このページの内容は最新ではありません。最新版の英語を参照するには、ここをクリックします。
深層ニューラル ネットワークの量子化
デジタル ハードウェアでは、数値はバイナリ ワードで格納されます。バイナリ ワードとは固定長の連続ビット (1 と 0) です。この 1 と 0 の連続をハードウェア コンポーネントやソフトウェア関数が解釈する方法はデータ型によって定義されます。数値は、スケーリングされた整数 (通常は固定小数点と呼ばれる) または浮動小数点データ型として表現されます。
事前学習済みのニューラル ネットワークと Deep Learning Toolbox™ を使用して学習させたニューラル ネットワークのほとんどで、単精度浮動小数点データ型が使用されます。小規模な学習済みニューラル ネットワークであっても大量のメモリが必要であり、浮動小数点演算を実行可能なハードウェアが必要です。このような制限が、低消費電力のマイクロコントローラーや FPGA への深層学習機能の展開を妨げている可能性があります。
Deep Learning Toolbox Model Quantization Library サポート パッケージを使用すれば、ネットワークを量子化して 8 ビットにスケーリングされた整数データ型を使用できます。
深層学習ネットワークを量子化して GPU、FPGA、または CPU 環境に展開するために必要な製品については、量子化ワークフローのシステム要件を参照してください。
精度と範囲
スケーリングされた 8 ビット整数データ型は、単精度浮動小数点データ型に比べて精度と範囲が制限されます。サイズが大きい浮動小数点データ型からサイズが小さい固定長のデータ型に数値をキャストするときの、数値に関する考慮事項を以下に示します。
桁落ち: 桁落ちは丸め誤差です。桁落ちが起きると、値がそのデータ型で表現可能な最も近い数値に丸められます。同数の場合は、次のように丸められます。
