Train Agent or Tune Environment Parameters Using Parameter Sweeping
This example shows how to train a reinforcement learning agent with the water tank reinforcement learning Simulink® environment by sweeping parameters. You can use this example as a template for tuning parameters when training reinforcement learning agents. To tune hyperparameters in the Reinforcement Learning Designer app, see Specify Hyperparameter Tuning Options. For an general example on how to tune a custom set of hyperparameters programmatically, using Bayesian optimization, see Tune Hyperparameters Using Bayesian Optimization.
Open a preconfigured project, which has all required files added as project dependencies. Opening the project also launches the Experiment Manager app.
TrainAgentUsingParameterSweepingStart
Note that it is best practice to add any Simulink models and supporting files as dependencies to your project.
Tune Agent Parameters Using Parameter Sweeping
In this section you tune the agent parameters to search for an optimal training policy.

Open Experiment
In the Experiment Browser pane double-click the name of the experiment
(TuneAgentParametersExperiment). This opens a tab for the experiment.The Hyperparameters section contains the hyperparameters to tune for this experiment. A set of hyperparameters has been added for this experiment. To add a new parameter, click Add and specify a name and array of values for the hyperparameter. When you run the experiment, Experiment Manager runs the training using every combination of parameter values specified in the hyperparameter table.
Verify that Strategy is set to
Exhaustive Sweep.Under Training Function, click Edit. The MATLAB® Editor opens to show code for the training function
TuneAgentParametersTraining. The training function creates the environment and agent objects and runs the training using one combination of the specified hyperparameters.
function output = TuneAgentParametersTraining(params,monitor) % Set the random seed generator rng(0); % Load the Simulink(R) model mdl = "rlwatertank"; load_system(mdl); % Create variables in the base workspace. When running on a parallel worker % this will also create variables in the base workspace of the worker. evalin("base","loadWaterTankParams"); Ts = evalin("base","Ts"); Tf = evalin("base","Tf"); % Create a reinforcement learning environment actionInfo = rlNumericSpec([1 1]); observationInfo = rlNumericSpec([3 1], ... LowerLimit=[-inf -inf 0 ]', ... UpperLimit=[ inf inf inf]'); blk = mdl + "/RL Agent"; env = rlSimulinkEnv(mdl, blk, observationInfo, actionInfo); % Specify a reset function for the environment env.ResetFcn = @localResetFcn; % Create options for the reinforcement learning agent. You can assign % values from the params struct for sweeping parameters. agentOpts = rlDDPGAgentOptions(); agentOpts.MiniBatchSize = 64; agentOpts.TargetSmoothFactor = 1e-3; agentOpts.SampleTime = Ts; agentOpts.DiscountFactor = params.DiscountFactor; agentOpts.ActorOptimizerOptions.LearnRate = params.ActorLearnRate; agentOpts.CriticOptimizerOptions.LearnRate = params.CriticLearnRate; agentOpts.ActorOptimizerOptions.GradientThreshold = 1; agentOpts.CriticOptimizerOptions.GradientThreshold = 1; agentOpts.NoiseOptions.StandardDeviation = 0.3; agentOpts.NoiseOptions.StandardDeviationDecayRate = 1e-5; % Create the reinforcement learning agent. You can modify the % localCreateActorAndCritic function to edit the agent model. [actor, critic] = localCreateActorAndCritic(observationInfo, actionInfo); agent = rlDDPGAgent(actor, critic, agentOpts); trainOpts = rlTrainingOptions( ... MaxEpisodes=200, ... MaxStepsPerEpisode=ceil(Tf/Ts), ... ScoreAveragingWindowLength=20, ... Verbose=false, ... Plots="none", ... StopTrainingCriteria="AverageReward", ... StopTrainingValue=800); % Create a data logger for logging data to the monitor object logger = rlDataLogger(monitor); % Run the training result = train(agent, env, trainOpts, Logger=logger); % Export experiment results output.Agent = agent; output.Environment = env; output.TrainingResult = result; output.Parameters = params; end
Run Experiment
When you run the experiment, Experiment Manager executes the training function multiple times. Each trial uses one combination of hyperparameter values. By default, Experiment Manager runs one trial at a time. If you have the Parallel Computing Toolbox ™, you can run multiple trials at the same time or offload your experiment as a batch job in a cluster.
Under Mode, select Sequential, and click Run to run the experiment one trial at a time.
To run multiple trials simultaneously, under Mode, select
Simultaneous, and click Run. This requires a Parallel Computing Toolbox license.To offload the experiment as a batch job under Mode, select
Batch SequentialorBatch Simultaneous, specify your Cluster and Pool Size, and click Run. Note that you will need to configure the cluster with the files necessary for this example. This mode also requires a Parallel Computing Toolbox license.
Note that your cluster needs to be configured with files necessary for this experiment when running in the Batch Sequential or Batch Simultaneous modes. For more information on the Cluster Profile Manager, see Discover Clusters and Use Cluster Profiles (Parallel Computing Toolbox). To configure your cluster:
Open the Cluster Profile Manager and under Properties, click Edit.
