textscan
テキスト ファイルまたは文字列から書式付きデータを読み取る
構文
説明
C = textscan(fileID,formatSpec)C に読み取ります。テキスト ファイルはファイル識別子 fileID で示されます。fopen を使用すると、このファイルを開いて fileID 値を取得できます。ファイルから読み取った後、fclose(fileID) を呼び出してファイルを閉じます。
textscan は、ファイル内のデータを formatSpec の変換指定子に一致させようとします。関数 textscan はファイル全体に formatSpec を再適用して、formatSpec がデータと一致しない箇所で停止します。
C = textscan(fileID,formatSpec,N)formatSpec を N 回使用して、ファイル データを読み取ります。ここで N は正の整数です。N 回反復した後でファイルから追加のデータを読み取るには、元の fileID を使用して textscan を再度呼び出します。同じファイル識別子 (fileID) で関数 textscan を呼び出してファイルのテキスト スキャンを再開すると、textscan は、最後の読み取りを終了したポイントから自動的に読み取りを再開します。
C = textscan(chr,formatSpec)chr のテキストを cell 配列 C に読み取ります。文字ベクトルからテキストを読み取る際、textscan を繰り返し呼び出すと、そのたびに先頭からスキャンが再開されます。前回の位置からスキャンを再開するには、position 出力を要求します。
textscan は、文字ベクトル chr のデータを formatSpec で指定された形式に一致させようとします。
C = textscan(chr,formatSpec,N)formatSpec を N 回使用します。N は正の整数です。
C = textscan(___,Name,Value)Name,Value のペアの引数を使用して、オプションを指定します。
例
浮動小数点数を含む文字ベクトルを読み取ります。
chr = '0.41 8.24 3.57 6.24 9.27'; C = textscan(chr,'%f');
formatSpec の指定子 '%f' は、textscan に chr 内の各フィールドを倍精度浮動小数点と一致させるように指示します。
cell 配列 C の内容を表示します。
celldisp(C)
C{1} =
0.4100
8.2400
3.5700
6.2400
9.2700
同じ文字ベクトルを読み取り、各値を小数点以下 1 に切り捨てます。
C = textscan(chr,'%3.1f %*1d');指定子 %3.1f は、フィールド幅が 3 桁で精度が 1 であることを示します。関数 textscan は、小数点および小数点以下 1 桁を含む合計 3 桁を読み取ります。指定子 %*1d は、textscan に残りの桁をスキップするように指示します。
cell 配列 C の内容を表示します。
celldisp(C)
C{1} =
0.4000
8.2000
3.5000
6.2000
9.2000
一連の 16 進数を表す文字ベクトルを読み取ります。16 進数を表すテキストは、0 ~ 9 の数字、a ~ f または A-F の文字と、オプションで接頭辞 0x または 0X を含みます。
hexnums 内のフィールドを 16 進数に一致させるには、'%x' 指定子を使用します。関数 textscan は、フィールドを符号なしの 64 ビット整数に変換します。
hexnums = '0xFF 0x100 0x3C5E A F 10'; C = textscan(hexnums,'%x')
C = 1×1 cell array
{6×1 uint64}
C の内容を行ベクトルとして表示します。
transpose(C{:})ans = 1×6 uint64 row vector
255 256 15454 10 15 16
フィールドは、符号付き、または符号なしの 8 ビット、16 ビット、32 ビット、または 64 ビット整数に変換できます。hexnums 内のフィールドを符号付きの 32 ビット整数に変換するには、'%xs32' 指定子を使用します。
C = textscan(hexnums,'%xs32');
transpose(C{:})ans = 1×6 int32 row vector
255 256 15454 10 15 16
入力を解釈するフィールド幅を指定することもできます。その場合、接頭辞はそのフィールド幅までカウントされます。たとえば、%3x のように、フィールド幅を 3 に設定した場合、textscan はテキスト '0xAF 100' を '0xA'、'F'、'100' の 3 つのテキストに分割します。3 つのテキストは、異なる 16 進数として扱われます。
C = textscan('0xAF 100','%3x'); transpose(C{:})
