データに基づくモデルを使用した故障検出
この例では、データに基づくモデル化の方法をどうやって故障検出に利用するかを示します。
はじめに
マシン運用での異常を早めに検出し分離することは、事故の低減、ダウンタイムの短縮、ひいては運用コストの節約に役立ちます。この方法では、システム運用からのライブ測定値を処理し、新たに発生している障害を示す予期しない動作があればそれにフラグを立てます。
この例では、故障診断の以下の側面について探求します。
残差分析によるシステムの異常な動作の検出
破損したシステムのモデル作成による劣化の検出
オンラインでのモデル パラメーターの適応化を使用したシステムの変化の追跡
システム動作の動的モデルの同定
モデル ベースの検出方法では、対象となるシステムの動的モデルは、まず入出力の測定データを使用して作成されます。優れたモデルは、未来のある特定の対象期間について、システムの応答を正確に予測できます。予測が拙劣である場合、残差が大きくなり、そこに相関が含まれる可能性があります。こうした側面を探求して、失敗がどのように発生するかを探り当てます。
衝撃と振動を受ける構築物について考えます。振動の発生源としては、突風、稼働中のエンジンやタービンとの接触、地盤振動など、システムによってさまざまなタイプの要因が考えられます。衝撃は、システムを十分に刺激するよう加えられる、システムに対する瞬発的衝突テストの結果です。Simulink モデル pdmMechanicalSystem.slx は、こうした構造物の単純な例です。刺激は、周期的な衝突のほか、フィルター処理されたホワイト ノイズでモデル化された地盤振動からも発生します。このシステムの出力は、測定ノイズをもつセンサーによって収集されます。モデルは、健全な状態や破損状態にある構造物に関わる、さまざまなシナリオをシミュレートできます。
sysA = 'pdmMechanicalSystem'; open_system(sysA) % Set the model in the healthy mode of operation set_param([sysA,'/Mechanical System'],'LabelModeActiveChoice','Normal') % Simulate the system and log the response data sim(sysA) ynormal = logsout.getElement('y').Values;
入力信号は測定されていません。記録したのは応答 ynormal のみです。したがって、「ブラインド同定」の手法を使用してシステムの動的モデルを作成します。具体的には、システムの表現として、記録された信号の ARMA モデルを作成します。この方法は、入力信号が (フィルター処理された) ホワイト ノイズであると仮定される場合に有効です。データは周期的衝突の影響下に置かれるため、衝突の発生を開始時点として、その時点ごとにデータをいくつかの部分に分割します。この方法により、各データ セグメントには 1 つの衝突への応答に加えてランダムな刺激が含められます。この状態は時系列モデルを使用して捉えることができ、衝突の影響はそれに見合った初期条件に帰せられます。
