基本グリッド ワールドでの強化学習エージェントの学習
この例では、Q 学習エージェントと SARSA エージェントに学習させることにより、強化学習を使用してグリッド ワールド環境を解決する方法を示します。これらのエージェントの詳細については、Q 学習エージェントおよびSARSA エージェントを参照してください。
再現性のための乱数ストリームの固定
サンプル コードには、いくつかの段階で乱数の計算が含まれる場合があります。サンプル コード内の複数のセクションの先頭にある乱数ストリームを固定すると、実行するたびにセクション内の乱数シーケンスが維持されるため、結果が再現される可能性が高くなります。詳細については、Results Reproducibilityを参照してください。
シード 0 で乱数ストリームを固定し、メルセンヌ・ツイスター乱数アルゴリズムを使用します。乱数生成に使用されるシード制御の詳細については、rngを参照してください。
previousRngState = rng(0,"twister");出力 previousRngState は、ストリームの前の状態に関する情報が格納された構造体です。例の最後で、状態を復元します。
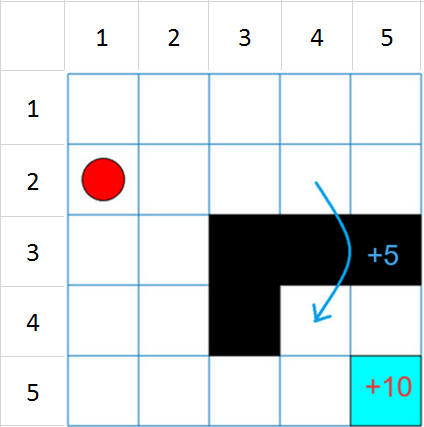
このグリッド ワールド環境は次の構成とルールをもちます。
境界線で囲まれた 5 行 5 列のグリッド ワールド。4 つのアクション (北 = 1、南 = 2、東 = 3、西 = 4) が可能。
エージェントはセル [2,1] (2 行目の 1 列目) から開始する。
セル [5,5] (青) の終了状態に到達すると、エージェントは報酬 +10 を受け取る。
環境には、セル [2,4] からセル [4,4] への、+5 の報酬を伴う特別なジャンプが含まれる。
エージェントは、障害物 (黒いセル) によってブロックされる。
他のすべてのアクションは報酬が -1 される。
グリッド ワールド環境の作成
基本グリッド ワールド環境を作成します。
env = rlPredefinedEnv("BasicGridWorld");エージェントの初期状態が常に [2,1] になるように指定するには、エージェントの初期状態の状態番号を返すリセット関数を作成します。この関数は、各学習エピソードとシミュレーションの開始時に呼び出されます。状態には [1,1] の位置から番号が付けられます。最初の列を下に移動し、その後の各列を下に移動するにしたがって、状態番号が増加します。したがって、初期状態を 2 に設定する無名関数ハンドルを作成します。
