mnrval
(非推奨) 多項ロジスティック回帰の値
mnrval は推奨されません。代わりに、fitmnr を使用して MultinomialRegression モデル オブジェクトを作成してから、オブジェクト関数 predict を使用してください。 (R2023a 以降)詳細については、バージョン履歴を参照してください。
構文
説明
例
ノミナル結果の多項回帰を当てはめて、カテゴリ確率を推定します。
標本データを読み込みます。
load fisheriris列ベクトル species は、3 種類のアヤメ (setosa、versicolor、virginica) で構成されています。double 行列 meas は、花に関する 4 種類の測定値、がく片の長さと幅 (cm) と花弁の長さと幅 (cm) で構成されています。
ノミナル応答変数を定義します。
sp = nominal(species); sp = double(sp);
この場合、sp で、1、2、3 はそれぞれ、setosa、versicolor、virginica という種類を表します。
ノミナル モデルを当てはめ、花の測定値を予測子変数として使用して種類を推定します。
[B,dev,stats] = mnrfit(meas,sp);
測定値 (6.3, 2.8, 4.9, 1.7) をもつアヤメの花の特定の種類である確率を推定します。
x = [6.3, 2.8, 4.9, 1.7]; pihat = mnrval(B,x); pihat
pihat = 1×3
0 0.3977 0.6023
測定値 (6.3, 2.8, 4.9, 1.7) をもつアヤメの花が setosa である確率は 0、versicolor である確率は 0.3977、virginica である確率は 0.6023 です。
カテゴリ間に自然な順序があるカテゴリカル応答について、多項回帰モデルを当てはめます。次に、カテゴリ確率推定に対する信頼限界の上限と下限を推定します。
標本データを読み込み、予測子変数を定義します。
load('carbig.mat')
X = [Acceleration Displacement Horsepower Weight];予測子変数は、自動車の速度、エンジン排気量、馬力および重量です。応答変数は、ガロンあたりの走行マイル数 (MPG) です。
MPG を 9 ~ 48 mpg の 4 つの水準に分類する順序応答変数を作成します。
miles = ordinal(MPG,{'1','2','3','4'},[],[9,19,29,39,48]);
miles = double(miles);miles では、1 はガロンあたりの走行マイル数が 9 ~ 19 の自動車を、2 はガロンあたりの走行マイル数が 20 ~ 29 の自動車を示します。同様に、3 と 4 はそれぞれガロンあたりの走行マイル数が 30 ~ 39 と 40 ~ 48 の自動車を示します。
応答変数 miles の多項回帰モデルを当てはめます。順序モデルの場合、既定の 'link' は logit で、既定の 'interactions' は 'off' です。
[B,dev,stats] = mnrfit(X,miles,'model','ordinal');
= (12、113、110、2670) である自動車のガロンあたりの走行マイル数に対する確率信頼区間の確率推定値と 95% の誤差範囲を計算します。
x = [12,113,110,2670]; [pihat,dlow,hi] = mnrval(B,x,stats,'model','ordinal'); pihat
pihat = 1×4
0.0615 0.8426 0.0932 0.0027
カテゴリ確率推定に対する信頼限界を計算します。
LL = pihat - dlow; UL = pihat + hi; [LL;UL]
ans = 2×4
0.0073 0.7829 0.0283 -0.0003
0.1157 0.9022 0.1580 0.0057
ノミナル結果の多項回帰を当てはめて、カテゴリ カウントを推定します。
標本データを読み込みます。
load fisheriris列ベクトル species は、3 種類のアヤメ setosa、versicolor、virginica で構成されています。double 行列 meas は、花に関する 4 種類の測定値、がく片の長さと幅 (cm) と花弁の長さと幅 (cm) で構成されています。
ノミナル応答変数を定義します。
sp = nominal(species); sp = double(sp);
この場合、sp で、1、2、3 はそれぞれ、setosa、versicolor、virginica という種類を表します。
ノミナル モデルを当てはめ、花の測定値に基づいて種類を推定します。
[B,dev,stats] = mnrfit(meas,sp);
測定値 (6.3, 2.8, 4.9, 1.7) をもつ 100 本のアヤメの標本について、それぞれの種類のカテゴリ数を推定します。
x = [6.3, 2.8, 4.9, 1.7]; yhat = mnrval(B,x,18)
yhat = 1×3
0 7.1578 10.8422
カウントの誤差範囲を推定します。
[yhat,dlow,hi] = mnrval(B,x,18,stats,'model','nominal');
カテゴリ確率推定に対する信頼限界を計算します。
LL = yhat - dlow; UL = yhat + hi; [LL;UL]
ans = 2×3
0 3.3019 6.9863
0 11.0137 14.6981
1 つの予測子変数と、3 つのカテゴリをもつ 1 つのカテゴリカル応答変数を含む標本データを作成します。
x = [-3 -2 -1 0 1 2 3]';
Y = [1 11 13; 2 9 14; 6 14 5; 5 10 10;...