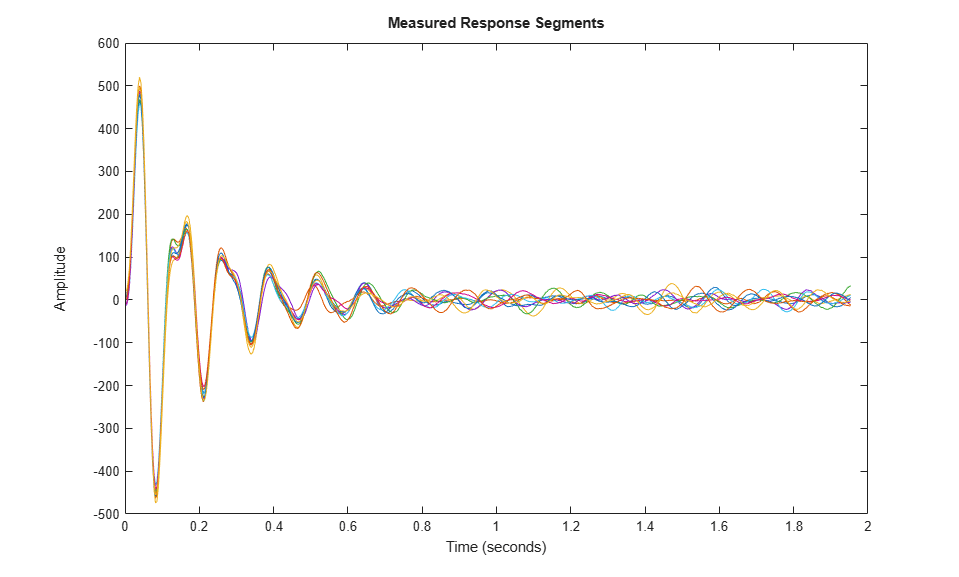
Ts = 1/256; % data sample time nr = 10; % number of bumps in the signal N = 512; % length of data between bumps znormal = cell(nr,1); for ct = 1:nr ysegment = ynormal.Data((ct-1)*N+(1:500)); z = iddata(ysegment,[],Ts); znormal{ct} = z; % each segment has only one bump end plot(znormal{:}) % plot a sampling of the recorded segments title('Measured Response Segments')
データを推定部分と検証部分に分割します。
ze = merge(znormal{1:5});
zv = merge(znormal{6:10});
ssest() コマンドを使用して、7 次時系列モデルを状態空間形式で推定します。モデルの次数は、交差検定 (検証データへの当てはめを確認) と残差分析 (残差が無相関であることを確認) により選択されました。
nx = 7; model = ssest(ze, nx, 'form', 'canonical', 'Ts', Ts); present(model) % view model equations with parameter uncertainty
model =
Discrete-time identified state-space model:
x(t+Ts) = A x(t) + K e(t)
y(t) = C x(t) + e(t)
A =
x1 x2 x3
x1 0 1 0
x2 0 0 1
x3 0 0 0
x4 0 0 0
x5 0 0 0
x6 0 0 0
x7 0.5635 +/- 0.04628 -2.754 +/- 0.2213 5.959 +/- 0.454
x4 x5 x6
x1 0 0 0
x2 0 0 0
x3 1 0 0
x4 0 1 0
x5 0 0 1
x6 0 0 0
x7 -8.33 +/- 0.5195 9.249 +/- 0.3582 -7.948 +/- 0.1443
x7
x1 0
x2 0
x3 0
x4 0
x5 0
x6 1
x7 4.259 +/- 0.02667
C =
x1 x2 x3 x4 x5 x6 x7
y1 1 0 0 0 0 0 0
K =
y1
x1 1.025 +/- 0.01399
x2 1.444 +/- 0.01303
x3 1.907 +/- 0.01266
x4 2.386 +/- 0.0121
x5 2.857 +/- 0.01474
x6 3.26 +/- 0.02242
x7 3.552 +/- 0.03384
Sample time: 0.0039062 seconds
Parameterization:
CANONICAL form with indices: 7.