ans = 1×3 uint64 row vector
10 15 256
一連の 2 進数を表す文字ベクトルを読み取ります。2 進数を表すテキストには、0 と 1 の数字と、オプションで接頭辞 0b または 0B が含まれます。
binnums 内のフィールドを 2 進数に一致させるには、'%b' 指定子を使用します。関数 textscan は、フィールドを符号なしの 64 ビット整数に変換します。
binnums = '0b101010 0b11 0b100 1001 10'; C = textscan(binnums,'%b')
C = 1×1 cell array
{5×1 uint64}
C の内容を行ベクトルとして表示します。
transpose(C{:})ans = 1×5 uint64 row vector
42 3 4 9 2
フィールドは、符号付き、または符号なしの 8 ビット、16 ビット、32 ビット、または 64 ビット整数に変換できます。binnums 内のフィールドを符号付きの 32 ビット整数に変換するには、'%bs32' 指定子を使用します。
C = textscan(binnums,'%bs32');
transpose(C{:})ans = 1×5 int32 row vector
42 3 4 9 2
入力を解釈するフィールド幅を指定することもできます。その場合、接頭辞はそのフィールド幅までカウントされます。たとえば、%3b のように、フィールド幅を 3 に設定した場合、textscan はテキスト '0b1010 100' を '0b1'、'010'、'100' の 3 つのテキストに分割します。3 つのテキストは、異なる 2 進数として扱われます。
C = textscan('0b1010 100','%3b'); transpose(C{:})
ans = 1×3 uint64 row vector
1 2 4
データ ファイルを読み込み、適切な型をもつ各列を読み取ります。
scan1.dat ファイルをテキスト エディターに読み込み、その内容をプレビューします。スクリーン ショットを以下に示します。
filename = 'scan1.dat';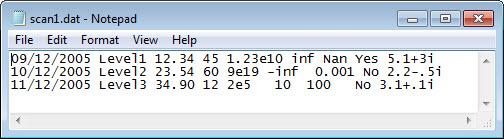
ファイルを開き、各列を適切な変換指定子で読み取ります。textscan は 1-by-9 の cell 配列 C を返します。
fileID = fopen(filename); C = textscan(fileID,'%s %s %f32 %d8 %u %f %f %s %f'); fclose(fileID); whos C
Name Size Bytes Class Attributes C 1x9 2249 cell
C 内の各セルの MATLAB® データ型を表示します。
C
C=1×9 cell array
{3×1 cell} {3×1 cell} {3×1 single} {3×1 int8} {3×1 uint32} {3×1 double} {3×1 double} {3×1 cell} {3×1 double}
個々のエントリを調べます。C{1} と C{2} は cell 配列です。C{5} はデータ型 uint32 であるため、C{5} のはじめの 2 要素は、32 ビット符号なし整数の最大値または intmax('uint32') です。
celldisp(C)
C{1}{1} =
09/12/2005
C{1}{2} =
10/12/2005
C{1}{3} =
11/12/2005
C{2}{1} =
Level1
C{2}{2} =
Level2
C{2}{3} =
Level3
C{3} =
12.3400
23.5400
34.9000
C{4} =
45
60
12
C{5} =
4294967295
4294967295
200000
C{6} =
Inf
-Inf
10
C{7} =
NaN
0.0010
100.0000
C{8}{1} =
Yes
C{8}{2} =
No
C{8}{3} =
No
C{9} =
5.1000 + 3.0000i
2.2000 - 0.5000i
3.1000 + 0.1000i
前の例のデータの 2 列目にある各フィールドからリテラル テキスト 'Level' を削除します。ファイルのプレビューを以下に示します。
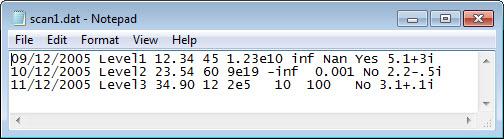
ファイルを開き、formatSpec 入力内のリテラル テキストを一致させます。
filename = 'scan1.dat'; fileID = fopen(filename); C = textscan(fileID,'%s Level%d %f32 %d8 %u %f %f %s %f'); fclose(fileID); C{2}
ans = 3×1 int32 column vector
1
2
3
