mnrfit
(非推奨) 多項ロジスティック回帰
説明
B = mnrfit(X,Y,Name,Value)Name,Value ペア引数で指定された追加オプションを使用して、多項モデルの当てはめに対する係数推定値の行列 B を返します。
たとえば、ノミナル モデル、順序モデル、階層モデルを当てはめるか、リンク関数を変更できます。
例
ノミナル結果の多項回帰を当てはめ、結果を解釈します。
標本データを読み込みます。
load fisheriris列ベクトル species は、3 種類のアヤメ setosa、versicolor、virginica で構成されています。double 行列 meas は、花に関する 4 種類の測定値、がく片の長さと幅 (cm) と花弁の長さと幅 (cm) で構成されています。
categorical 配列を使用してノミナル応答変数を定義します。
sp = categorical(species);
多項回帰モデルを当てはめ、測定値を使用して種類を予測します。
[B,dev,stats] = mnrfit(meas,sp); B
B = 5×2
103 ×
2.0184 0.0426
0.6739 0.0025
-0.5682 0.0067
-0.5164 -0.0094
-2.7609 -0.0183
これは、4 つのすべての予測子において個別の傾き、つまり meas の各カテゴリをもつ、応答カテゴリ相対リスクのノミナル モデルです。B の最初の行には、最初の 2 つの応答カテゴリ (setosa および versicolor と基準カテゴリ virginica) の相対リスクの切片項が含まれます。最後の 4 つの行には、最初の 2 つのカテゴリのモデルに対する傾きが含まれます。mnrfit は 3 番目のカテゴリを基準カテゴリとして受け入れます。
アヤメの花が種類 2 (versicolor) である場合と種類 3 (virginica) である場合の相対リスクは、2 つの確率 (種類 2 である確率と種類 3 である確率) の比率です。相対リスクのモデルは次のようになります。
係数は、相対リスクに対する予測子変数の影響と、あるカテゴリに含まれる確率と基準カテゴリに含まれる確率の対数オッズの両方を表します。たとえば、他の条件がすべて等しい場合、推定された係数 2.5 は、1 番目の測定値 が 1 単位増加すると、種類 3 (virginica) になる場合に対する種類 2 (versicolor) になる場合の相対リスクが exp(2.5) 倍になることを示します。他の条件がすべて等しい場合、 が 1 単位増加すると、virginica ではなく versicolor になる相対的な対数オッズは 2.5 倍になります。
係数が無限大または負の無限大に収束する場合、推定される係数はオペレーティング システムによってわずかに異なる可能性があります。
モデル係数の統計的な有意性を確認します。
stats.p
ans = 5×2
0 0.0000
0 0.0281
0 0.0000
0 0.0000
0 0.0000
小さい 値は、virginica ではなく setosa になる (種類 3 と比較した種類 1 の) 相対的なリスクおよび virginica ではなく versicolor になる (種類 3 と比較した種類 2 の) 相対的なリスクに関してすべての尺度が有意であることを示します。
係数推定値の標準誤差を要求します。
stats.se
ans = 5×2
12.4038 5.2719
3.5783 1.1228
3.1760 1.4789
3.5403 1.2934
7.1203 2.0967
係数に対する 95% の信頼限界を計算します。
LL = stats.beta - 1.96.*stats.se; UL = stats.beta + 1.96.*stats.se;
setosa である場合と virginica である場合の相対リスクのモデルの係数に対する信頼区間 (B の係数の最初の列) を表示します。
[LL(:,1) UL(:,1)]
ans = 5×2
103 ×
1.9941 2.0427
0.6668 0.6809
-0.5744 -0.5620
-0.5234 -0.5095
-2.7749 -2.7470
versicolor である場合と virginica である場合の相対リスクのモデルの係数に対する信頼区間 (B の係数の 2 番目の列) を見つけます。
[LL(:,2) UL(:,2)]
ans = 5×2
32.3049 52.9707
0.2645 4.6660
3.7823 9.5795
-11.9644 -6.8944
-22.3957 -14.1766
カテゴリ間に自然な順序があるカテゴリカル応答について、多項回帰モデルを当てはめます。
標本データを読み込み、予測子変数を定義します。
load carbig