Disturbance component: estimate
Number of free coefficients: 14
Use "idssdata", "getpvec", "getcov" for parameters and their uncertainties.
Status:
Termination condition: Near (local) minimum, (norm(g) < tol)..
Number of iterations: 7, Number of function evaluations: 15
Estimated using SSEST on time domain data "ze".
Fit to estimation data: [99.07 99.04 99.15 99.05 99.04]% (prediction focus)
FPE: 0.6242, MSE: [0.5971 0.6533 0.599 0.5872 0.6496]
More information in model's "Report" property.
モデルの表示では、パラメーター推定において比較的小さい不確かさが示されます。信頼性は、測定信号の推定スペクトルについて 1-sd (99.73%) の信頼限界を計算することにより確認できます。
h = spectrumplot(model); showConfidence(h, 3)
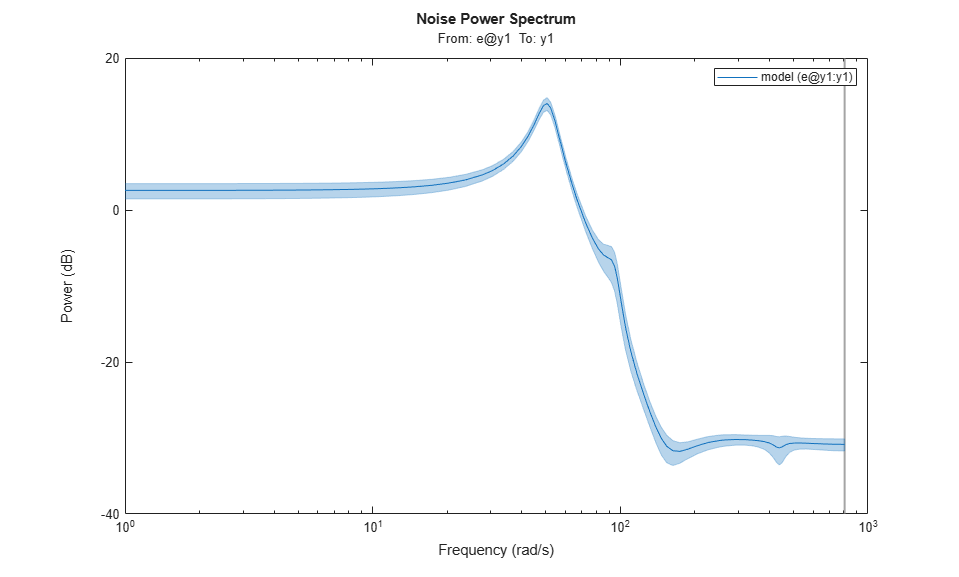
低周波数での応答に約 30% の不確かさがありますが、信頼領域は小さなものとなります。検証の次のステップは、検証データ セット zv での応答をモデルがどの程度うまく予測するのかを確認することです。25 ステップ先の予測期間を使用します。
compare(zv, model, 25) % Validation against one data set
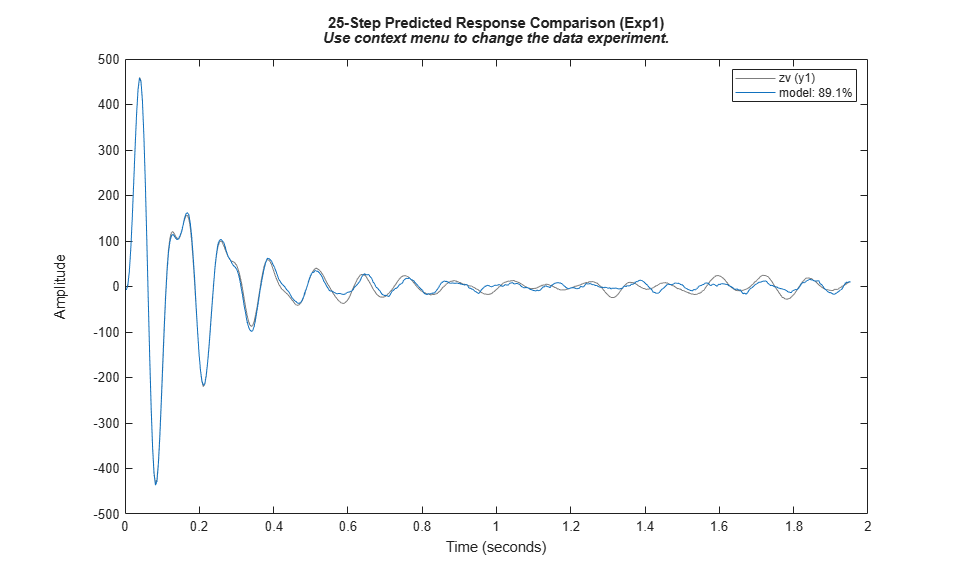
プロットでは、検証データ セットの最初の実験において、25 回のタイム ステップ (= 0.1 秒) 先までの応答をモデルが 85% を超える精度で予測できることが示されています。データ セットでの他の実験への当てはめを確認するには、プロットの軸の右クリックによるコンテキスト メニューを使用します。
モデルの検証の最終ステップは、それによって生成された残差を解析することです。優れたモデルでは、こうした残差はホワイトとなる、つまり非ゼロのラグについて統計的に有意でない相関が示されるはずです。
resid(model, zv)
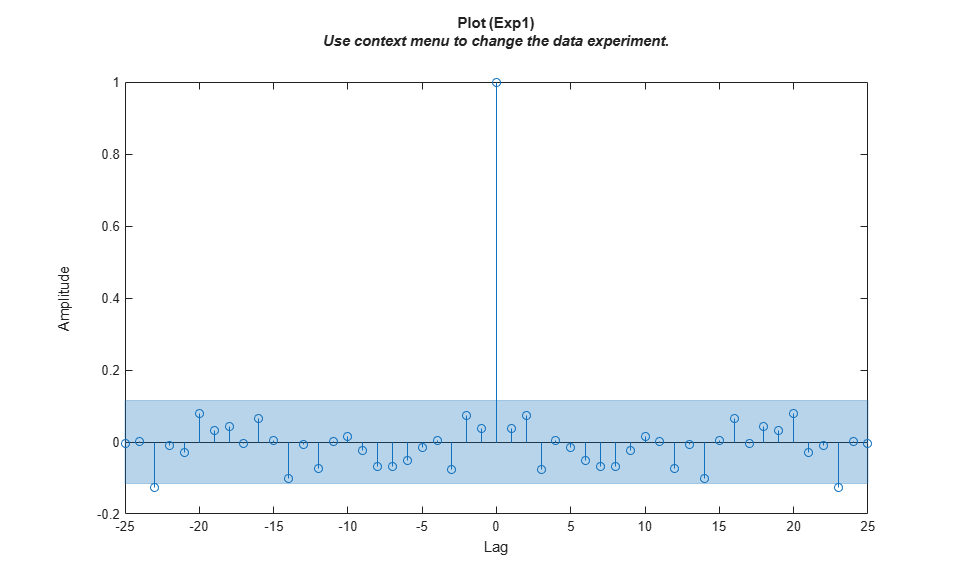
残差は、非ゼロのラグではほとんど無相関です。通常動作のモデルが導出されたので、故障の検出にモデルをどう使用できるかの調査に進みます。
健全な状態のモデルを使用した残差分析による故障検出
