mahal
基準標本に対するマハラノビス距離
説明
例
相関二変量標本データ セットを生成します。
rng('default') % For reproducibility X = mvnrnd([0;0],[1 .9;.9 1],1000);
X の平均からユークリッド距離で等距離にある 4 つの観測値を指定します。
Y = [1 1;1 -1;-1 1;-1 -1];
X 内の基準標本に対する Y 内の各観測値のマハラノビス距離を計算します。
d2_mahal = mahal(Y,X)
d2_mahal = 4×1
1.1095
20.3632
19.5939
1.0137
X の平均に対する Y 内の各観測値の 2 乗ユークリッド距離を計算します。
d2_Euclidean = sum((Y-mean(X)).^2,2)
d2_Euclidean = 4×1
2.0931
2.0399
1.9625
1.9094
scatter を使用して、X と Y をプロットします。マーカーの色を使用して、X 内の基準標本に対する Y のマハラノビス距離を可視化します。
scatter(X(:,1),X(:,2),10,'.') % Scatter plot with points of size 10 hold on scatter(Y(:,1),Y(:,2),100,d2_mahal,'o','filled') hb = colorbar; ylabel(hb,'Mahalanobis Distance') legend('X','Y','Location','best')
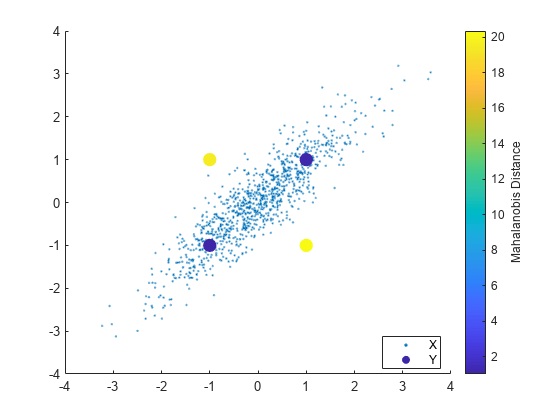
Y 内のすべての観測値 ([1,1]、[-1,-1,]、[1,-1] および [-1,1]) は、X の平均からユークリッド距離で等距離にあります。しかし、マハラノビス距離では、[1,1] と [-1,-1] は [1,-1] と [-1,1] よりはるかに X に近くなります。データの共分散および異なる変数のスケールが考慮されるので、マハラノビス距離は外れ値の検出に役立ちます。
入力引数
出力引数
詳細
ヒント
mahal関数を呼び出すと、基準標本の共分散行列が毎回計算されます。複数のデータ セットと同一の基準標本Xの間のマハラノビス距離を計算する場合は、Xの共分散行列を 1 回だけ計算し、それをpdist2関数に提供することで計算時間を節約できます。例については、マハラノビス距離の計算を参照してください。
バージョン履歴
R2006a より前に導入