rlMDPEnv
強化学習のためのマルコフ決定過程環境の作成
説明
マルコフ決定過程 (MDP) は、状態と観測値が有限空間に属し、確率的ルールが状態遷移を制御する離散時間の確率的制御プロセスです。これは、結果が部分的にランダムであり、部分的に判定者の制御下にある状況での判定をモデル化するための数学的なフレームワークを提供します。MDP は、強化学習を使用して解決された最適化問題を研究するのに役立ちます。rlMDPEnv を使用し、MATLAB® で強化学習のためのマルコフ決定過程環境を作成します。
プロパティ
オブジェクト関数
getActionInfo | Obtain action data specifications from reinforcement learning environment, agent, or experience buffer |
getObservationInfo | Obtain observation data specifications from reinforcement learning environment, agent, or experience buffer |
sim | Simulate trained reinforcement learning agents within specified environment |
train | Train reinforcement learning agents within a specified environment |
validateEnvironment | Validate custom reinforcement learning environment |
例
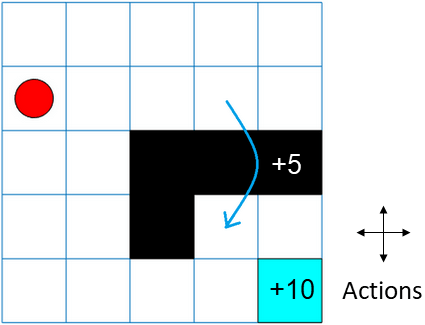
この例では、以下のルールをもつ 5 行 5 列のグリッド ワールド オブジェクトを作成します。
境界線で囲まれた 5 行 5 列のグリッド ワールド。取り得るアクションは次の 4 つ。北 = 1、南 = 2、東 = 3、西 = 4。
エージェントはセル [2,1] (図の赤い円で示した 2 行目の 1 列目) から開始する。
セル [5,5] (青いセル) の終了状態に到達すると、エージェントは報酬 +10 を受け取る。
環境には、セル [2,4] からセル [4,4] への、+5 の報酬を伴う特別なジャンプが含まれる (青い矢印)。
エージェントは、セル [3,3]、[3,4]、[3,5]、および [4,3] (黒いセル) の障害物によってブロックされる。
他のすべてのアクションは報酬が -1 される。
次に、このグリッドワールド オブジェクトを使用して、エージェントの学習とシミュレーションを行うための環境を作成します。
まず、関数 createGridWorld を使用して GridWorld オブジェクトを作成します。
gw = createGridWorld(5,5)
gw =
GridWorld with properties:
GridSize: [5 5]
CurrentState: "[1,1]"
States: [25×1 string]
Actions: [4×1 string]
T: [25×25×4 double]
R: [25×25×4 double]
ObstacleStates: [0×1 string]
TerminalStates: [0×1 string]
ProbabilityTolerance: 8.8818e-16
アクション名を表示します。
gw.Actions
ans = 4×1 string
"N"
"S"
"E"
"W"
次に、初期状態、終了状態、および障害物の状態を設定します。
gw.CurrentState = "[2,1]"; gw.TerminalStates = "[5,5]"; gw.ObstacleStates = ["[3,3]";"[3,4]";"[3,5]";"[4,3]"];
障害物の状態に関する状態遷移行列を更新します。
updateStateTranstionForObstacles(gw)
障害物の状態を飛び越えるジャンプ ルールを設定するには、まず、あらゆるアクションについて、状態 "[2,4]" からのすべての遷移を 0 にします。なお、1 つの行における各数値は特定のセルに移動する確率を表しているため、各行の数値の合計は常に 1 または 0 でなければなりません。そうでない場合はエラーがスローされます。
状態 "[2,4]" から遷移する確率を 0 に設定します。state2idx関数を使用して、状態 "[2,4]" に関連付けられたインデックスを取得します。
gw.T(state2idx(gw,"[2,4]"),:,:) = 0;次に、あらゆるアクションについて、状態 "[2,4]" から状態 "[4,4]" に遷移する確率を 1 に設定します。
gw.T(state2idx(gw,"[2,4]"),state2idx(gw,"[4,4]"),:) = 1;
次に、報酬遷移行列で報酬を定義します。
nS = numel(gw.States); nA = numel(gw.Actions); gw.R = -1*ones(nS,nS,nA); gw.R(state2idx(gw,"[2,4]"),state2idx(gw,"[4,4]"),:) = 5; gw.R(:,state2idx(gw,gw.TerminalStates),:) = 10;
rlMDPEnvを使用して、GridWorld オブジェクト gw からグリッド ワールド環境 env を作成します。
env = rlMDPEnv(gw)
env =
rlMDPEnv with properties:
Model: [1×1 rl.env.GridWorld]
ResetFcn: []
関数 plot を使用すると、グリッド ワールド環境を可視化できます。
plot(env)
action2idx関数を使用して、"E" アクションに関連付けられたインデックスを取得します。次に、環境のステップ関数を使用して、エージェントを東に移動させます。
[xn,rn,id]=step(env,action2idx(env.Model,"E"))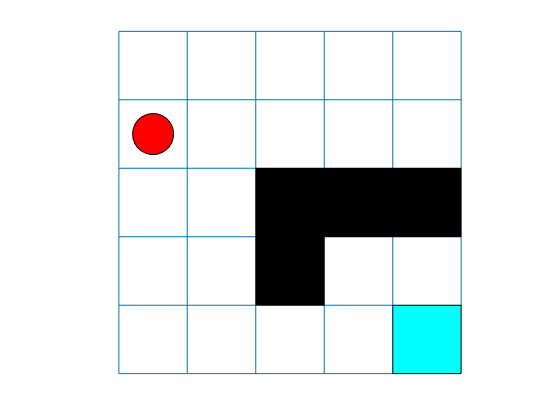
xn = 7
rn = -1
id = logical
0
idx2state関数を使用して、次の状態の名前を表示します。
idx2state(env.Model,xn)
ans = "[2,2]"
getActionInfo関数とgetObservationInfo関数を使用して、環境からアクション仕様オブジェクトと観測仕様オブジェクトを抽出します。
actInfo = getActionInfo(env)
actInfo =
rlFiniteSetSpec with properties:
Elements: [4×1 double]
Name: "MDP Actions"
Description: [0×0 string]
Dimension: [1 1]
DataType: "double"
obsInfo = getObservationInfo(env)
obsInfo =
rlFiniteSetSpec with properties:
Elements: [25×1 double]
Name: "MDP Observations"
Description: [0×0 string]
Dimension: [1 1]
DataType: "double"
これで、アクション仕様と観測仕様を使用して env 用のエージェントを作成し、train関数とsim関数を使用して環境内でのエージェントの学習とシミュレーションを行うことができるようになりました。
バージョン履歴
R2019a で導入
参考
関数
createMDP|createGridWorld|rlPredefinedEnv|getObservationInfo|getActionInfo|train|sim|rlCreateEnvTemplate|rlSimulinkEnv|createIntegratedEnv