故障検出とは、システムを観測する中での好ましくない変化や予期しない変化へのタグ付けです。故障により、システムのダイナミクスに変化が生じます。これは、漸進的な摩損に起因することも、センサーの不具合や部品の破損によって生じる急激な変化に起因することもあります。故障が発生すると、通常の動作状態下で取得したモデルでは、観測される応答を予測できなくなります。このため、測定された応答と予測された応答との差 (残差) が大きくなります。こうした偏差には、通常、残差の二乗和が大きいことや相関が存在することによりフラグが設定されます。
Simulink モデルを、破損したシステムのバリアントに配置してシミュレートします。残差テストに必要なのはホワイト入力であるため (初期状態によってはこれに過渡を伴う場合あり)、単一の衝突を入力として使用します。
set_param([sysA,'/Mechanical System'],'LabelModeActiveChoice','DamagedSystem'); set_param([sysA,'/Pulse'],'Period','5120') % to force only one bump sim(sysA) y = logsout.getElement('y').Values;
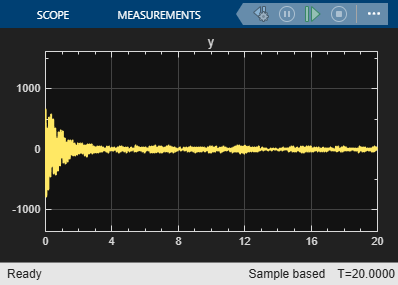
resid(model, y.Data) set_param([sysA,'/Pulse'],'Period','512') % restore original
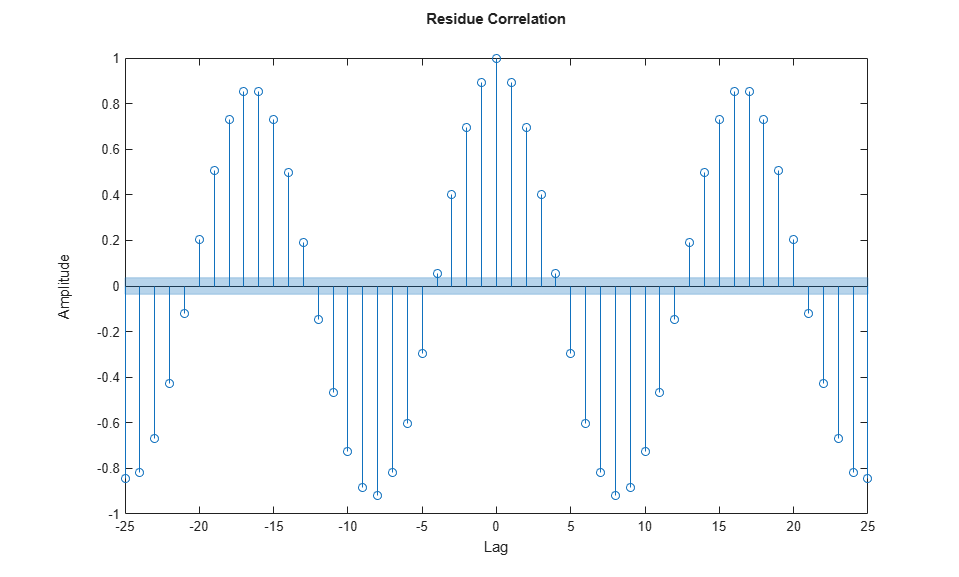
残差は大きくなっており、非ゼロのラグでの相関を示しています。これは、故障の検出の背後にある基本的な考え方です。残差メトリクスを生成し、測定値の新たなセットでどのように変化するかを観測します。ここで使用するのは、1 ステップの予測誤差に基づく単純な残差です。実際には、アプリケーションでのニーズに合わせてカスタマイズされた、より高度な残差が生成されます。
通常状態と劣化状態のモデルを使用した故障検出
故障検出のより詳細な方法は、故障 (破損) 状態のシステムのモデルをも同定することです。これにより、どのモデルがシステムでのライブ測定をよりよく説明するものであるかを解析できます。こうしたアレンジメントは、さまざまなタイプの故障のモデルに一般化でき、そのため、故障の検出だけでなくどの故障であるかの同定 ("分離") にも使用できます。この例では、以下の方法を取ります。
通常の (健全な) 状態で動作しているシステムと、既知の摩損により耐用寿命末期の状態で動作しているシステムでデータを収集します。
各状態での動作を表す動的モデルを同定します。
データ クラスタリング法を使用して、これらの状態に明確な区別を付けます。
故障検出用に、稼働中のマシンからデータを収集し、その動作のモデルを同定します。続いて、観測される動作がどの状態 (通常か破損しているか) によって最もよく説明されるかを予測します。
通常の動作モードでのシステムは既にシミュレートされています。ここでは、"耐用寿命末期" モードのモデル pdmMechanicalSystem をシミュレートします。これは、システムが既に劣化して、動作許容範囲の最終状態にある場合のシナリオです。
