線形解析のパフォーマンスの改善
この例では、関数 fastRestartForLinearAnalysis を使用して、Simulink® Control Design™ ソフトウェアの findop や linearize などのコンパイルを実行する関数の複数回の呼び出しを高速化する方法を説明します。
線形解析コマンドのループ内実行
この例では、閉ループのエンジン速度制御モデルの平衡化と線形化を行います。PI 制御パラメーターを変化させ、定常状態で閉ループ動作がどのように変化するかを観察します。linearize および findop はループ内で呼び出されるため、operspec の初回呼び出しを含め、モデルは 2*N + 1 回コンパイルされます。
エンジン速度制御モデルを開き、モデルから線形解析ポイントを取得します。
mdl = 'scdspeedctrl'; open_system(mdl) io = getlinio(mdl); fopt = findopOptions('DisplayReport','off');
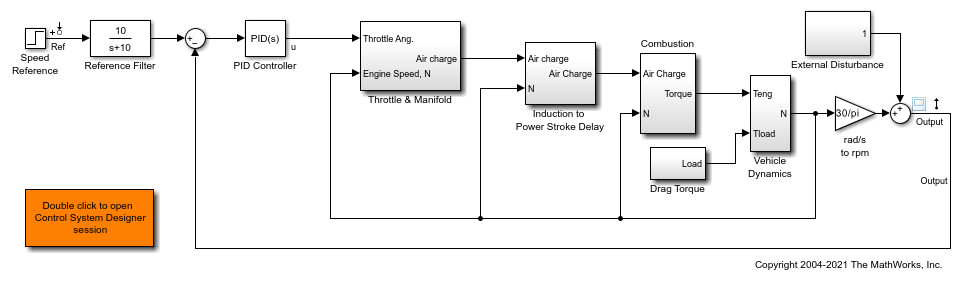
ベース ワークスペース変数 kp および ki を使用するように PI コントローラーを設定します。
blk = [mdl,'/PID Controller']; set_param(blk,'P','kp'); set_param(blk,'I','ki');
変化させるパラメーター値のグリッドを作成します。
vp = 0.0005:0.0005:0.003; vi = 0.0025:0.0005:0.005; [KP,KI] = ndgrid(vp,vi); N = numel(KP); sz = size(KP);
ベース ワークスペース変数を初期化します。
kp = KP(1); ki = KI(1);
ループを実行して実行時間を記録します。
t = cputime; ops = operspec(mdl); for i = N:-1:1 kp = KP(i); ki = KI(i); % Trim the model. op = findop(mdl,ops,fopt); [j,k] = ind2sub(sz,i); % Linearize the model. sysLoop(:,:,j,k) = linearize(mdl,io,op); end
経過時間を計算します。
timeElapsedLoop = cputime - t;
線形解析コマンドのバッチ実行
パラメーターに対してループを実行する代わりに findop と linearize でバッチ パラメーター変化の構造体を直接受け入れて、モデルのコンパイル回数を減らすことができます。この場合、モデルは operspec、findop、および linearize の呼び出しで 3 回コンパイルされます。
実行して実行時間を記録します。
t = cputime; ops = operspec(mdl);
バッチ パラメーター構造体を作成します。
params(1).Name = 'kp'; params(1).Value = KP ; params(2).Name = 'ki'; params(2).Value = KI ;
パラメーターのセット全体でモデルを平衡化します。
op = findop(mdl,ops,params,fopt);
パラメーターと操作点のセット全体でモデルを線形化します。
sysBatch = linearize(mdl,io,op,params);
経過時間を計算します。
timeElapsedBatch = cputime - t;
高速リスタートを使用した線形解析関数のループ内実行
関数 fastRestartForLinearAnalysis は、コンパイルを実行する関数がループ内で実行される場合でも、コンパイルを最小限に抑えるようにモデルを設定します。モデルはループ内での operspec、findop、および linearize の呼び出しでコンパイルされます。
線形解析の高速リスタートを有効にしてループを実行し、実行時間を記録します。
t = cputime;
線形解析の高速リスタートを有効にします。線形解析ポイントを指定して findop と linearize の呼び出し間でコンパイルを最小限にします。
fastRestartForLinearAnalysis(mdl,'on','AnalysisPoints',io);
モデルをループで平衡化および線形化します。