C 内の 2 番目のセルの MATLAB® データ型を表示します。1-by-9 の cell 配列 C の 2 番目のセルは、データ型が int32 になっています。
disp( class(C{2}) )int32
前の例のファイル内にある最初の列を cell 配列に読み取り、残りの部分をスキップします。
filename = 'scan1.dat'; fileID = fopen(filename); dates = textscan(fileID,'%s %*[^\n]'); fclose(fileID); dates{1}
ans = 3×1 cell
{'09/12/2005'}
{'10/12/2005'}
{'11/12/2005'}
textscan は cell 配列の日付を返します。
data.csv ファイルをテキスト エディターに読み込み、その内容をプレビューします。スクリーン ショットを以下に示します。このファイルにはコンマ区切りのデータが含まれており、空の値も含まれています。
![]()
ファイルを読み取り、空のセルを -Inf に変換します。
filename = 'data.csv'; fileID = fopen(filename); C = textscan(fileID,'%f %f %f %f %u8 %f',... 'Delimiter',',','EmptyValue',-Inf); fclose(fileID); column4 = C{4}, column5 = C{5}
column4 = 2×1
4
-Inf
column5 = 2×1 uint8 column vector
0
11
textscan は 1-by-6 の cell 配列 C を返します。関数 textscan は、C{4} の空の値を -Inf に変換します。ここで C{4} は浮動小数点形式に関連付けられています。MATLAB® は符号なし整数 -Inf を 0 と表示するため、textscan は C{5} 内の空の値を -Inf ではなく 0 に変換します。
data2.csv ファイルをテキスト エディターに読み込み、その内容をプレビューします。スクリーン ショットを以下に示します。このファイルにはコメントとして解釈できるデータがあり、'NA' や 'na' など、空のフィールドを示す可能性がある他のエントリがあります。
filename = 'data2.csv';![]()
textscan がコメントまたは空の値として扱う入力を指定し、データをスキャンして C に読み込みます。
fileID = fopen(filename); C = textscan(fileID,'%s %n %n %n %n','Delimiter',',',... 'TreatAsEmpty',{'NA','na'},'CommentStyle','//'); fclose(fileID);
出力を表示します。
celldisp(C)
C{1}{1} =
abc
C{1}{2} =
def
C{2} =
2
NaN
C{3} =
NaN
5
C{4} =
3
6
C{5} =
4
7
data3.csv ファイルをテキスト エディターに読み込み、その内容をプレビューします。スクリーン ショットを以下に示します。このファイルには区切り記号の繰り返しが含まれています。
filename = 'data3.csv';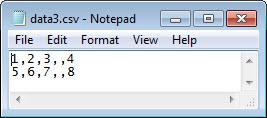
連続するコンマを 1 つの区切り記号として扱うには、MultipleDelimsAsOne パラメーターを使用して値を 1 (true) に設定します。
fileID = fopen(filename); C = textscan(fileID,'%f %f %f %f','Delimiter',',',... 'MultipleDelimsAsOne',1); fclose(fileID); celldisp(C)
C{1} =
1
5
C{2} =
2
6
C{3} =
3
7
C{4} =
4
8
この例のデータ ファイル grades.txt を読み込み、その内容をテキスト エディターでプレビューします。スクリーン ショットを以下に示します。このファイルには区切り記号の繰り返しが含まれています。
filename = 'grades.txt';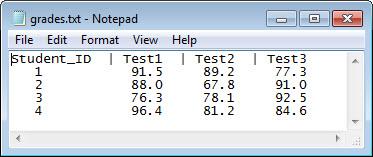
形式 '%s' を使用した列ヘッダーを 4 回読み取ります。
fileID = fopen(filename); formatSpec = '%s'; N = 4; C_text = textscan(fileID,formatSpec,N,'Delimiter','|');
ファイルから数値データを読み取ります。
C_data0 = textscan(fileID,'%d %f %f %f')C_data0=1×4 cell array
{4×1 int32} {4×1 double} {4×1 double} {4×1 double}
