classify
説明
例
CSV ファイル factoryReports から学習データを読み取ります。このファイルには、各レポートの説明テキストとカテゴリカル ラベルを含む工場レポートが格納されています。
filename = "factoryReports.csv"; data = readtable(filename,TextType="string"); head(data)
Description Category Urgency Resolution Cost
_____________________________________________________________________ ____________________ ________ ____________________ _____
"Items are occasionally getting stuck in the scanner spools." "Mechanical Failure" "Medium" "Readjust Machine" 45
"Loud rattling and banging sounds are coming from assembler pistons." "Mechanical Failure" "Medium" "Readjust Machine" 35
"There are cuts to the power when starting the plant." "Electronic Failure" "High" "Full Replacement" 16200
"Fried capacitors in the assembler." "Electronic Failure" "High" "Replace Components" 352
"Mixer tripped the fuses." "Electronic Failure" "Low" "Add to Watch List" 55
"Burst pipe in the constructing agent is spraying coolant." "Leak" "High" "Replace Components" 371
"A fuse is blown in the mixer." "Electronic Failure" "Low" "Replace Components" 441
"Things continue to tumble off of the belt." "Mechanical Failure" "Low" "Readjust Machine" 38
table の Category 列のラベルを categorical 値に変換します。
data.Category = categorical(data.Category);
データを学習セットとテスト セットに分割します。ホールドアウトの割合を 10% に指定します。
cvp = cvpartition(data.Category,Holdout=0.1); dataTrain = data(cvp.training,:); dataTest = data(cvp.test,:);
table からテキスト データとラベルを抽出します。
textDataTrain = dataTrain.Description; textDataTest = dataTest.Description; TTrain = dataTrain.Category; TTest = dataTest.Category;
bertDocumentClassifier 関数を使用して、事前学習済みの BERT-Base 文書分類器を読み込みます。
classNames = categories(data.Category); mdl = bertDocumentClassifier(ClassNames=classNames)
mdl =
bertDocumentClassifier with properties:
Network: [1×1 dlnetwork]
Tokenizer: [1×1 bertTokenizer]
ClassNames: ["Electronic Failure" "Leak" "Mechanical Failure" "Software Failure"]
学習オプションを指定します。学習オプションの中から選択するには、経験的解析が必要です。実験を実行してさまざまな学習オプションの構成を調べるには、実験マネージャー (Deep Learning Toolbox)アプリを使用できます。
Adam オプティマイザーを使用して学習させます。
学習を 8 エポック行います。
微調整を行うため、学習率を下げます。学習率 0.0001 を使用して学習させます。
すべてのエポックでデータをシャッフルします。
学習の進行状況をプロットで監視し、精度メトリクスを監視します。
詳細出力を無効にします。
options = trainingOptions("adam", ... MaxEpochs=8, ... InitialLearnRate=1e-4, ... Shuffle="every-epoch", ... Plots="training-progress", ... Metrics="accuracy", ... Verbose=false);
trainBERTDocumentClassifier 関数を使用してニューラル ネットワークに学習させます。既定では、trainBERTDocumentClassifier 関数は利用可能な GPU がある場合にそれを使用します。GPU での学習には、Parallel Computing Toolbox™ ライセンスとサポートされている GPU デバイスが必要です。サポートされているデバイスの詳細については、GPU 計算の要件 (Parallel Computing Toolbox)を参照してください。そうでない場合、関数 trainBERTDocumentClassifier は CPU を使用します。実行環境を指定するには、ExecutionEnvironment 学習オプションを使用します。
mdl = trainBERTDocumentClassifier(textDataTrain,TTrain,mdl,options);
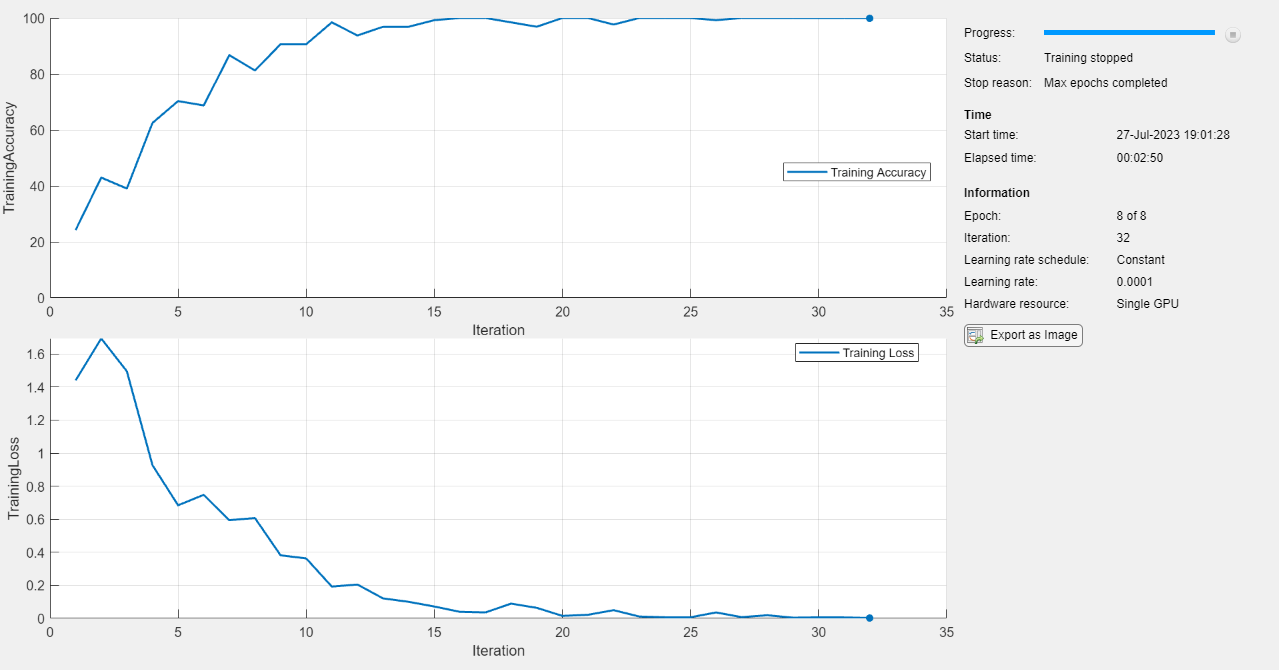
テスト データを使用して予測を行います。
YTest = classify(mdl,textDataTest);
テスト予測の分類精度を計算します。
accuracy = mean(TTest == YTest)
accuracy = 0.9375
入力引数
名前と値の引数
出力引数
バージョン履歴
R2023b で導入
参考
trainBERTDocumentClassifier | bertDocumentClassifier | bert | dlnetwork (Deep Learning Toolbox) | bertTokenizer
トピック
- BERT 文書分類器の学習
- 深層学習を使用したテキスト データの分類
- 分類用の単純なテキスト モデルの作成
- トピック モデルを使用したテキスト データの解析
- マルチワード フレーズを使用したテキスト データの解析
- 深層学習を使用したシーケンスの分類 (Deep Learning Toolbox)
- MATLAB による深層学習 (Deep Learning Toolbox)