manova1
1 因子多変量分散分析 (MANOVA)
説明
例
carbig データ セットを読み込みます。
load carbigグループ平均ベクトルを含んでいる空間の次元、および対応する "p" 値を計算します。
[d,p] = manova1([MPG Acceleration Weight Displacement],...
Origin)d = 3
p = 4×1
0.0000
0.0000
0.0075
0.1934
出力は、平均ベクトルが統計的に同じであるという帰無仮説を棄却するだけの十分な証拠があることを示しています。ただし、平均ベクトルが同じ 3 次元空間にあるという帰無仮説を棄却するだけの十分な証拠はありません。
fisheriris データ セットを読み込みます。
load fisheriris;列ベクトル species には、3 種類のアヤメの種 (setosa、versicolor、virginica) が格納されています。行列 meas には、花に関する 4 種類の測定値、がく片の長さと幅 (cm) と花弁の長さと幅 (cm) が格納されています。
1 因子 MANOVA を実行して、4 つの測定値の平均のベクトルが 3 つの花の種のいずれでも同じであるという帰無仮説を検定します。有意水準を指定します。3 種類の花の種のベクトルを含んでいる空間の次元、対応する "p" 値、および MANOVA の追加統計量を計算します。
[d,p,stats] = manova1(meas,species,0.01)
d = 2
p = 2×1
10-7 ×
0.0000
0.5786
stats = struct with fields:
W: [4×4 double]
B: [4×4 double]
T: [4×4 double]
dfW: 147
dfB: 2
dfT: 149
lambda: [2×1 double]
chisq: [2×1 double]
chisqdf: [2×1 double]
eigenval: [4×1 double]
eigenvec: [4×4 double]
canon: [150×4 double]
mdist: [150×1 double]
gmdist: [3×3 double]
gnames: {3×1 cell}
出力は、3 つの種の平均のベクトルが 2 次元空間に格納されていることを示しています。この結果は、ベクトルの 1 つが他とは統計的に異なることを示します。stats 構造体に MANOVA の追加統計量が格納されています。
MANOVA の正準応答データを検証します。
C = stats.canon
C = 150×4
-8.0618 0.3004 0.1583 -0.2290
-7.1287 -0.7867 0.7466 0.4909
-7.4898 -0.2654 -0.0957 0.5471
-6.8132 -0.6706 -0.6908 0.4402
-8.1323 0.5145 -0.3944 -0.2742
-7.7019 1.4617 -0.1331 -0.6035
-7.2126 0.3558 -0.8867 0.6096
-7.6053 -0.0116 -0.1736 -0.1893
-6.5606 -1.0152 -0.5653 0.9595
-7.3431 -0.9473 -0.0253 -0.1415
-8.3974 0.6474 0.3436 -0.8188
-7.2193 -0.1096 -1.0583 -0.1948
-7.3268 -1.0730 0.1690 0.1914
-7.5725 -0.8055 -0.5953 0.9841
-9.8498 1.5859 1.6503 -1.0085
⋮
C の各列が正準変数に対応し、各行に X の同じ行に対応する変換されたデータ点が格納されます。正準変数の詳細については、正準変数を参照してください。
1 つ目と 2 つ目の正準変数を使用して散布図を作成します。
gscatter(C(:,1),C(:,2),species)
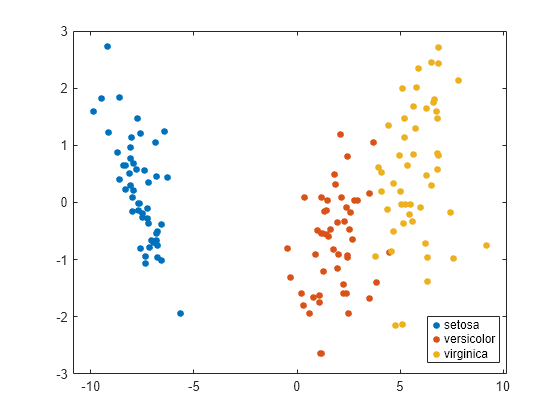
散布図にデータの主要なクラスターが 2 つ示されます。一方のクラスターに setosa の測定値が含まれ、もう一方に versicolor と virginica の測定値が含まれています。この結果からも、3 つの種の平均のベクトルが 2 次元空間に格納されていることがわかります。
入力引数
出力引数
詳細
アルゴリズム
manova1 は、d の取り得る値のそれぞれについて検定統計量を計算することで d を求めます。検定統計量の式は次のとおりです。
ここで、"n" は観測値の数、"l" は因子の水準の数、"r" は応答変数の数、 はウィルクスのラムダです。ウィルクスのラムダの詳細については、反復測定の多変量分散分析を参照してください。
d が取り得る最大の値は、応答変数の数か、因子の水準の数から 1 を引いた値の小さい方になります。d は、"p" が alpha で指定された有意水準を下回る最大の値です。
代替機能
manova1 を使用する代わりに、関数 manova を使用して manova オブジェクトを作成してから、オブジェクト関数 barttest を使用してグループ平均を含んでいる空間の次元を計算できます。関数 manova を使用する利点は次のとおりです。
2 因子および N 因子の MANOVA のサポート
因子と応答のデータに対する table のサポート
当てはめられる MANOVA モデルの係数、誤差の自由度、応答の共分散行列などについての
manovaオブジェクトの追加プロパティ
参照
[1] Krzanowski, Wojtek. J. Principles of Multivariate Analysis: A User's Perspective. New York: Oxford University Press, 1988.
[2] Morrison, Donald F. Multivariate Statistical Methods. 2nd ed, McGraw-Hill, 1976.
バージョン履歴
R2006a より前に導入