このページの内容は最新ではありません。最新版の英語を参照するには、ここをクリックします。
uniquetol
許容誤差内の一意の値
構文
説明
C = uniquetol(A,tol,occurrence)occurrence が 'highest' である場合、複数の値が互いに許容誤差内にあると、最大値が一意であるとして選択されることを指定します。occurrence の既定値は 'lowest' であり、最小値を一意であるとして選択します。
[___] = uniquetol(___, は、前述の構文にある任意の入力引数または出力引数を組み合わせて、1 つ以上の名前と値のペアの引数で指定される追加のオプションを使用します。たとえば、Name,Value)uniquetol(A,'ByRows',true) は A 内で一意の行を判別します。
例
ベクトル x を作成します。x の変換と復元を実行して、2 番目のベクトル y を取得します。この変換により y で丸め誤差が生じます。
x = (1:6)'*pi; y = 10.^log10(x);
この誤差を求め、x と y が同一でないことを検証します。
x-y
ans = 6×1
10-14 ×
0.0444
0
0
0
0
-0.3553
unique を使用して、連結ベクトル [x;y] 内の一意の要素を検出します。関数 unique は厳密な比較を実行し、x の一部の値が y の値と厳密には等しくないと判定します。これらは、x-y の差が非ゼロである、同じ要素です。したがって、c には重複しているように "見える" 値が含まれています。
c = unique([x;y])
c = 8×1
3.1416
3.1416
6.2832
9.4248
12.5664
15.7080
18.8496
18.8496
uniquetol を使用して、わずかな誤差が許容される比較を実行します。uniquetol は許容誤差内にある要素を等価として扱います。
C = uniquetol([x;y])
C = 6×1
3.1416
6.2832
9.4248
12.5664
15.7080
18.8496
既定では、uniquetol は許容誤差内にある一意の "要素" を検出しますが、行列で許容誤差内にある "行" を検出することもできます。
数値行列 A を作成します。A の変換と復元を実行して、2 番目の行列 B を取得します。この変換により B に丸め誤差が生じます。
A = [0.05 0.11 0.18; 0.18 0.21 0.29; 0.34 0.36 0.41; 0.46 0.52 0.76]; B = log10(10.^A);
unique を使用して、A および B 内で一意の行を検出します。関数 unique は厳密な比較を実行し、行の相違がたとえごくわずかであっても、連結行列 [A;B] 内のすべての行が一意であると判定します。
unique([A;B],'rows')ans = 8×3
0.0500 0.1100 0.1800
0.0500 0.1100 0.1800
0.1800 0.2100 0.2900
0.1800 0.2100 0.2900
0.3400 0.3600 0.4100
0.3400 0.3600 0.4100
0.4600 0.5200 0.7600
0.4600 0.5200 0.7600
uniquetol を使用して一意の行を検出します。uniquetol は、許容誤差内にある行を等価として扱います。
uniquetol([A;B],'ByRows',true)ans = 4×3
0.0500 0.1100 0.1800
0.1800 0.2100 0.2900
0.3400 0.3600 0.4100
0.4600 0.5200 0.7600
ベクトル x を作成します。x の変換と復元を実行して、2 番目のベクトル y を取得します。この変換により、y の一部の要素に丸め誤差が生じます。
x = (1:5)'*pi; y = 10.^log10(x);
x と y を単一のベクトル A に組み合わせます。uniquetol を使用して A を再作成します。その際、許容誤差内にある値を等価として扱います。
A = [x;y]
A = 10×1
3.1416
6.2832
9.4248
12.5664
15.7080
3.1416
6.2832
9.4248
12.5664
15.7080
[C,IA,IC] = uniquetol(A); newA = C(IC)
newA = 10×1
3.1416
6.2832
9.4248
12.5664
15.7080
3.1416
6.2832
9.4248
12.5664
15.7080
この後のコードでは、newA と == を同時に使用したり、完全な等価性を評価する isequal や unique などの関数を使用したりできます。
D1 = unique(A)
D1 = 6×1
3.1416
3.1416
6.2832
9.4248
12.5664
15.7080
D2 = unique(newA)
D2 = 5×1
3.1416
6.2832
9.4248
12.5664
15.7080
occurrence オプションを使用して、uniquetol がどの要素を一意であるとして選択するか制御します。
ベクトルを作成し、どの要素が 1e-1 の許容誤差内で一意であるか検索します。
a = [1 1.1 1.11 1.12 1.13 2]; c = uniquetol(a,1e-1)
c = 1×2
1 2
A にある最初の 5 つの要素はすべて 1e-1 の許容誤差に関して類似した値であるため、その中の最小値のみが一意であるとして選択されます。これは uniquetol が a にある最小値から開始して、ベクトルの最後にある 2 に到達するまで、許容誤差の範囲外となる要素を新たに検出しないためです。