set_param([sysA,'/Mechanical System'],'LabelModeActiveChoice','DamagedSystem'); sim(sysA) y = logsout.getElement('y').Values; zfault = cell(nr,1); for ct = 1:nr z = iddata(y.Data((ct-1)*N+(1:500)),[],Ts); zfault{ct} = z; end
ここで、モデルのセットを、各データ セグメントに 1 つずつ作成します。前と同様、7 次の時系列モデルを状態空間形式で作成します。速度の共分散計算をオフにします。
mNormal = cell(nr,1); mFault = cell(nr, 1); nx = order(model); opt = ssestOptions('EstimateCovariance',0); for ct = 1:nr mNormal{ct} = ssest(znormal{ct}, nx, 'form', 'canonical', 'Ts', Ts, opt); mFault{ct} = ssest(zfault{ct}, nx, 'form', 'canonical', 'Ts', Ts, opt); end
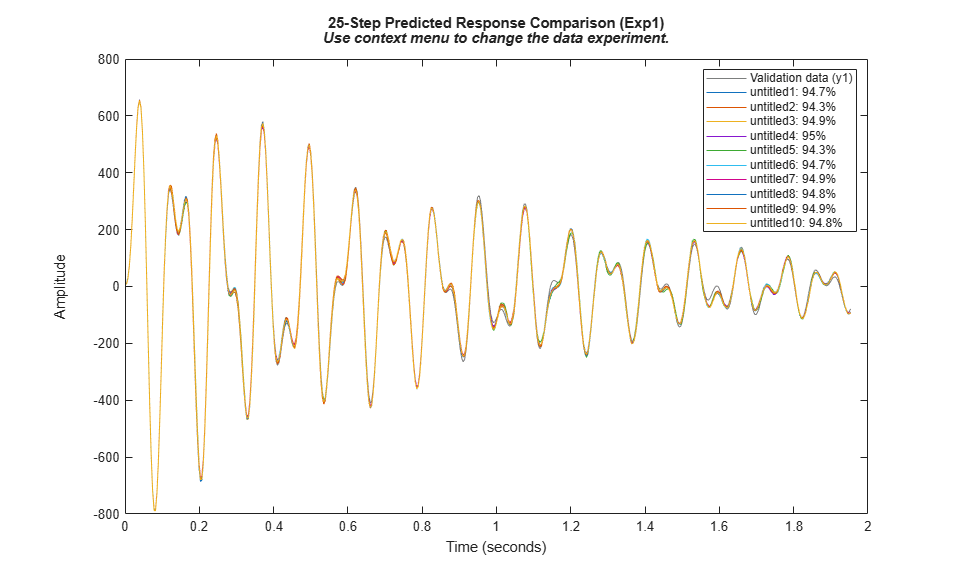
モデル mFault が故障モードでの動作をよく表現していることを確認します。
compare(merge(zfault{:}), mFault{:}, 25)
通常および故障の推定スペクトルを以下にプロットします。
Color1 = 'k'; Color2 = 'r'; ModelSet1 = cat(2,mNormal,repmat({Color1},[nr, 1]))'; ModelSet2 = cat(2,mFault,repmat({Color2},[nr, 1]))'; spectrum(ModelSet1{:},ModelSet2{:}) axis([1 1000 -45 40]) title('Output Spectra (black: normal, red: faulty)')
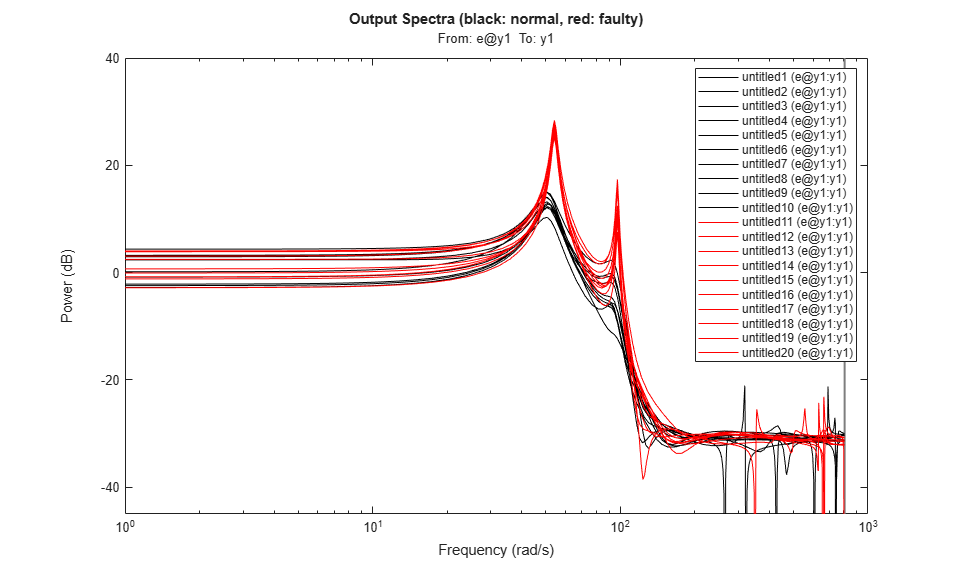
スペクトルのプロットにより、違いが示されます。損傷モードでは主要な共振が増幅されていますが、それ以外のスペクトルはオーバーラップしています。次に、通常の状態と故障状態を量的に区別する手段を作成します。以下のようなデータ クラスタリング法および分類法を使用できます。
Fuzzy C-Means クラスタリング。Fuzzy Logic Toolbox の
fcm()を参照してください。サポート ベクター マシン分類器。Statistics and Machine Learning Toolbox の
fitcsvm ()を参照してください。自己組織化マップ。Deep Learning Toolbox の
selforgmap()を参照してください。
