Synaptic Flow スコア [2] を実装するものです。ここで、カスタム コスト関数は、ネットワークの枝刈りに使用される各パラメーターの SynFlow スコアを評価します。
lineAccuracyPruningSynflow = animatedline('Color','r','Marker','o','LineWidth',1.5); legend("Original Accuracy","Magnitude Pruning Accuracy","Synaptic Flow Accuracy","Location","southwest") prunedNetSynFlow = dlnet; % Iteratively increase sparsity for idx = 1:numel(iterationScheme) % Compute SynFlow scores scoresSynFlow = calculateSynFlowScore(prunedNetSynFlow,dlX); % Update the pruning mask pruningMaskSynFlow{idx} = calculateMask(scoresSynFlow,iterationScheme(idx)); % Check the number of zero entries in the pruning mask numPrunedParams = sum(cellfun(@(m)nnz(~extractdata(m)),pruningMaskSynFlow{idx}.Value)); sparsity = numPrunedParams/numTotalParams; % Apply pruning mask to network parameters prunedNetSynFlow.Learnables = dlupdate(@(W,M)W.*M, prunedNetSynFlow.Learnables, pruningMaskSynFlow{idx}); % Compute validation accuracy on pruned network accuracySynFlow = evaluateAccuracy(prunedNetSynFlow,mbqValidation,classes,trueLabels); % Display the pruning progress addpoints(lineAccuracyPruningSynflow,100*sparsity,100*accuracySynFlow) drawnow end

枝刈りされたネットワークの構造の調査
ネットワークをどれくらい枝刈りするかは、精度とスパース性の間でのトレードオフです。スパース性と精度の比較プロットを使用して、目標とするスパース性レベルと精度許容範囲を満たす反復を選択します。
pruningMethod ="SynFlow"; selectedIteration =
8; prunedDLNet = createPrunedNet(dlnet,selectedIteration,pruningMaskSynFlow,pruningMaskMagnitude,pruningMethod); [sparsityPerLayer,prunedChannelsPerLayer,numOutChannelsPerLayer,layerNames] = pruningStatistics(prunedDLNet);
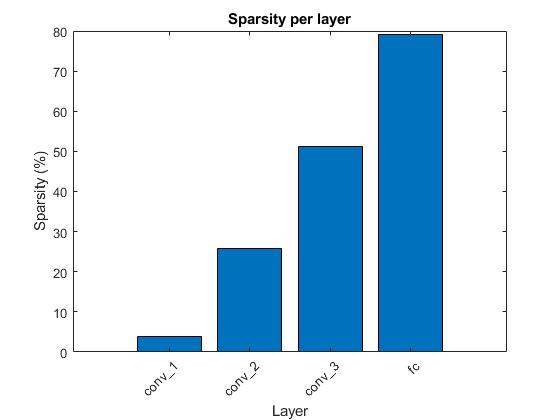
初期の畳み込み層では通常、枝刈りが少なくなります。これは、イメージの解釈に不可欠な、イメージの低レベルな中核構造 (エッジやコーナーなど) に関するより関連性の高い情報が含まれるためです。
選択した枝刈り方法と反復について、層ごとのスパース性をプロットします。
figure bar(sparsityPerLayer*100) title("Sparsity per layer") xlabel("Layer") ylabel("Sparsity (%)") xticks(1:numel(sparsityPerLayer)) xticklabels(layerNames) xtickangle(45) set(gca,'TickLabelInterpreter','none')
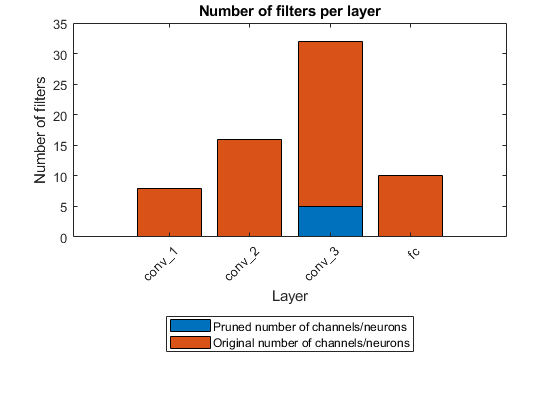
低いスパース性目標を指定すると、枝刈りアルゴリズムは単一の接続を枝刈りします。高いスパース性目標を指定すると、枝刈りアルゴリズムは畳み込み層または全結合層のフィルターとニューロン全体を枝刈りします。
figure bar([prunedChannelsPerLayer,numOutChannelsPerLayer-prunedChannelsPerLayer],"stacked") xlabel("Layer") ylabel("Number of filters") title("Number of filters per layer") xticks(1:(numel(layerNames))) xticklabels(layerNames) xtickangle(45) legend("Pruned number of channels/neurons" , "Original number of channels/neurons","Location","southoutside") set(gca,'TickLabelInterpreter','none')
ネットワークの精度の評価
枝刈り前後のネットワークの精度を比較します。
YPredOriginal = modelPredictions(dlnet,mbqValidation,classes); accOriginal = mean(YPredOriginal == trueLabels)
accOriginal = 0.9888