X = [Acceleration Displacement Horsepower Weight];予測子変数は、自動車の速度、エンジン排気量、馬力および重量です。応答変数は、ガロンあたりの走行マイル数 (mpg) です。
応答値 9 ~ 19 を 1、20 ~ 29 を 2、30 ~ 39 を 3 および 40 ~ 48 のように 4 の範囲でラベル付けすることで、MPG を 9 から 48 までの 4 つの水準に分類する順序応答変数を作成します。
miles = discretize(MPG,[9,19,29,39,48]);
応答変数 miles の順序応答モデルを当てはめます。
[B,dev,stats] = mnrfit(X,miles,'model','ordinal'); B
B = 7×1
-16.6895
-11.7208
-8.0606
0.1048
0.0103
0.0645
0.0017
B の最初の 3 つの要素はモデルの切片項で、B の最後の 4 つの要素は共変量の係数です。これらはすべてのカテゴリに共通であると仮定します。このモデルは、"並列回帰" ("比例オッズ" モデルとも呼ばれます) に対応します。モデルのカテゴリ間の切片は異なりますが、傾きは共通しています。これは、順序モデルの既定値である 'interactions','off' の名前と値のペア引数を使用して指定できます。
[B(1:3)'; repmat(B(4:end),1,3)]
ans = 5×3
-16.6895 -11.7208 -8.0606
0.1048 0.1048 0.1048
0.0103 0.0103 0.0103
0.0645 0.0645 0.0645
0.0017 0.0017 0.0017
モデルのリンク関数は、順序モデルの既定値である logit ('link','logit') です。係数は、自動車の mpg が特定の値以下である場合とその値よりも大きい場合の相対リスクまたは対数オッズを表します。
この例の比例オッズ モデルは以下のようになります。
たとえば、係数推定値 0.1048 は、他のすべてが一定であるとして、速度での 1 単位の変更が、自動車の mpg が 19 以下である場合と 19 を超える場合、29 以下である場合と 29 を超える場合、39 以下である場合と 39 を超える場合のオッズに exp(0.01048) の係数で影響することを示します。
係数の有意性を評価します。
stats.p
ans = 7×1
0.0000
0.0000
0.0000
0.1899
0.0350
0.0000
0.0118
エンジン排気量、馬力および自動車の重量についての 値 0.035、0.0000 および 0.0118 は、自動車の mpg が特定の値より大きくなるのではなくその値以下になるオッズに関して、これらの因子が有意であることを示しています。
階層型多項回帰モデルを当てはめます。
標本データを読み込みます。
load('smoking.mat');データ セット smoking には、次の 5 つの変数があります。性別、年齢、重量、収縮期血圧、拡張期血圧です。性別はバイナリ変数で、1 は女性患者、0 は男性患者を示します。
応答変数を定義します。
Y = categorical(smoking.Smoker);
Smoker のデータには次の 4 つのカテゴリが含まれています。
0:非喫煙者、1 日に 0 本
1:喫煙者、1 日に 1 ~ 5 本
2:喫煙者、1 日に 6 ~ 10 本
3:喫煙者、1 日に 11 本以上
予測子変数を定義します。
X = [smoking.Sex smoking.Age smoking.Weight...
smoking.SystolicBP smoking.DiastolicBP];階層型多項モデルを当てはめます。
[B,dev,stats] = mnrfit(X,Y,'model','hierarchical'); B
B = 6×3
43.8148 5.9571 44.0712
1.8709 -0.0230 0.0662
0.0188 0.0625 0.1335
0.0046 -0.0072 -0.0130
-0.2170 0.0416 -0.0324
-0.2273 -0.1449 -0.4824
B の最初の列には、非喫煙者と喫煙者である場合を比較した相対リスクのモデルについての切片と係数推定値が含まれます。2 番目の列には、対象者を喫煙者として、1 日 1 ~ 5 本吸う場合と、1 日 6 本以上吸う場合の対数オッズをモデル化するパラメーター推定が含まれています。最後の 3 番目の列には、対象者が 1 日 6 本以上吸う喫煙者とすると、1 日 6 ~ 10 本以上吸う場合と、1 日 11 本以上吸う場合の対数オッズをモデル化するパラメーター推定が含まれています。
係数はカテゴリ間で異なります。これは、階層モデルの既定値である 'interactions','on' の名前と値のペア引数を使用して指定できます。したがって、この例のモデルは以下のようになります。