正の数値は、正の無限大方向の最も近い表現可能な値に。
負の数値は、負の無限大方向の最も近い表現可能な値に。
MATLAB® では、関数
roundを使用してこのような丸めを実行できます。アンダーフロー: アンダーフローは桁落ちの一種です。アンダーフローは、値がデータ型によって表現可能な最小値より小さい場合に発生します。これが発生すると、値が 0 に飽和します。
オーバーフロー: 値がデータ型で表現可能な最大値より大きい場合にオーバーフローが発生します。オーバーフローが発生すると、値がデータ型で表現可能な最大値に飽和します。
ダイナミック レンジのヒストグラム
ディープ ネットワーク量子化器アプリを使用して、ネットワークの畳み込み層と全結合層の重みとバイアスのダイナミック レンジと、ネットワーク内のすべての層の活性化のダイナミック レンジを収集して可視化します。このアプリは、ネットワークの畳み込み層の重み、バイアス、および活性化にスケーリングされた 8 ビット整数データ型を割り当てます。また、これらのパラメーターのそれぞれのダイナミック レンジのヒストグラムを表示します。これらのヒストグラムの生成方法を以下の手順で説明します。
ネットワークの実行中に 1 つのパラメーターに記録される以下の値について検討します。
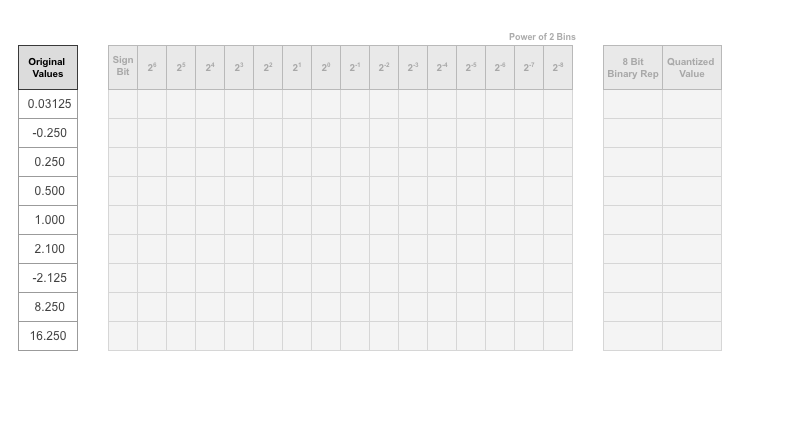
記録されるパラメーターの値ごとに理想的なバイナリ表現を探します。
最上位ビット (MSB) はバイナリ ワードの左端のビットです。このビットが数値に最も貢献します。各値の MSB が黄色で強調表示されます。
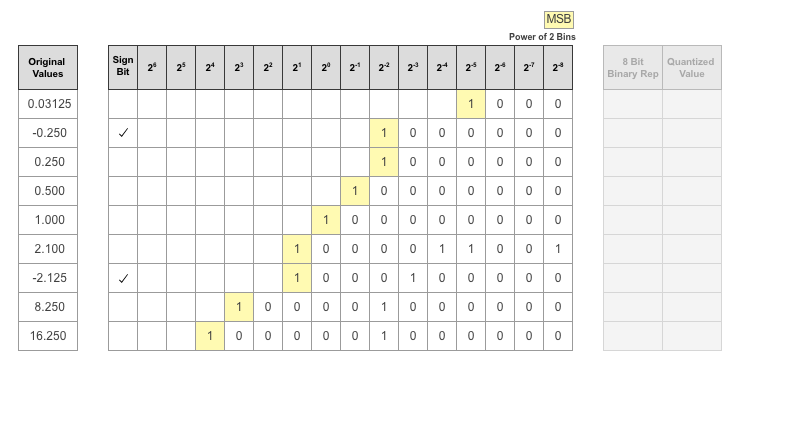
バイナリ ワードを整列させることによって、記録されたパラメーター値に使用されるビットの分布を把握することができます。緑で強調表示された各列の MSB の合計が、記録された値の集計ビューとして提供されます。