ops = operspec(mdl); for i = N:-1:1 kp = KP(i); ki = KI(i); % Trim the model. op = findop(mdl,ops,fopt); [j,k] = ind2sub(sz,i); % Linearize the model. sysFastRestartLoop(:,:,j,k) = linearize(mdl,io,op); end
線形解析の高速リスタートをオフにします。モデルのコンパイルが解除されます。
fastRestartForLinearAnalysis(mdl,'off');
経過時間を計算します。
timeElapsedFastRestartLoop = cputime - t;
高速リスタートを使用した線形解析関数のバッチ実行
線形解析の高速リスタートを有効にして関数 linearize および findop をバッチで実行すると、パフォーマンスをさらに向上させることができます。この場合、モデルは operspec、findop、および linearize の呼び出しで 1 回コンパイルされます。
線形解析の高速リスタートをオンにして実行し、実行時間を記録します。
t = cputime;
線形解析の高速リスタートを有効にします。線形解析ポイントを指定して findop と linearize の呼び出し間でコンパイルを最小限にします。
fastRestartForLinearAnalysis(mdl,'on','AnalysisPoints',io)
バッチ パラメーター構造体を作成します。
params(1).Name = 'kp'; params(1).Value = KP ; params(2).Name = 'ki'; params(2).Value = KI ;
パラメーターのセット全体でモデルを平衡化します。
ops = operspec(mdl); op = findop(mdl,ops,params,fopt);
パラメーターと操作点のセット全体でモデルを線形化します。
sysFastRestartBatch = linearize(mdl,io,op,params);
線形解析の高速リスタートを無効にします。モデルのコンパイルが解除されます。
fastRestartForLinearAnalysis(mdl,'off');
経過時間を計算します。
timeElapsedFastRestartBatch = cputime - t;
結果の比較
4 つの方法による線形化の結果を比較します。下記のボード線図は、それぞれの方法で同じ結果が返されることを示しています。
compareIdx = 1:N; bode(... sysLoop(:,:,compareIdx), ... sysBatch(:,:,compareIdx), ... sysFastRestartLoop(:,:,compareIdx), ... sysFastRestartBatch(:,:,compareIdx)); legend(... 'Loop Linearization', ... 'Batch Linearization', ... 'Loop Linearization with Fast Restart', ... 'Batch Linearization with Fast Restart')
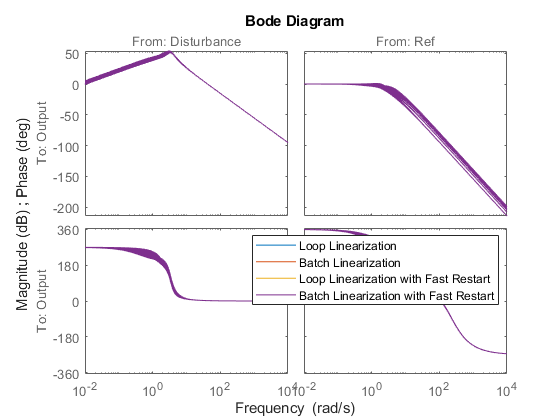
各方法について経過時間と高速化の比率を表にまとめます。バッチ平衡化および線形化と fastRestartForLinearAnalysis を使用することにより、パフォーマンスの著しい向上を図ることが可能です。
Method = ["Loop","Batch","Fast Restart Loop","Fast Restart Batch"]'; TimeElapsed = [timeElapsedLoop timeElapsedBatch ... timeElapsedFastRestartLoop timeElapsedFastRestartBatch]'; SpeedUpFactor = TimeElapsed(1)./TimeElapsed; TimeElapsedTable = table(Method,TimeElapsed,SpeedUpFactor)
TimeElapsedTable =
4×3 table
Method TimeElapsed SpeedUpFactor
____________________ ___________ _____________
"Loop" 25.28 1
"Batch" 7.56 3.3439
"Fast Restart Loop" 7.77 3.2535
"Fast Restart Batch" 7.09 3.5656
Simulink モデルを閉じます。
bdclose(mdl)