env.ResetFcn = @() 2;
getActionInfo関数とgetObservationInfo関数を使用して、環境からアクション仕様オブジェクトと観測仕様オブジェクトを抽出します。
actInfo = getActionInfo(env); obsInfo = getObservationInfo(env);
Q 学習エージェントの作成
Q 学習エージェントを作成するには、まずグリッド ワールド環境からの観測仕様とアクション仕様を使用して Q テーブルを作成します。オプティマイザーの学習率を 0.01 に設定します。
qTable = rlTable(obsInfo,actInfo);
エージェント内で Q 値関数を近似するには、テーブルと環境情報を使用して rlQValueFunction 近似器オブジェクトを作成します。
qFcnAppx = rlQValueFunction(qTable,obsInfo,actInfo);
次に、Q 値関数を使用して Q 学習エージェントを作成します。
qAgent = rlQAgent(qFcnAppx);
ε-greedy 探索や関数近似器の学習率などのエージェント オプションを構成します。
qAgent.AgentOptions.EpsilonGreedyExploration.Epsilon = .04; qAgent.AgentOptions.CriticOptimizerOptions.LearnRate = 0.01;
Q 学習エージェントの作成の詳細については、rlQAgentおよびrlQAgentOptionsを参照してください。
Q 学習エージェントの学習
エージェントに学習させるには、まず、学習オプションを指定します。この例では、次のオプションを使用します。
最大 200 個のエピソードに対して学習。各エピソードを最大 50 タイム ステップ持続するよう指定。
連続する 30 個のエピソードでエージェントが受け取った平均累積報酬が 11 になったときに学習を停止。
学習オプションの詳細については、rlTrainingOptionsを参照してください。
trainOpts = rlTrainingOptions;
trainOpts.MaxStepsPerEpisode = 50;
trainOpts.MaxEpisodes= 200;
trainOpts.StopTrainingCriteria = "AverageReward";
trainOpts.StopTrainingValue = 11;