この例では、サポート ベクター マシンの分類手法を使用します。2 つのタイプのモデル (mNormal および mFault) から得た情報のクラスタリングは、極と零点の位置、ピーク共振の位置、パラメーターのリストなど、これらのモデルが提供できる各種情報を基にしている場合があります。ここでは、2 つの共振に対応する極の位置によってモードを分類します。クラスタリングをするため、健全な状態のモデルの極には 'good'、故障状態のモデルの極には 'faulty' でタグを付けます。
ModelTags = cell(nr*2,1); % nr is number of data segments ModelTags(1:nr) = {'good'}; ModelTags(nr+1:end) = {'faulty'}; ParData = zeros(nr*2,4); plist = @(p)[real(p(1)),imag(p(1)),real(p(3)),imag(p(3))]; % poles of dominant resonances for ct = 1:nr ParData(ct,:) = plist(esort(pole(mNormal{ct}))); ParData(nr+ct,:) = plist(esort(pole(mFault{ct}))); end cl = fitcsvm(ParData,ModelTags,'KernelFunction','rbf', ... 'BoxConstraint',Inf,'ClassNames',{'good', 'faulty'}); cl.ConvergenceInfo.Converged
ans = logical 1
cl は SVM 分類器であり、学習データ ParData を good 領域と faulty 領域に分離します。この分類器の predict メソッドを使用することで、nx 行 1 列の入力ベクトルを 2 つの領域のいずれかに割り当てることができます。
これで、パラメーターが健全 (mode = 'Normal') から完全破損 (mode = 'DamagedSystem') まで連続的に変化するシステムからデータ バッチを収集し、予測 (通常か破損しているか) について分類器をテストすることができます。このシナリオをシミュレートするには、モデルを 'DeterioratingSystem' モードにします。
set_param([sysA,'/Mechanical System'],'LabelModeActiveChoice','DeterioratingSystem'); sim(sysA) ytv = logsout.getElement('y').Values; ytv = squeeze(ytv.Data); PredictedMode = cell(nr,1); ssOpt = ssestOptions('SearchMethod','lm'); for ct = 1:nr zSegment = iddata(ytv((ct-1)*512+(1:500)),[],Ts); mSegment = ssest(zSegment, nx, 'form', 'canonical', 'Ts', Ts, ssOpt); PredictedMode(ct) = predict(cl, plist(esort(pole(mSegment)))); end I = strcmp(PredictedMode,'good'); Tags = ones(nr,1); Tags(~I) = -1; t = (0:5120)'*Ts; % simulation time Time = t(1:512:end-1); plot(Time(I),Tags(I),'g*',Time(~I),Tags(~I),'r*','MarkerSize',12) grid on axis([0 20 -2 2]) title('Green: Normal, Red: Faulty state') xlabel('Data evaluation time') ylabel('Prediction')
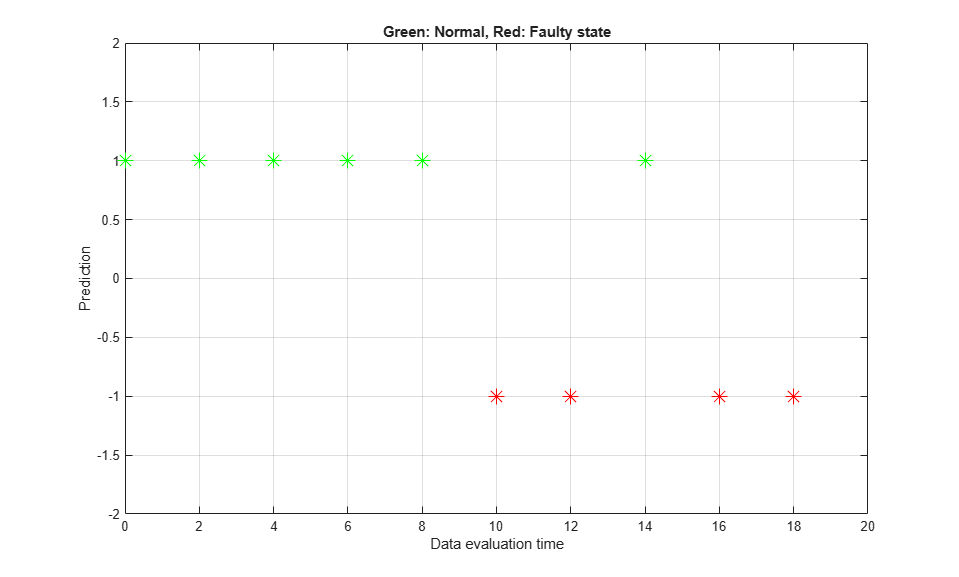
プロットでは、中間点あたりまで動作は正常であり、その後故障状態となると分類器によって予測されていることが示されています。
オンラインでのモデル パラメーターの適応化による故障検出
上記の解析では、システム動作中のさまざまな時点で収集したデータのバッチを使用しました。システムの健全性をモニターするための、より便利なことの多い代替方法は、その動作の適応モデルを作成することです。新しい測定値が継続的に処理され、モデルのパラメーターを再帰的に更新するために使用されます。摩損や故障の影響は、モデルのパラメーター値の変化によって示されます。
摩損のシナリオについて再考します。システムが古くなるにつれ、"ガタガタ" が大きくなります。これは、いくつかの共振モードの励起と、システムのピーク応答の立ち上がりが現れたものです。このシナリオはモデル pdmDeterioratingSystemEstimation で説明されており、このモデルは、オフライン同定用に追加された瞬発的衝突が存在しないこと以外、pdmMechanicalSystem の "DeterioratingSystem" モードと同じです。システムの応答は、ARMA モデル構造のパラメーターを推定するよう設定された "Recursive Polynomial Model Estimator" ブロックに渡されます。実際のシステムは健全な状態で始まり、200 秒の時間範囲の間に耐用寿命の末期状態まで劣化します。
initial_model = translatecov(@(x)idpoly(x),model);
sysB = 'pdmDeterioratingSystemEstimation';
open_system(sysB);
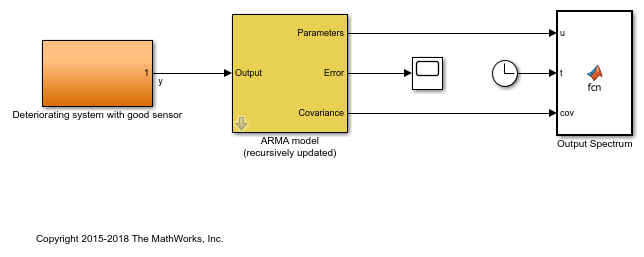
"ARMA model" ブロックは、前節で多項式 (ARMA) 形式への変換後に導出された正常動作の推定モデルから得たパラメーターと共分散データを使用して初期化されています。パラメーターの共分散データも変換されるよう、関数 translatecov() が使用されます。ブロックでは、"忘却係数" アルゴリズムが使用されます。この忘却係数は、パラメーターを各サンプリング瞬時に更新するため、1 よりわずかに小さく設定されています。忘却係数での選択は、システムの更新速度に影響します。値が小さいと、更新による分散が大きくなります。一方、値が大きいと、推定器が急速な変化に適応しにくくなります。