'highest' オプションを使用して、uniquetol が a にある最大値から開始するように指定します。すると、uniquetol が最大値から小さい方へ動作するため、1.13 要素が一意であるとして選択されます。
d = uniquetol(a,1e-1,'highest')d = 1×2
1.1300 2.0000
2 次元サンプル点の点群を作成し、点 を中心とする半径 0.5 の円内に制限します。
x = rand(10000,2); insideCircle = sqrt((x(:,1)-.5).^2+(x(:,2)-.5).^2)<0.5; y = x(insideCircle,:);
元のデータセットの各点が、特定の点の許容誤差内になるよう、点の数を絞り込みます。
tol = 0.05;
C = uniquetol(y,tol,'ByRows',true);絞り込んだ後の点を、元のデータ セットの上に赤でプロットします。赤い点はすべて元のデータ セットのメンバーです。すべての赤い点の間には少なくとも tol の距離があります。
plot(y(:,1),y(:,2),'.') hold on axis equal plot(C(:,1), C(:,2), '.r', 'MarkerSize', 10)

乱数のベクトルを作成し、許容誤差を使用して一意の要素を判定します。OutputAllIndices を true に指定して、一意の値の許容誤差内にある要素のインデックスをすべて返します。
A = rand(100,1);
[C,IA] = uniquetol(A,1e-2,'OutputAllIndices',true);値 C(2) の許容誤差内にある要素の平均値を求めます。
C(2)
ans = 0.0318
allA = A(IA{2})allA = 3×1
0.0357
0.0318
0.0344
aveA = mean(allA)
aveA = 0.0340
既定の設定では、uniquetol は abs(u-v) <= tol*DS の形式の許容誤差テストを使用します。ここで、DS は入力データの大きさに基づいて自動的に "スケーリング" を行います。DS に異なる値を指定して、DataScale オプションと共に使用できます。ただし、(DS がスカラーである場合の) 絶対許容誤差は、入力データの大きさに基づいてスケーリングされません。
まず、距離が eps だけ離れている 2 つの小さい値を比較します。tol と DS を指定して、abs(u-v) <= 10^-6 という許容誤差内の式を作成します。
x = 0.1;
uniquetol([x, exp(log(x))], 10^-6, 'DataScale', 1)ans = 0.1000
次に、値を大きくします。exp(log(x)) の計算の丸め誤差は値の大きさ、つまり eps(x) に比例します。2 つの大きい値間の距離が eps であっても、eps(x) はこれを大きく上回る値になります。したがって、10^-6 は許容誤差として適切でなくなります。
x = 10^10;
uniquetol([x, exp(log(x))], 10^-6, 'DataScale', 1)ans = 1×2
1010 ×
1.0000 1.0000
この問題を修正するには、DS の既定値 (スケーリングされる) を使用します。
format long
Y = [0.1 10^10];
uniquetol([Y, exp(log(Y))])ans = 1×2
1010 ×
0.000000000010000 1.000000000000000
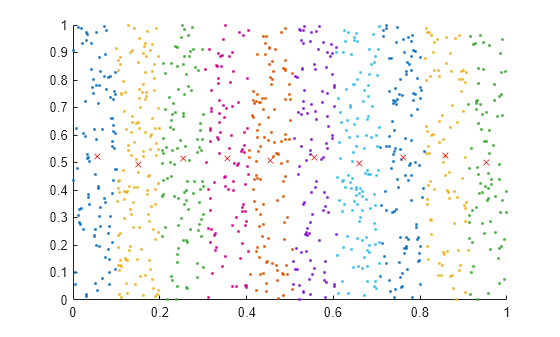
2 次元の乱数点のセットを作成します。次に uniquetol を使用して、これらの点を類似した (許容誤差内の) x 座標をもつ縦の複数の帯域にグループ化します。uniquetol には次のオプションを指定します。
点の座標は
Aの行に含まれるため、ByRowsをtrueに指定します。OutputAllIndicesをtrueに指定して、互いに許容誤差内にある x 座標をもつすべての点のインデックスを返すようにします。x座標に絶対許容誤差を使用して、y座標は無視するために、DataScaleは[1 Inf]に指定します。
A = rand(1000,2); DS = [1 Inf]; [C,IA] = uniquetol(A, 0.1, 'ByRows', true, ... 'OutputAllIndices', true, 'DataScale', DS);
各帯域の点と平均値をプロットします。
hold on for k = 1:length(IA) plot(A(IA{k},1), A(IA{k},2), '.') meanAi = mean(A(IA{k},:)); plot(meanAi(1), meanAi(2), 'xr') end
入力引数
名前と値の引数
出力引数
アルゴリズム
uniquetol は入力を辞書順に並べ替えたうえで、最も低い値または最も高い値から開始して許容誤差内にある一意な値を検出します。そのため、入力の並べ替え順序を変更すると、出力が変化する可能性があります。たとえば、uniquetol(-A) で返される結果が -uniquetol(A) の結果とは異なる場合があります。
"C 内には互いに許容誤差内にある要素が 2 つあってはならない" という条件を満たす有効な出力 C が複数存在する場合もあります。関数 uniquetol は、occurrence の値が 'highest' または 'lowest' であるか、および PreserveRange オプションが指定されているかに応じて、複数の有効な出力を返すことができます。