YPredPruned = modelPredictions(prunedDLNet,mbqValidation,classes); accPruned = mean(YPredPruned == trueLabels)
accPruned = 0.9316
混同行列チャートを作成して、元のネットワークと枝刈りされたネットワークについて、予測されたクラス ラベルに対する真のクラス ラベルを調べます。
figure
confusionchart(trueLabels,YPredOriginal);
title("Original Network")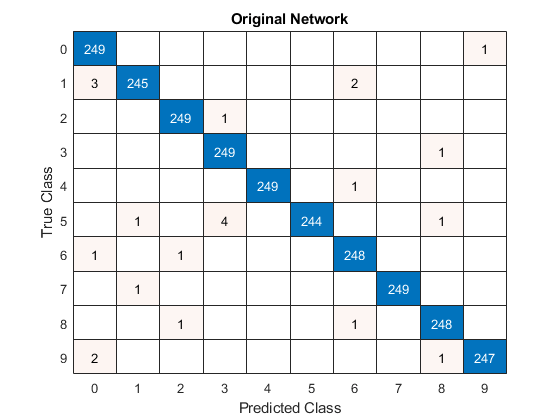
数字データの検証セットには、クラスごとに 250 個のイメージが含まれているため、ネットワークが各イメージのクラスを完璧に予測した場合、対角線上のすべてのスコアは 250 に等しくなり、対角線の外側に値がないことになります。
confusionchart(trueLabels,YPredPruned);
title("Pruned Network")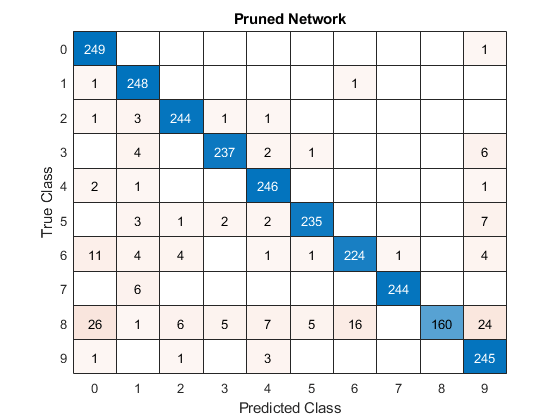
ネットワークを枝刈りするときは、元のネットワークと枝刈りされたネットワークの混同チャートを比較して、選択したスパース性レベルで各クラス ラベルの精度がどのように変化するかをチェックします。対角線上のすべての数値がほぼ等しく減少する場合、バイアスは存在しません。ただし、減少が均等でない場合は、変数 selectedIteration の値を減らして、枝刈りされたネットワークを前の反復から選択する必要があります。
枝刈りされたネットワークの量子化
MATLAB で学習させた深層ニューラル ネットワークは、単精度浮動小数点データ型を使用します。小規模なネットワークでも、浮動小数点算術演算を実行するには大量のメモリとハードウェアが必要です。このような制限は、計算能力が低く、メモリ リソースが少ない場合に深層学習モデルの展開を妨げる可能性があります。重みと活性化を保存するための精度を下げることによって、ネットワークのメモリ要件を緩和させることができます。Deep Learning Toolbox と Deep Learning Toolbox Model Compression Library サポート パッケージを併用して、畳み込み層の重み、バイアス、および活性化を 8 ビットにスケーリングされた整数データ型に量子化することによって、深層ニューラル ネットワークのメモリ フットプリントを削減できます。
ネットワークの枝刈りは、各層でのパラメーターおよび活性化の範囲統計に影響を与えるため、量子化されたネットワークの精度が変わる可能性があります。この違いを調べるには、枝刈りされたネットワークを量子化し、量子化されたネットワークを使用して推論を実行します。
データをキャリブレーション データ セットと検証データ セットに分割します。
calibrationDataStore = splitEachLabel(imdsTrain,0.1,'randomize');
validationDataStore = imdsValidation;dlquantizer オブジェクトを作成し、枝刈りされたネットワークを量子化用のネットワークとして指定します。
prunedNet = addLayers(prunedDLNet, net.Layers(end)); prunedNet = connectLayers(prunedNet, "fc", "softmax"); prunedNet = initialize(prunedNet); quantObjPrunedNetwork = dlquantizer(prunedNet,'ExecutionEnvironment','GPU');
関数 calibrate を使用して、キャリブレーション データでネットワークを実行し、各層での重み、バイアス、および活性化の範囲統計を収集します。
calResults = calibrate(quantObjPrunedNetwork, calibrationDataStore)
calResults=22×5 table
"imageinput_Max" 'imageinput' "Max" 255 255
"imageinput_Min" 'imageinput' "Min" 0 0
"conv_1_Weights" 'conv_1' "Weights" -0.4615 1.1026
"conv_1_Bias" 'conv_1' "Bias" -0.0317 0.0616
"conv_2_Weights" 'conv_2' "Weights" -0.4954 0.5707
"conv_2_Bias" 'conv_2' "Bias" -0.0701 0.2057
"conv_3_Weights" 'conv_3' "Weights" -0.4555 0.4644
"conv_3_Bias" 'conv_3' "Bias" -0.1829 0.2202
"fc_Weights" 'fc' "Weights" -0.2931 0.2760
"fc_Bias" 'fc' "Bias" -0.2268 0.1514
"imageinput_input" 'imageinput' "Input" 0 255
"imageinput" 'imageinput' "Activations" 0 1
"conv_1" 'conv_1' "Activations" -0.9414 7.1667
"relu_1" 'relu_1' "Activations" 0 7.1667
⋮
検証手順を実行するように検証メトリクス関数を設定した dlquantizationOptions オブジェクトを作成します。
dlquantOpts = dlquantizationOptions;
dlquantOpts.MetricFcn = {@(x)hAccuracyMetric(x,net,validationDataStore)}dlquantOpts =