モデル パラメーターによる推定は、出力スペクトルとその 3-sd 信頼領域を更新するために使用されます。対象周波数でスペクトルの信頼領域が健全なシステムの信頼領域とオーバーラップしない場合、システムは明らかに変化しています。故障検出のしきい値は、特定の周波数で許容される最大ゲインをマークするプロットで、黒の線を使用して示されています。システムでの変化が蓄積されるにつれ、スペクトルはこの線を超えてドリフトします。これは、故障の視覚インジケーターとして役立ち、実際のシステムで修理を要請するために使用できます。
シミュレーションを実行し、スペクトルのプロットが更新されていくのを観察します。
sim(sysB)
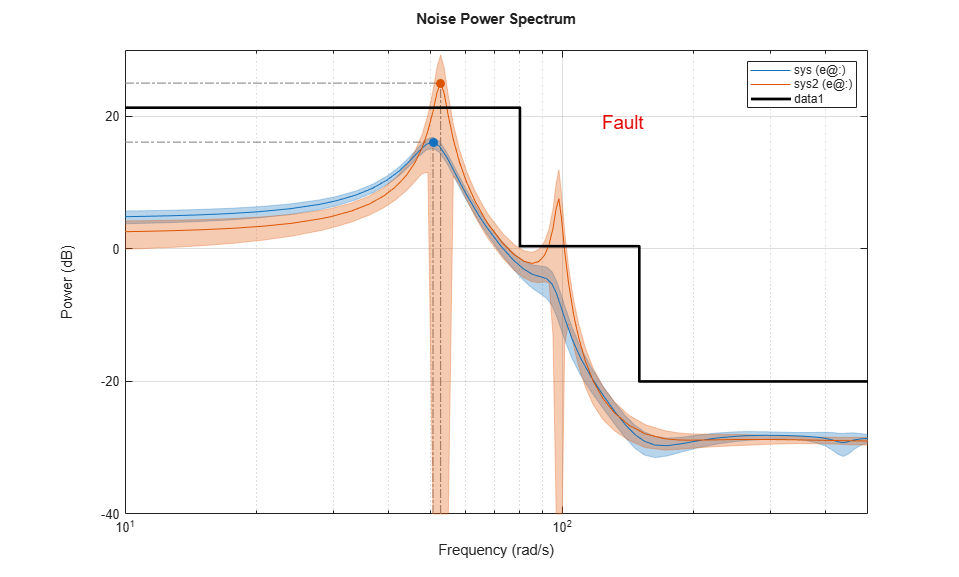
モデル パラメーターの実行中の推定はシステムの極の位置の計算にも使用され、その後、システムの状態が "正常" か "故障" かを予測するため SVM 分類器に入力されます。この判定はプロットにも表示されます。正規化された予測のスコアが 0.3 より小さい場合、判定は仮のもの (識別の境界に近い) とみなされます。スペクトルの実行中の推定と分類器による予測がどのように計算されるかの詳細については、スクリプト pdmARMASpectrumPlot.m を参照してください。
適応推定およびプロット手順は、関数 recursiveARMA() を使用して Simulink の外で実装することが可能です。"Recursive Polynomial Model Estimator" ブロックと関数 recursiveARMA() のどちらも、展開を目的としたコード生成をサポートしています。
分類スキームは、既知の故障モードがいくつかある場合へと一般化できます。これについては、各モードが特定タイプの故障を参照する、複数グループの分類器が必要になります。こうした側面については、この例では扱っていません。
まとめ
この例では、システム同定スキームをデータ クラスタリング法および分類法と組み合わせて故障の検出と分離に役立てる方法を説明しました。逐次的バッチ解析とオンラインでの適応スキームの両方について説明しました。測定された出力信号の ARMA 構造のモデルが同定されました。同様の方法は、入力信号と出力信号の両方にアクセスでき、状態空間モデルや Box-Jenkins 多項式モデルのような他のタイプのモデル構造の使用を考えている状況で採用できます。
この例でわかったことは、次のとおりです。
通常動作のモデルに基づいた残差における相関は、故障の開始を示す可能性があります。
漸進的に悪化している故障は、システムの動作に継続的に適応するモデルを採用することにより検出できます。モデルの特性 (出力スペクトルでの境界など) について事前設定されたしきい値は、故障の発現と進行を可視化するために役立ちます。
故障の発生源を分離する必要がある場合、実行可能な方法は、関連する故障モードに応じた別々のモデルを前もって作成しておくことです。これにより、分類法を使用して、システムの予測された状態をこれらのモードのいずれかに割り当てられるようになります。