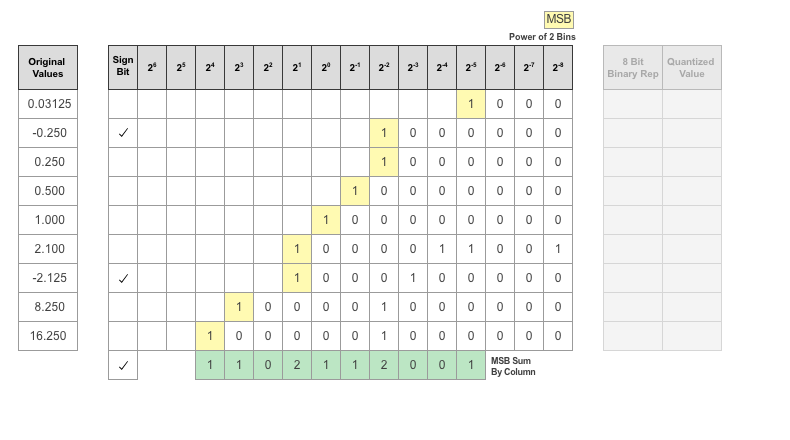
各ビット位置の MSB の数がヒート マップとして表示されます。このヒート マップでは、ビット位置内の MSB の数値が大きいと、より濃い青色で領域が示されます。
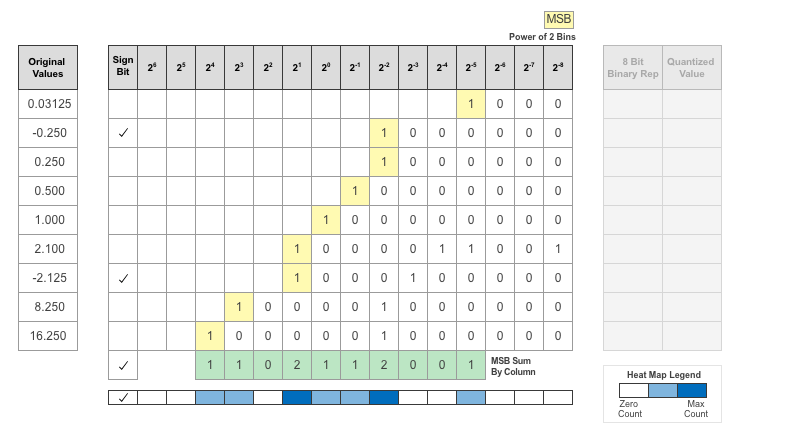
ディープ ネットワーク量子化器アプリは、オーバーフローを回避し、範囲をカバーし、アンダーフローを許可できるデータ型を割り当てます。値の符号属性を表現するには、追加の符号ビットが必要です。
次の図は、符号ビットを含む 23 ~ 2-3 のビットを表現するデータ型の例を示しています。
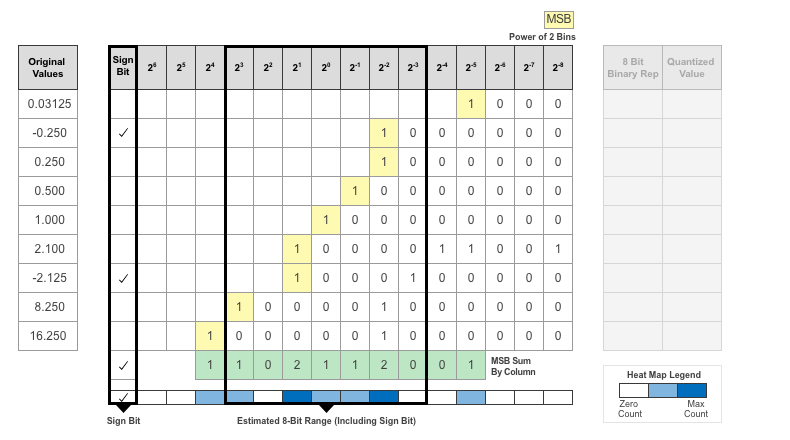
データ型を割り当てた後、そのデータ型以外のすべてのビットが削除されます。サイズが小さい固定長のデータ型が割り当てられているため、データ型で表現できない値に対して、桁落ち、オーバーフロー、アンダーフローが発生する可能性があります。
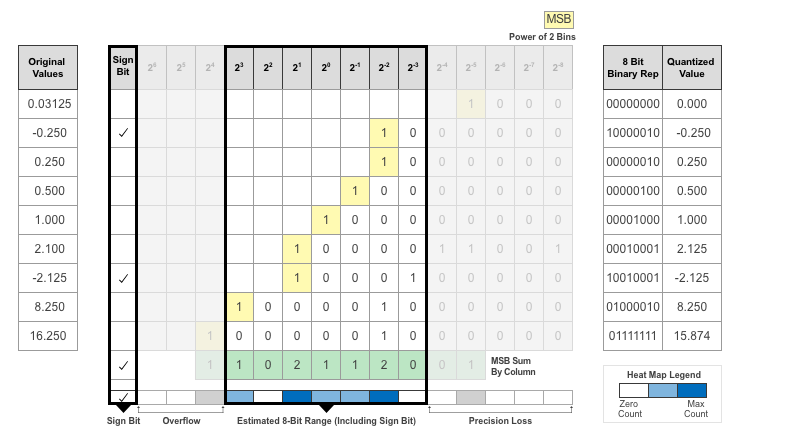
この例では、値 0.03125 でアンダーフローが発生するため、量子化された値は 0 になります。値 2.1 では桁落ちが発生するため、量子化された値は 2.125 になります。値 16.250 はそのデータ型で表現可能な最大値を上回っているため、オーバーフローが発生し、量子化された値は 15.874 に飽和します。

ディープ ネットワーク量子化器アプリは、ネットワークの畳み込み層と全結合層内の各学習可能パラメーターについて、このヒート マップ ヒストグラムを表示します。ヒストグラムの灰色の領域は、データ型では表現できないビットを表しています。