trainOpts.ScoreAveragingWindowLength = 30;再現性のために乱数ストリームを固定します。
rng(0,"twister");関数trainを使用して Q 学習エージェントに学習させます。学習が完了するまでに数分かかる場合があります。この例の実行時間を節約するために、doTraining を false に設定して事前学習済みのエージェントを読み込みます。エージェントに学習させるには、doTraining を true に設定します。
doTraining =false; if doTraining % Train the agent. qTrainingStats = train(qAgent,env,trainOpts); else % Load the pretrained agent for the example. load("basicGWQAgent.mat","qAgent") end
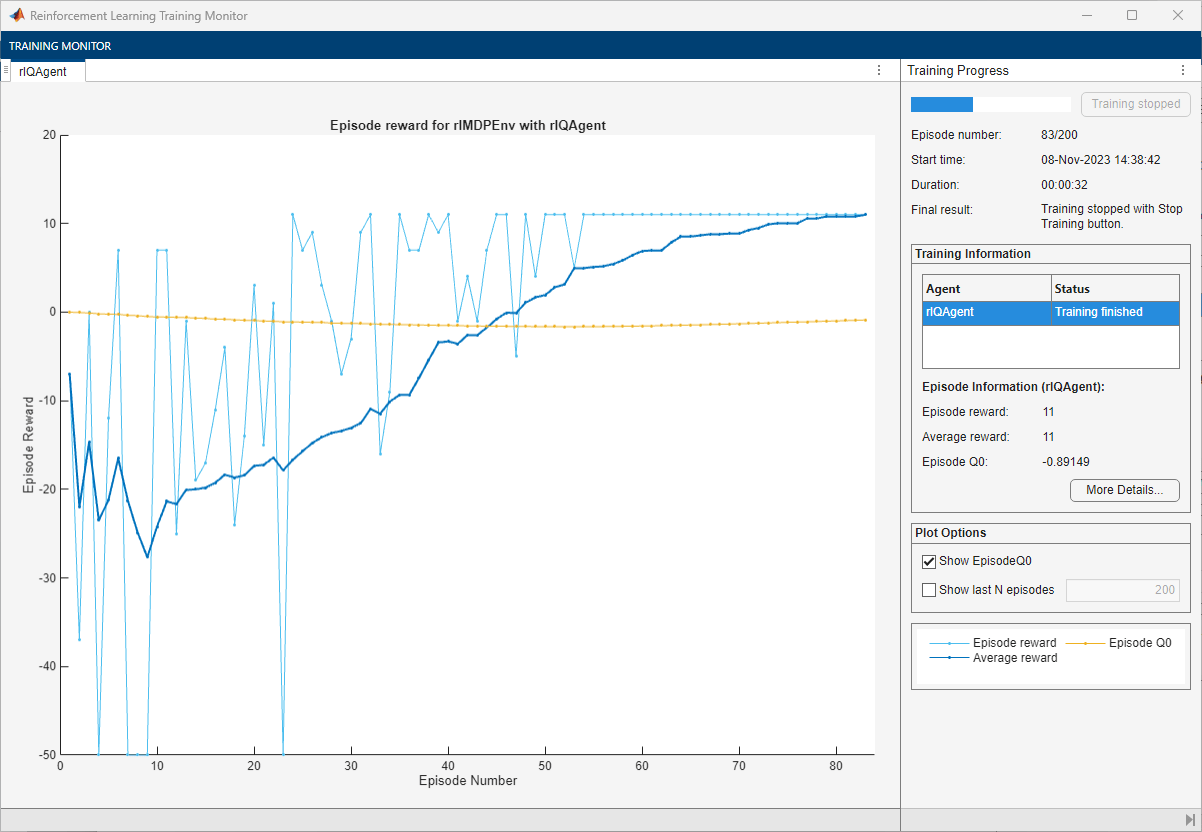
[強化学習の学習モニター] ウィンドウが開き、学習の進行状況が表示されます。
Q 学習の結果の検証
再現性のために乱数ストリームを固定します。
rng(0,"twister");既定では、エージェントはシミュレーション時に貪欲 (したがって決定的) 方策を使用します。代わりに探索方策を使用するには、UseExplorationPolicy エージェントのプロパティを true に設定します。
シミュレーションを実行する前に、環境を可視化し、エージェントの状態のトレースが維持されるように可視化を構成して、過去の既存のトレースがあればそれを消去します。
plot(env) env.Model.Viewer.ShowTrace = true; env.Model.Viewer.clearTrace;
関数simを使用して、環境内のエージェントをシミュレーションします。
sim(qAgent,env)
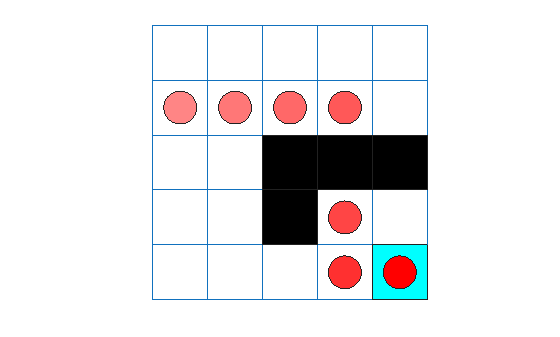
エージェントのトレースは、エージェントがセル [2,4] からセル [4,4] へのジャンプを正常に検出したことを示しています。
SARSA エージェントの作成と学習
SARSA エージェントを作成するには、Q 学習エージェントと同じ Q 値関数と ε-greedy 構成を使用します。SARSA エージェントの作成の詳細については、rlSARSAAgentおよびrlSARSAAgentOptionsを参照してください。