dlquantizationOptions with properties:
Validation Metric Info
MetricFcn: {[@(x)hAccuracyMetric(x,net,validationDataStore)]}
Validation Environment Info
Target: 'host'
Bitstream: ''
関数 validate を使用し、検証データ セットを使用したネットワークの量子化前後の結果を比較します。
valResults = validate(quantObjPrunedNetwork, validationDataStore, dlquantOpts);
検証出力の MetricResults.Result フィールドを調べ、量子化後のネットワークの精度を確認します。
valResults.MetricResults.Result
ans=2×2 table
'Floating-Point' 0.9316
'Quantized' 0.9296
サポート関数
ミニ バッチ前処理関数
関数 preprocessMiniBatch は、入力 cell 配列からイメージ データを抽出することで予測子のミニバッチを前処理し、数値配列に連結します。グレースケール入力では、4 番目の次元でデータを連結することにより、3 番目の次元が各イメージに追加されます。この次元は、シングルトン チャネル次元として使用されることになります。
function X = preprocessMiniBatch(XCell) % Extract image data from cell and concatenate. X = cat(4,XCell{:}); end
モデル精度関数
dlnetwork の分類精度を評価します。精度は、ネットワークによって正しく分類されたラベルの割合です。
function accuracy = evaluateAccuracy(dlnet,mbqValidation,classes,trueLabels) YPred = modelPredictions(dlnet,mbqValidation,classes); accuracy = mean(YPred == trueLabels); end
SynFlow スコア関数
関数 calculateSynFlowScore は、Synaptic Flow (SynFlow) スコアを計算します。シナプス サリエンシー [2] は、損失の勾配にパラメーター値を乗じた積で定義される勾配ベースのスコアのクラスとして説明されます。
*
SynFlow スコアは、すべてのネットワーク出力の合計を損失関数として使用するシナプス サリエンシー スコアです。
は、ニューラル ネットワークによって表される関数です。
はネットワークのパラメーターです。
はネットワークへの入力配列です。
この損失関数に対するパラメーター勾配を計算するには、関数 dlfeval とモデル勾配関数を使用します。
function score = calculateSynFlowScore(dlnet,dlX) dlnet.Learnables = dlupdate(@abs, dlnet.Learnables); gradients = dlfeval(@modelGradients,dlnet,dlX); score = dlupdate(@(g,w)g.*w, gradients, dlnet.Learnables); end
SynFlow スコア用のモデル勾配
function gradients = modelGradients(dlNet,inputArray) % Evaluate the gradients on a given input to the dlnetwork dlYPred = predict(dlNet,inputArray, "Outputs","fc"); pseudoloss = sum(dlYPred,'all'); gradients = dlgradient(pseudoloss,dlNet.Learnables); end
Magnitude スコア関数
関数 calculateMagnitudeScore は、パラメーターの要素ごとの絶対値として定義された Magnitude スコアを返します。
function score = calculateMagnitudeScore(dlnet) score = dlupdate(@abs, dlnet.Learnables); end
マスク生成関数
関数 calculateMask は、指定されたスコアとスパース性目標に基づいて、ネットワーク パラメーターのバイナリ マスクを返します。
function mask = calculateMask(scoresMagnitude,sparsity) % Compute a binary mask based on the parameter-wise scores such that the mask contains a percentage of zeros as specified by sparsity. % Flatten the cell array of scores into one long score vector flattenedScores = cell2mat(cellfun(@(S)extractdata(gather(S(:))),scoresMagnitude.Value,'UniformOutput',false)); % Rank the scores and determine the threshold for removing connections for the % given sparsity flattenedScores = sort(flattenedScores); k = round(sparsity*numel(flattenedScores)); if k==0 thresh = 0; else thresh = flattenedScores(k); end % Create a binary mask mask = dlupdate( @(S)S>thresh, scoresMagnitude); end