CollectOutput の既定値は 0 (false) であるため、textscan は数値データの各列を別々の配列に返します。
ファイルの位置指定子をファイルの先頭に設定します。
frewind(fileID);
同じクラスの連続する列が 1 つの配列に収集されるように、ファイルを再度読み取って CollectOutput を 1 (true) に設定します。関数 repmat を使用して、%f 変換指定子を 3 回繰り返すように指定できます。この方法は、形式を何度も繰り返す場合に便利です。
C_text = textscan(fileID,'%s',N,'Delimiter','|'); C_data1 = textscan(fileID,['%d',repmat('%f',[1,3])],'CollectOutput',1)
C_data1=1×2 cell array
{4×1 int32} {4×3 double}
テスト スコア (すべて double) が、単一の 4 行 3 列の配列に集められます。
ファイルを閉じます。
fclose(fileID);
テキスト ファイルからデータの最初の列と最後の列を読み取ります。テキストの列 1 つと整数データの列 1 つをスキップします。
names.txt ファイルをテキスト エディターに読み込み、その内容をプレビューします。スクリーン ショットを以下に示します。このファイルには引用符付きテキストの列が 2 つあり、その後に整数の列が 1 つ、最後に浮動小数点数の列が 1 つ続きます。
filename = 'names.txt';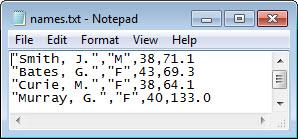
ファイルからデータの最初の列と最後の列を読み取ります。変換指定子 %q を使用して、二重引用符 (") で囲まれたテキストを読み取ります。%*q は引用符で囲まれたテキストをスキップし、%*d は整数フィールドをスキップし、%f は浮動小数点数を読み取ります。'Delimiter' の名前と値のペア引数を使用して、コンマ区切り記号を指定します。
fileID = fopen(filename,'r'); C = textscan(fileID,'%q %*q %*d %f','Delimiter',','); fclose(fileID);
出力を表示します。textscan は cell 配列 C を返しますが、そこで、テキストを囲む二重引用符は削除されます。
celldisp(C)
C{1}{1} =
Smith, J.
C{1}{2} =
Bates, G.
C{1}{3} =
Curie, M.
C{1}{4} =
Murray, G.
C{1}{5} =
Brown, K.
C{2} =
71.1000
69.3000
64.1000
133.0000
64.9000
german_dates.txt ファイルをテキスト エディターに読み込み、その内容をプレビューします。スクリーン ショットを以下に示します。値の最初の列にはドイツ語の日付が含まれ、2 番目と 3 番目の列は数値となっています。
filename = 'german_dates.txt';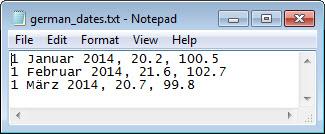
ファイルを開きます。ファイルに関連する文字エンコード スキームを、fopen の最後の入力に指定します。
fileID = fopen(filename,'r','n','ISO-8859-15');
ファイルを読み取ります。%{dd % MMMM yyyy}D 指定子を使用して、ファイルの日付形式を指定します。名前と値のペア引数 DateLocale を使用して、日付のロケールを指定します。
C = textscan(fileID,'%{dd MMMM yyyy}D %f %f',... 'DateLocale','de_DE','Delimiter',','); fclose(fileID);
C の最初のセルの内容を表示します。システムのロケールに応じて、MATLAB の使用する言語で日付が表示されます。
C{1}ans = 3×1 datetime
01 January 2014
01 February 2014
01 March 2014
関数 sprintf を使用して、データ内にある既定でないエスケープ シーケンスを変換します。
フォーム フィード文字 \f を含むテキストを作成します。次に、textscan を使用してテキストを読み取るため、sprintf を呼び出してフォーム フィードを明示的に変換します。
lyric = sprintf('Blackbird\fsinging\fin\fthe\fdead\fof\fnight'); C = textscan(lyric,'%s','delimiter',sprintf('\f')); C{1}
ans = 7×1 cell
{'Blackbird'}
{'singing' }
{'in' }
{'the' }
{'dead' }
{'of' }
{'night' }
textscan は cell 配列 C を返します。