Under the
AttachedFilesoption, click Add and specify the filesrlwatertank.slxandloadWaterTankParams.m.Click Done.
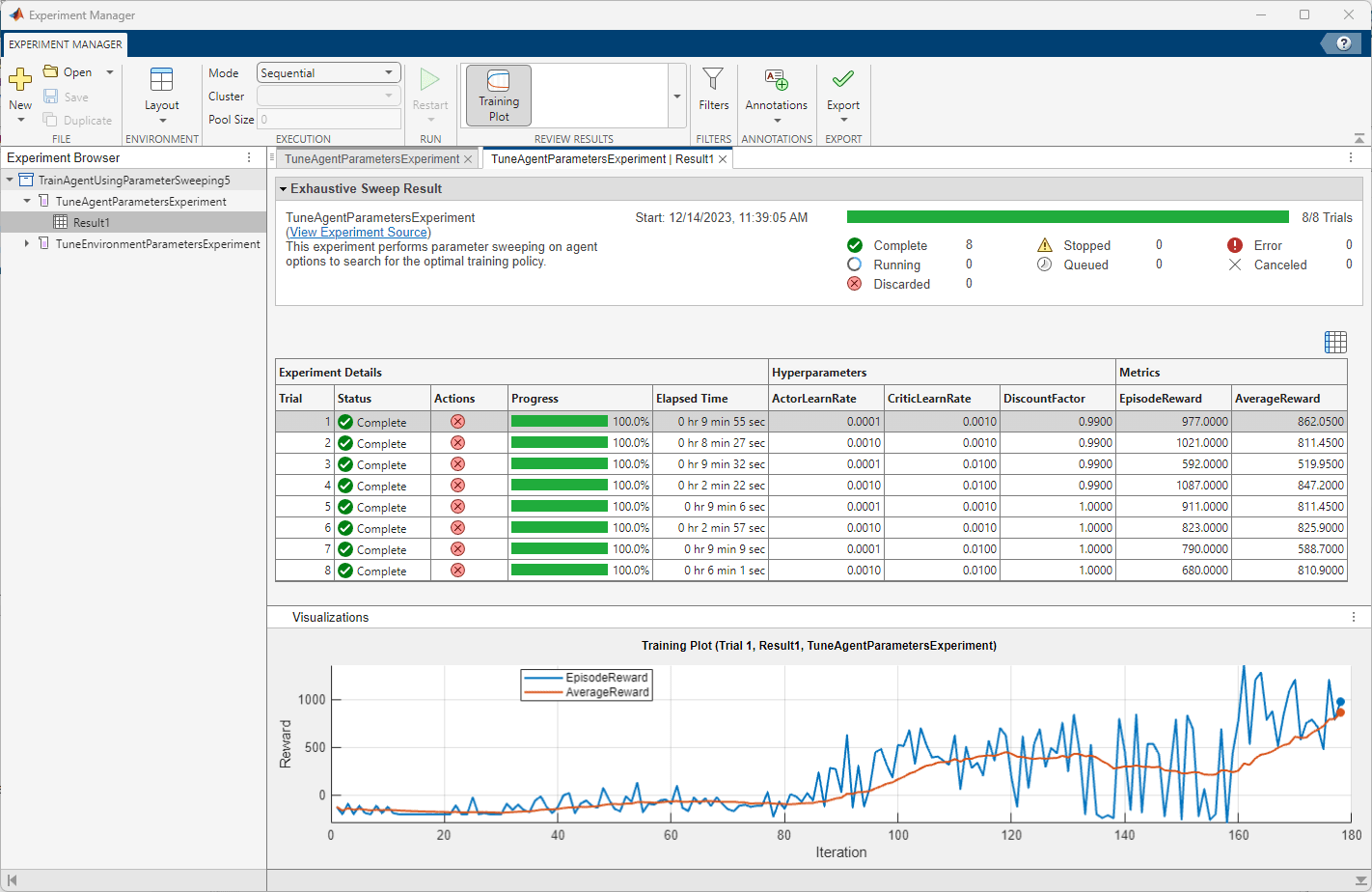
When the experiment is running, select a trial row from the table of results, and under the toolstrip, click Training Plot. This shows the episode and average reward plots for that trial.
After the experiment is finished:
Select the row corresponding to trial 7 which has the average reward
817.5, and under the toolstrip, click Export. This action exports the results of the trial to a base workspace variable.Name the variable
agentParamSweepTrainingOutput.
Tune Environment Parameters Using Parameter Sweeping
In this section you tune the environment's reward function parameters to search for an optimal training policy.

