wdenoise
ウェーブレット信号のノイズ除去
構文
説明
XDEN = wdenoise(___,Name=Value)xden = wdenoise(x,3,Wavelet="db2") は、Daubechies db2 ウェーブレットを使用して x をレベル 3 までノイズ除去します。
[ は、ノイズ除去後のウェーブレット係数とスケーリング係数を cell 配列 XDEN,DENOISEDCFS] = wdenoise(___)DENOISEDCFS で返します。DENOISEDCFS の要素は分解能の降順になります。DENOISEDCFS の最後の要素には Approximation (スケーリング) 係数が格納されます。
[ は、元のウェーブレット係数とスケーリング係数を cell 配列 XDEN,DENOISEDCFS,ORIGCFS] = wdenoise(___)ORIGCFS で返します。ORIGCFS の要素は分解能の降順になります。ORIGCFS の最後の要素には Approximation (スケーリング) 係数が格納されます。
例
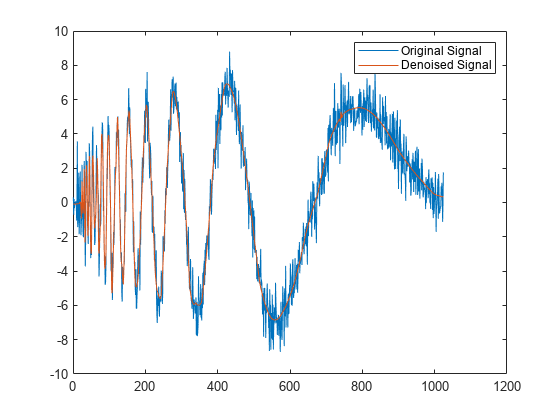
既定値を使用して、ノイズを含む信号のノイズ除去後のバージョンを求めます。
load noisdopp
xden = wdenoise(noisdopp);元の信号とノイズ除去後の信号をプロットします。
plot([noisdopp' xden']) legend("Original Signal","Denoised Signal")
ブロックしきい値処理を使用して、ノイズを含むデータの timetable をレベル 5 までノイズ除去します。
ノイズを含むデータセットを読み込みます。
load wnoisydataブロックしきい値処理を使用してデータのノイズをレベル 5 まで除去します。
xden = wdenoise(wnoisydata,5,DenoisingMethod="BlockJS");元のデータとノイズ除去後のデータをプロットします。
h1 = plot(wnoisydata.t,[wnoisydata.noisydata(:,1) xden.noisydata(:,1)]); h1(2).LineWidth = 2; legend("Original","Denoised")

信号のノイズを異なる方法で除去して結果を比較します。
信号のクリーンなバージョンとノイズを含むバージョンを含むデータ ファイルを読み込みます。信号をプロットします。
load fdata plot(fNoisy) hold on plot(fClean) grid on legend("Noisy","Clean") hold off

sym4 ウェーブレットと db1 ウェーブレットを使用して、9 レベル ウェーブレット分解で信号のノイズを除去します。結果をプロットします。
cleansym = wdenoise(fNoisy,9,Wavelet="sym4"); cleandb = wdenoise(fNoisy,9,Wavelet="db1"); figure subplot(2,1,1) plot(cleansym) title("Denoised - sym") grid on subplot(2,1,2) plot(cleandb) title("Denoised - db") grid on

ノイズ除去後の各信号の SNR を計算します。sym4 ウェーブレットを使用した方が正確な結果が得られることを確認します。
snrsym = -20*log10(norm(abs(fClean-cleansym))/norm(fClean))
snrsym = 35.9623
snrdb = -20*log10(norm(abs(fClean-cleandb))/norm(fClean))
snrdb = 32.2672
ノイズを含む 100 個の時系列のデータを含むファイルを読み込みます。各時系列は fClean のノイズを含むバージョンです。時系列のノイズ除去を 2 回実行し、それぞれの場合のノイズ分散を推定します。
load fdataTS cleanTSld = wdenoise(fdataTS,9,NoiseEstimate="LevelDependent"); cleanTSli = wdenoise(fdataTS,9,NoiseEstimate="LevelIndependent");
ノイズを含むいずれかの時系列について、対応するノイズ除去後の 2 つのバージョンと比較します。
figure plot(fdataTS.Time,fdataTS.fTS15) title("Original") grid on

figure subplot(2,1,1) plot(cleanTSli.Time,cleanTSli.fTS15) title("Level Independent") grid on subplot(2,1,2) plot(cleanTSld.Time,cleanTSld.fTS15) title("Level Dependent") grid on

入力引数
名前と値の引数
出力引数
アルゴリズム
ノイズを含む信号の最も一般的なモデルは次の形式になります。
n は時間で、等間隔になります。この最も簡単なモデルにおいて、e(n) がガウス ホワイト ノイズ N(0,1) で、ノイズ レベル σ が 1 に等しいとします。ノイズ除去の目的は、信号 s のノイズ部分を抑制し、f を復元することです。
ノイズ除去手順には 3 つのステップがあります。
分解 — ウェーブレットを選択し、レベル
Nを選択します。信号 s のレベルNのウェーブレット分解を計算します。Detail 係数のしきい値処理 — 1 から
Nまでの各レベルで、しきい値を選択し、Detail 係数にソフトなしきい値処理を適用します。再構成 — レベル
Nの元の Approximation 係数とレベル 1 からNまでの変更後の Detail 係数に基づいて、ウェーブレットの再構成を計算します。
しきい値選択ルールの詳細については、Wavelet Denoising and Nonparametric Function Estimationおよび関数 thselect のヘルプを参照してください。
参照
[1] Abramovich, F., Y. Benjamini, D. L. Donoho, and I. M. Johnstone. “Adapting to Unknown Sparsity by Controlling the False Discovery Rate.” Annals of Statistics, Vol. 34, Number 2, pp. 584–653, 2006.
[2] Antoniadis, A., and G. Oppenheim, eds. Wavelets and Statistics. Lecture Notes in Statistics. New York: Springer Verlag, 1995.
[3] Cai, T. T. “On Block Thresholding in Wavelet Regression: Adaptivity, Block size, and Threshold Level.” Statistica Sinica, Vol. 12, pp. 1241–1273, 2002.
[4] Donoho, D. L. “Progress in Wavelet Analysis and WVD: A Ten Minute Tour.” Progress in Wavelet Analysis and Applications (Y. Meyer, and S. Roques, eds.). Gif-sur-Yvette: Editions Frontières, 1993.
[5] Donoho, D. L., I. M. Johnstone. “Ideal Spatial Adaptation by Wavelet Shrinkage.” Biometrika, Vol. 81, pp. 425–455, 1994.
[6] Donoho, D. L. “De-noising by Soft-Thresholding.” IEEE Transactions on Information Theory, Vol. 42, Number 3, pp. 613–627, 1995.
[7] Donoho, D. L., I. M. Johnstone, G. Kerkyacharian, and D. Picard. “Wavelet Shrinkage: Asymptopia?” Journal of the Royal Statistical Society, series B, Vol. 57, No. 2, pp. 301–369, 1995.
[8] Johnstone, I. M., and B. W. Silverman. “Needles and Straw in Haystacks: Empirical Bayes Estimates of Possibly Sparse Sequences.” Annals of Statistics, Vol. 32, Number 4, pp. 1594–1649, 2004.
拡張機能
バージョン履歴
R2017b で導入