canoncorr
正準相関
構文
説明
例
標本データ セットの正準相関分析を行います。
データ セット carbig には、1970 ~ 1982 年の 406 台の自動車に関する測定値が含まれています。
標本データを読み込みます。
load carbig;
data = [Displacement Horsepower Weight Acceleration MPG];排気量、馬力、および重量の観測値の行列として X を定義し、加速度と MPG の観測値の行列として Y を定義します。データが不足している行は省略します。
nans = sum(isnan(data),2) > 0; X = data(~nans,1:3); Y = data(~nans,4:5);
標本の正準相関を計算します。
[A,B,r,U,V] = canoncorr(X,Y);
X の正準変数を構成する排気量、馬力、および重量の線形結合を判定するため、A の出力を表示します。
A
A = 3×2
0.0025 0.0048
0.0202 0.0409
-0.0000 -0.0027
A(3,1) は非常に小さいため、—0.000 と表示されています。A(3,1) のみ表示します。
A(3,1)
ans = -2.4737e-05
X の最初の正準変数は、u1 = 0.0025*Disp + 0.0202*HP — 0.000025*Wgt です。
X の 2 番目の正準変数は、u2 = 0.0048*Disp + 0.0409*HP — 0.0027*Wgt です。
Y の正準変数を構成する加速度と MPG の線形結合を判定するため、B の出力を表示します。
B
B = 2×2
-0.1666 -0.3637
-0.0916 0.1078
Y の最初の正準変数は、v1 = —0.1666*Accel — 0.0916*MPG です。
Y の 2 番目の正準変数は、v2 = —0.3637*Accel + 0.1078*MPG です。
X と Y の正準変数のスコアを相互にプロットします。
t = tiledlayout(2,2); title(t,'Canonical Scores of X vs Canonical Scores of Y') xlabel(t,'Canonical Variables of X') ylabel(t,'Canonical Variables of Y') t.TileSpacing = 'compact'; nexttile plot(U(:,1),V(:,1),'.') xlabel('u1') ylabel('v1') nexttile plot(U(:,2),V(:,1),'.') xlabel('u2') ylabel('v1') nexttile plot(U(:,1),V(:,2),'.') xlabel('u1') ylabel('v2') nexttile plot(U(:,2),V(:,2),'.') xlabel('u2') ylabel('v2')
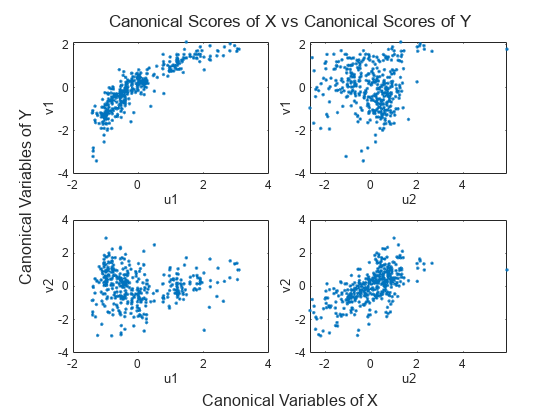
正準変数のペア は他のすべてのペアとは異なり、最も強い相関から最も弱い相関へと順番に並んでいます。
変数 u1 と v1 の相関係数を返します。
r(1)
ans = 0.8782
入力引数
出力引数
詳細
アルゴリズム
canoncorr は、qr と svd を使用して、A、B、および r を計算します。canoncorr は、U および V を U = (X—mean(X))*A および V = (Y—mean(Y))*B として計算します。
参照
[1] Krzanowski, W. J. Principles of Multivariate Analysis: A User's Perspective. New York: Oxford University Press, 1988.
[2] Seber, G. A. F. Multivariate Observations. Hoboken, NJ: John Wiley & Sons, Inc., 1984.
バージョン履歴
R2006a より前に導入