たとえば、1.8709 の係数推定値は、他のすべてが一定であることを条件に、喫煙者である場合と非喫煙者である場合の尤度が、性別が女性から男性へ変わると exp(1.8709) = 6.49 倍ずつ増えることを示します。
項の統計的な有意性を評価します。
stats.p
ans = 6×3
0.0000 0.5363 0.2149
0.3549 0.9912 0.9835
0.6850 0.2676 0.2313
0.9032 0.8523 0.8514
0.0009 0.5187 0.8165
0.0004 0.0483 0.0545
性別、年齢、体重は、どの水準においても有意性がありません。0.0009 および 0.0004 という 値は、喫煙者である場合と非喫煙者である場合の相対リスクにおいて両方のタイプの血圧が有意であることを示しています。0.0483 という 値は、1 日に 0 ~ 5 本吸う人と 1 日に 5 本より多く吸う人のオッズに対して拡張期血圧のみが有意であることを示しています。同様に、0.0545 という 値は、1 日に 6 ~ 10 本吸う人と 1 日に 10 本より多く吸う人のオッズに対して拡張期血圧が有意であることを示しています。
有意でない因子が相関するかどうかを確認します。性別でグループ分けされた年齢と体重の散布図を描画します。
figure() gscatter(smoking.Age,smoking.Weight,smoking.Sex) legend('Male','Female') xlabel('Age') ylabel('Weight')
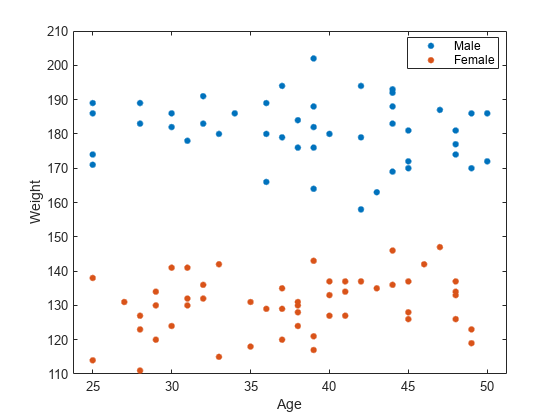
個人の体重の範囲は、性別によって異なるように見えます。年齢は、性別や体重との明らかな相関はないようです。年齢は有意ではありませんが、体重は性別と相関しているようなので、両方を排除して、モデルを再構築できます。
モデルから年齢と体重を排除し、予測子変数として性別、収縮期血圧、拡張期血圧を使用する階層モデルを当てはめます。
X = double([smoking.Sex smoking.SystolicBP... smoking.DiastolicBP]); [B,dev,stats] = mnrfit(X,Y,'model','hierarchical'); B
B = 4×3
44.8456 5.3230 25.0248
1.6045 0.2330 0.4982
-0.2161 0.0497 0.0179
-0.2222 -0.1358 -0.3092
ここで、1.6045 の係数推定値は、非喫煙者である場合と喫煙者である場合の尤度が、性別が男性から女性へ変わると exp(1.6045) = 4.97 倍増えることを示します。収縮期血圧における単位の増加は、非喫煙者である場合と喫煙者ある場合の尤度が exp(–.2161) = 0.8056 減少することを示します。同様に、拡張期血圧における単位の増加は、非喫煙者である場合と喫煙者ある場合の相対リスクが exp(–.2222) = 0.8007 減少することを示します。
項の統計的な有意性を評価します。
stats.p
ans = 4×3
0.0000 0.4715 0.2325
0.0210 0.7488 0.6362
0.0010 0.4107 0.8899
0.0003 0.0483 0.0718
0.0210、0.0010、0.0003 という 値は、モデルの他の項が与えられた場合に、非喫煙者と喫煙者の相対リスクに対して性別および両方のタイプの血圧の項が有意であることを示しています。0.0483 という 値に基づくと、対象者が喫煙者であることを条件にして、1 日に 1 ~ 5 本吸う場合と 1 日に 5 本より多く吸う場合の相対リスクに対して拡張期血圧は有意であるように見えます。3 番目の列の 値はどれも 0.05 未満ではないため、この対象者が 1 日に 5 本より多く吸うことを条件にして、6 ~ 10 本吸う場合と 10 本より多く吸う場合の相対リスクに対して、どの変数も統計的に有意ではないことがわかります。
入力引数
名前と値の引数
出力引数
アルゴリズム
mnrfit は、X または Y 内の NaN を欠損値として扱い、無視します。
参照
[1] McCullagh, P., and J. A. Nelder. Generalized Linear Models. New York: Chapman & Hall, 1990.
[2] Long, J. S. Regression Models for Categorical and Limited Dependent Variables. Sage Publications, 1997.
[3] Dobson, A. J., and A. G. Barnett. An Introduction to Generalized Linear Models. Chapman and Hall/CRC. Taylor & Francis Group, 2008.