モデル予測関数
関数 modelPredictions は、dlnetwork オブジェクト dlnet、入力データ mbq の minibatchqueue、ネットワーク クラスを入力として受け取り、minibatchqueue オブジェクトに含まれるすべてのデータを反復処理することによってモデル予測を計算します。この関数は、関数 onehotdecode を使用して、スコアが最も高い予測されたクラスを見つけます。
function predictions = modelPredictions(dlnet,mbq,classes) predictions = []; while hasdata(mbq) dlXTest = next(mbq); dlYPred = softmax(predict(dlnet,dlXTest)); YPred = onehotdecode(dlYPred,classes,1)'; predictions = [predictions; YPred]; end reset(mbq) end
枝刈り関数の適用
関数 createPrunedNet は、指定された枝刈りアルゴリズムと反復で枝刈りした dlnetwork を返します。
function prunedNet = createPrunedNet(dlnet,selectedIteration,pruningMaskSynFlow,pruningMaskMagnitude,pruningMethod) switch pruningMethod case "Magnitude" prunedNet = dlupdate(@(W,M)W.*M, dlnet, pruningMaskMagnitude{selectedIteration}); case "SynFlow" prunedNet = dlupdate(@(W,M)W.*M, dlnet, pruningMaskSynFlow{selectedIteration}); end end
枝刈り統計関数
関数 pruningStatistics は、層レベルのスパース性、枝刈りされるフィルターやニューロンの数といった、詳細な層レベルの枝刈り統計を抽出します。
sparsityPerLayer - percentage of parameters pruned in each layer (各層での枝刈りされたパラメーターの割合)
prunedChannelsPerLayer - 枝刈りの結果として削除できるようになる各層のチャネルおよびニューロンの数
numOutChannelsPerLayer - 各層のチャネルおよびニューロンの数
function [sparsityPerLayer,prunedChannelsPerLayer,numOutChannelsPerLayer,layerNames] = pruningStatistics(dlnet) layerNames = unique(dlnet.Learnables.Layer,'stable'); numLayers = numel(layerNames); layerIDs = zeros(numLayers,1); for idx = 1:numel(layerNames) layerIDs(idx) = find(layerNames(idx)=={dlnet.Layers.Name}); end sparsityPerLayer = zeros(numLayers,1); prunedChannelsPerLayer = zeros(numLayers,1); numOutChannelsPerLayer = zeros(numLayers,1); numParams = zeros(numLayers,1); numPrunedParams = zeros(numLayers,1); for idx = 1:numLayers layer = dlnet.Layers(layerIDs(idx)); % Calculate the sparsity paramIDs = strcmp(dlnet.Learnables.Layer,layerNames(idx)); paramValue = dlnet.Learnables.Value(paramIDs); for p = 1:numel(paramValue) numParams(idx) = numParams(idx) + numel(paramValue{p}); numPrunedParams(idx) = numPrunedParams(idx) + nnz(extractdata(paramValue{p})==0); end % Calculate channel statistics sparsityPerLayer(idx) = numPrunedParams(idx)/numParams(idx); switch class(layer) case "nnet.cnn.layer.FullyConnectedLayer" numOutChannelsPerLayer(idx) = layer.OutputSize; prunedChannelsPerLayer(idx) = nnz(all(layer.Weights==0,2)&layer.Bias(:)==0); case "nnet.cnn.layer.Convolution2DLayer" numOutChannelsPerLayer(idx) = layer.NumFilters; prunedChannelsPerLayer(idx) = nnz(reshape(all(layer.Weights==0,[1,2,3]),[],1)&layer.Bias(:)==0); case "nnet.cnn.layer.GroupedConvolution2DLayer" numOutChannelsPerLayer(idx) = layer.NumGroups*layer.NumFiltersPerGroup; prunedChannelsPerLayer(idx) = nnz(reshape(all(layer.Weights==0,[1,2,3]),[],1)&layer.Bias(:)==0); otherwise error("Unknown layer: "+class(layer)) end end end