Open Experiment
In the Experiment Browser pane, open TuneEnvironmentParametersExperiment. Verify, as with the agent tuning, that Strategy is set to Exhaustive Sweep. View code for the training function TuneEnvironmentParametersTraining as before.
function output = TuneEnvironmentParametersTraining(params,monitor) % Set the random seed generator rng(0); % Load the Simulink model mdl = "rlwatertank"; load_system(mdl); % Create variables in the base workspace. When running on a parallel worker % this will also create variables in the base workspace of the worker. evalin("base","loadWaterTankParams"); Ts = evalin("base","Ts"); Tf = evalin("base","Tf"); % Create a reinforcement learning environment actionInfo = rlNumericSpec([1 1]); observationInfo = rlNumericSpec([3 1], ... LowerLimit=[-inf -inf 0 ]', ... UpperLimit=[ inf inf inf]'); blk = mdl + "/RL Agent"; env = rlSimulinkEnv(mdl, blk, observationInfo, actionInfo); % Specify a reset function for the environment. You can tune environment % parameters such as reward or initial condition within this function. env.ResetFcn = @(in) localResetFcn(in, params); % Create options for the reinforcement learning agent. You can assign % values from the params struct for sweeping parameters. agentOpts = rlDDPGAgentOptions(); agentOpts.MiniBatchSize = 64; agentOpts.TargetSmoothFactor = 1e-3; agentOpts.SampleTime = Ts; agentOpts.DiscountFactor = 0.99; agentOpts.ActorOptimizerOptions.LearnRate = 1e-3; agentOpts.CriticOptimizerOptions.LearnRate = 1e-3; agentOpts.ActorOptimizerOptions.GradientThreshold = 1; agentOpts.CriticOptimizerOptions.GradientThreshold = 1; agentOpts.NoiseOptions.Variance = 0.3; agentOpts.NoiseOptions.VarianceDecayRate = 1e-5; % Create the reinforcement learning agent. You can modify the % localCreateActorAndCritic function to edit the agent model. [actor, critic] = localCreateActorAndCritic(observationInfo, actionInfo); agent = rlDDPGAgent(actor, critic, agentOpts); trainOpts = rlTrainingOptions( ... MaxEpisodes=200, ... MaxStepsPerEpisode=ceil(Tf/Ts), ... ScoreAveragingWindowLength=20, ... Verbose=false, ... Plots="none", ... StopTrainingCriteria="AverageReward", ... StopTrainingValue=800); % Create a data logger for logging data to the monitor object logger = rlDataLogger(monitor); % Run the training result = train(agent, env, trainOpts, Logger=logger); % Export experiment results output.Agent = agent; output.Environment = env; output.TrainingResult = result; output.Parameters = params; end
Run Experiment
Run the experiment using the same settings you use for agent tuning.
After the experiment is finished:
Select the row corresponding to trial 4, which has the maximum average reward, and export the result to a base workspace variable.
Name the variable as
envParamSweepTrainingOutput.

Evaluate Agent Performance
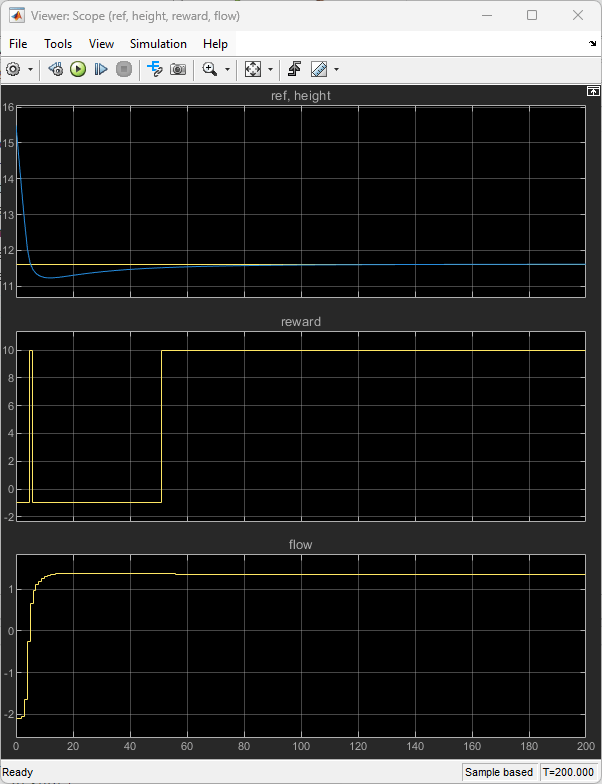
Execute the following code in MATLAB after exporting the agents from the above experiments. This code simulates the agent with the environment and displays the performance in the Scope blocks.
open_system("rlwatertank"); simOpts = rlSimulationOptions(MaxSteps=200); % evaluate the agent exported from % TuneAgentParametersExperiment experience = sim(agentParamSweepTrainingOutput.Agent, ... agentParamSweepTrainingOutput.Environment, ... simOpts); % evaluate the agent exported from % TuneEnvironmentParametersExperiment experience = sim(envParamSweepTrainingOutput.Agent, ... envParamSweepTrainingOutput.Environment, simOpts);
The agent is able to track the desired water level.
Close the project.
close(prj);
See Also
Apps
Functions
Objects
Topics
- Log Training Data to Disk
- Tune Hyperparameters Using Bayesian Optimization
- Tune Hyperparameters Using Reinforcement Learning Designer
- Configure Exploration for Reinforcement Learning Agents
- Train Reinforcement Learning Agents
- Create Custom Simulink Environments
- Deep Deterministic Policy Gradient (DDPG) Agent