5 14 6; 7 13 5; 8 11 6];
[Y x]ans = 7×4
1 11 13 -3
2 9 14 -2
6 14 5 -1
5 10 10 0
5 14 6 1
7 13 5 2
8 11 6 3
予測子変数 x の 7 つの異なる値に関する観測があります。応答変数 Y には 3 つのカテゴリがあり、データには、x の観測ごとに、25 の個体のうち、Y の各カテゴリに含まれる数が示されます。たとえば、x が -3 の場合、25 個のうち 1 個がカテゴリ 1、11 個がカテゴリ 2、13 個がカテゴリ 3 として観測されます。同様に、x が 1 の場合、5 個がカテゴリ 1、14 個がカテゴリ 2、6 個がカテゴリ 3 として観測されます。
積み重ね表示棒グラフに、各カテゴリの数と x 値をプロットします。
bar(x,Y,'stacked');
ylim([0 25]);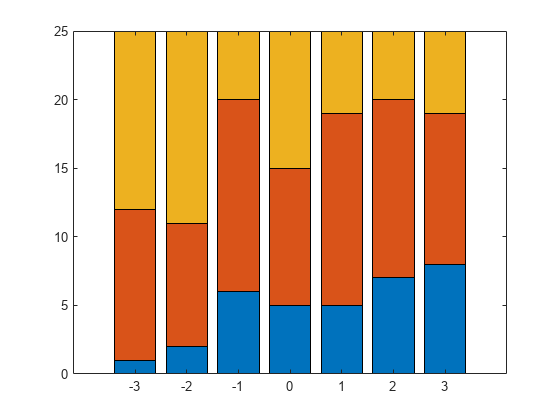
個体の応答カテゴリ確率に対するノミナル モデルを、カテゴリごとに単一の予測子変数 x で個別の傾きを使用して当てはめます。
betaHatNom = mnrfit(x,Y,'model','nominal',... 'interactions','on')
betaHatNom = 2×2
-0.6028 0.3832
0.4068 0.1948
betaHatOrd の最初の行には、最初の 2 つの応答カテゴリの切片項が含まれます。2 番目の行には傾きが含まれます。mnrfit は 3 番目のカテゴリを基準カテゴリとして受け入れるため、3 番目のカテゴリの係数はゼロと見なされます。
3 つの応答カテゴリに対する予測確率を計算します。
xx = linspace(-4,4)'; piHatNom = mnrval(betaHatNom,xx,'model','nominal',... 'interactions','on');
3 番目のカテゴリになる確率は、単純に 1 - P( = 1) - P( = 2) です。
棒グラフに、各カテゴリの推定累積数をプロットします。
line(xx,cumsum(25*piHatNom,2),'LineWidth',2);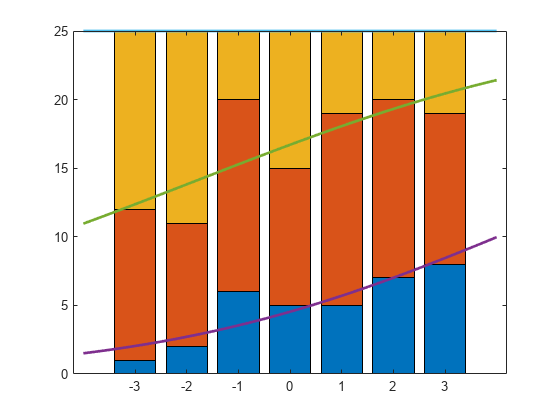
3 番目のカテゴリに対する累積確率は常に 1 です。
累積応答カテゴリ確率の "平行" 順序のモデルを、すべてのカテゴリで共通する、単一の予測子変数 x の傾きを使用して当てはめます。
betaHatOrd = mnrfit(x,Y,'model','ordinal',... 'interactions','off')
betaHatOrd = 3×1
-1.5001
0.7266
0.2642
betaHatOrd の最初の 2 つの要素は、最初の 2 つの応答カテゴリの切片項です。betaHatOrd の最後の要素は共通の傾きです。
最初の 2 つの応答カテゴリに対する予測累積確率を計算します。3 番目のカテゴリに対する累積確率は常に 1 です。
piHatOrd = mnrval(betaHatOrd,xx,'type','cumulative',... 'model','ordinal','interactions','off');
観測された累積数の棒グラフに推定累積数をプロットします。
figure() bar(x,cumsum(Y,2),'grouped'); ylim([0 25]); line(xx,25*piHatOrd,'LineWidth',2);
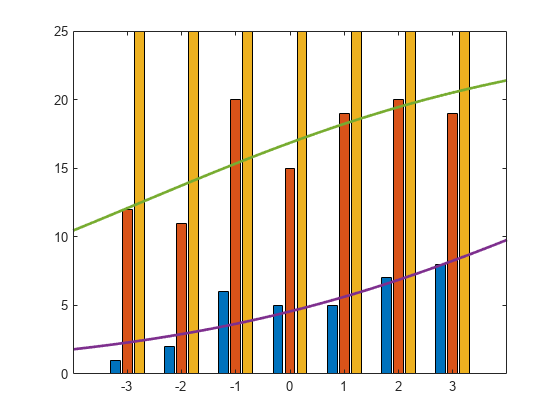
入力引数
名前と値の引数
出力引数
参照
[1] McCullagh, P., and J. A. Nelder. Generalized Linear Models. New York: Chapman & Hall, 1990.