sarsaAgent = rlSARSAAgent(qFcnAppx); sarsaAgent.AgentOptions.EpsilonGreedyExploration.Epsilon = .04; sarsaAgent.AgentOptions.CriticOptimizerOptions.LearnRate = 0.01;
関数trainを使用して SARSA エージェントに学習させます。学習が完了するまでに数分かかる場合があります。この例の実行時間を節約するために、doTraining を false に設定して事前学習済みのエージェントを読み込みます。エージェントに学習させるには、doTraining を true に設定します。
doTraining =false; if doTraining % Train the agent. sarsaTrainingStats = train(sarsaAgent,env,trainOpts); else % Load the pretrained agent for the example. load("basicGWSarsaAgent.mat","sarsaAgent") end
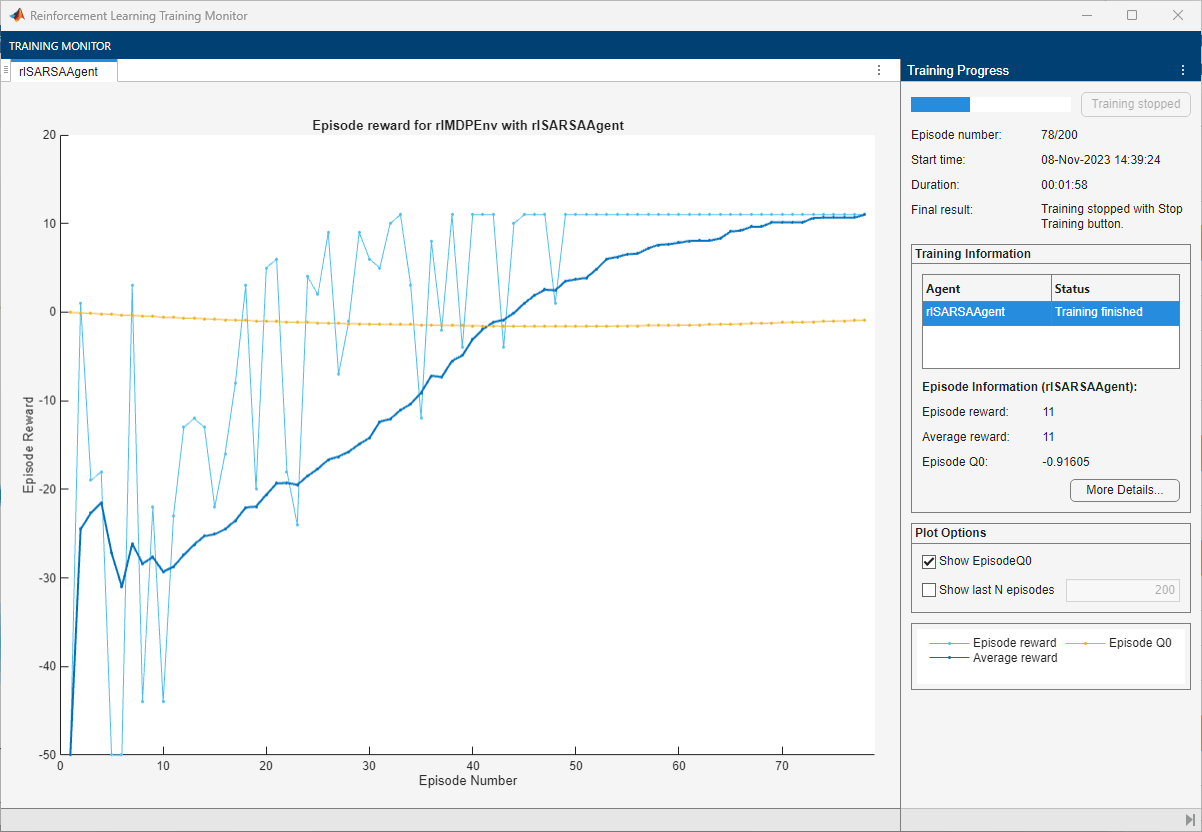
SARSA の学習の検証
再現性のために乱数ストリームを固定します。
rng(0,"twister");既定では、エージェントはシミュレーション時に貪欲 (したがって決定的) 方策を使用します。代わりに探索方策を使用するには、UseExplorationPolicy エージェントのプロパティを true に設定します。
シミュレーションを実行する前に、環境を可視化し、エージェントの状態のトレースが維持されるように可視化を構成します。
plot(env) env.Model.Viewer.ShowTrace = true; env.Model.Viewer.clearTrace;
環境内のエージェントをシミュレーションします。
sim(sarsaAgent,env)
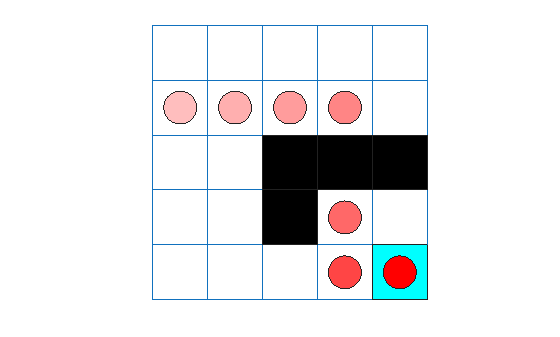
SARSA エージェントも、Q 学習エージェントと同じグリッド ワールドの解を見つけています。
previousRngState に保存されている情報を使用して、乱数ストリームを復元します。
rng(previousRngState);
参考
関数
createGridWorld|sim|train