数字データ セット読み込み関数
loadDigitDataset 関数は、数字データ セットを読み込み、データを学習データと検証データに分割します。
function [imdsTrain, imdsValidation] = loadDigitDataset() digitDatasetPath = fullfile(matlabroot,'toolbox','nnet','nndemos', ... 'nndatasets','DigitDataset'); imds = imageDatastore(digitDatasetPath, ... 'IncludeSubfolders',true,'LabelSource','foldernames'); [imdsTrain, imdsValidation] = splitEachLabel(imds,0.75,"randomized"); end
数字認識ネットワーク学習関数
関数 trainDigitDataNetwork は、グレースケール イメージの数字を分類するために畳み込みニューラル ネットワークに学習させます。
function net = trainDigitDataNetwork(imdsTrain,imdsValidation) layers = [ imageInputLayer([28 28 1],"Normalization","rescale-zero-one") convolution2dLayer(3,8,'Padding','same') reluLayer maxPooling2dLayer(2,'Stride',2) convolution2dLayer(3,16,'Padding','same') reluLayer maxPooling2dLayer(2,'Stride',2) convolution2dLayer(3,32,'Padding','same') reluLayer fullyConnectedLayer(10) softmaxLayer]; % Specify the training options options = trainingOptions('sgdm', ... 'InitialLearnRate',0.01, ... 'MaxEpochs',10, ... 'Shuffle','every-epoch', ... 'ValidationData',imdsValidation, ... 'ValidationFrequency',30, ... 'Verbose',false, ... 'Plots','none',"ExecutionEnvironment","auto"); % Train network net = trainnet(imdsTrain,layers,"crossentropy",options); end
メトリクス関数
hAccuracyMetric 関数を使用して、量子化後のネットワークを検証します。
function metricOutput = hAccuracyMetric(predictionScores, ~, dataStore) % Evaluate the accuracy of the network % Extract the ground truth categorical labels from the datastore labelData = dataStore.Labels; % one hot encode the label data YTruth = onehotencode(labelData, 2)'; % Get the predicted label index from the ground truth [~, gtIDs] = max(YTruth, [], 1); % Get the predicted label index [~, predictedIDs] = max(predictionScores, [], 1); % Evaluating the accuracy of the network metricOutput = extractdata(sum(gtIDs == predictedIDs)/ numel(gtIDs)); end
参考文献
[1] Song Han, Jeff Pool, John Tran, and William J. Dally. 2015."Learning Both Weights and Connections for Efficient Neural Networks." Advances in Neural Information Processing Systems 28 (NIPS 2015): 1135–1143.
[2] Hidenori Tanaka, Daniel Kunin, Daniel L. K. Yamins, and Surya Ganguli 2020. "Pruning Neural Networks Without Any Data by Iteratively Conserving Synaptic Flow." 34th Conference on Neural Information Processing Systems (NeurlPS 2020)
参考
関数
dlarray|dlquantizer|predict|dlnetwork