先頭以外の位置からスキャンを再開します。
テキストのスキャンを再開する場合、関数 textscan はそのたびに先頭から読み取ります。他の位置からスキャンを再開するには、textscan の最初の呼び出しで、2 つの出力引数をもつ構文を使用します。
たとえば、lyric という文字ベクトルを作成します。文字ベクトルの最初の語を読み取った後、スキャンを再開します。
lyric = 'Blackbird singing in the dead of night'; [firstword,pos] = textscan(lyric,'%9c',1); lastpart = textscan(lyric(pos+1:end),'%s');
入力引数
開いたテキスト ファイルのファイル識別子は、数値として指定します。textscan でファイルを読み取る前に、fopen を使用してファイルを開き、fileID を取得しなければなりません。
データ型: double
データ フィールドの形式。1 つ以上の変換指定子の文字ベクトルまたは string として指定します。textscan は入力を読み取るときに、formatSpec で指定された形式にデータを一致させようとします。関数 textscan がデータ フィールドの一致に失敗した場合は、読み取りを中断し、中断する前に読み取ったすべてのフィールドを返します。
変換指定子の数は、出力配列 C 内のセル数を決めます。
数値フィールド
この表は、数値入力用に使用可能な変換指定子をまとめたものです。
| 数値入力タイプ | 変換指定子 | 出力クラス |
|---|---|---|
| 整数、符号付き | %d | int32 |
%d8 | int8 | |
%d16 | int16 | |
%d32 | int32 | |
%d64 | int64 | |
| 整数、符号なし | %u | uint32 |
%u8 | uint8 | |
%u16 | uint16 | |
%u32 | uint32 | |
%u64 | uint64 | |
| 浮動小数点数 | %f | double |
%f32 | single | |
%f64 | double | |
%n | double | |
| 16 進数、符号なし整数 | %x | uint64 |
%xu8 | uint8 | |
%xu16 | uint16 | |
%xu32 | uint32 | |
%xu64 | uint64 | |
| 16 進数、符号付き整数 | %xs8 | int8 |
%xs16 | int16 | |
%xs32 | int32 | |
%xs64 | int64 | |
| 2 進数、符号なし整数 | %b | uint64 |
%bu8 | uint8 | |
%bu16 | uint16 | |
%bu32 | uint32 | |
%bu64 | uint64 | |
| 2 進数、符号付き整数 | %bs8 | int8 |
%bs16 | int16 | |
%bs32 | int32 | |
%bs64 | int64 |
非数値フィールド
この表は、非数値文字を含む入力に使用可能な、変換指定子をまとめたものです。
| 非数値入力タイプ | 変換指定子 | 詳細 |
|---|---|---|
| 文字 | %c | 区切り記号を含む任意の 1 文字を読み取ります。 |
| テキスト配列 | %s | 文字ベクトルの cell 配列として読み取ります。 |
%q | 文字ベクトルの cell 配列として読み取ります。テキストが二重引用符 ( 例: | |
| 日付と時刻 | %D | 上記の |
%{ | 上記の datetime 表示形式の詳細については、datetime 配列の 例: | |
| duration | %T | 上記の |
%{ | 上記の duration の表示形式の詳細については、duration 配列の 例: | |
| カテゴリ | %C |
|
| パターンマッチング | %[...] | 文字ベクトルの cell 配列として、大かっこ内の文字のみを最初の不一致文字の前まで読み取ります。このセットに 例: |
%[^...] | 大かっこ内の文字を除外しますが、最初の一致文字の前までを読み込みます。 例: |
オプションの演算子
formatSpec 内の変換指定子は、オプションの演算子を含めることができます。これらの演算子は次の順序で表示されます (明確にするためにスペースも含む)。
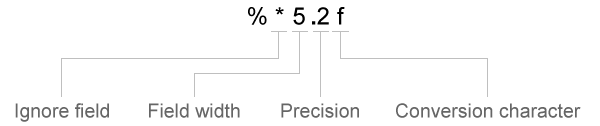
オプションの演算子としては、次のものが挙げられます。
無視するフィールドと文字
textscanは、特定のフィールドまたはフィールドの一部を無視するように指示していない限り、ファイルのすべての文字を順番に読み取ります。パーセント文字 (%) の後にアスタリスク文字 (*) を挿入し、フィールドまたは文字フィールドの一部をスキップします。
演算子
動作
%*kフィールドをスキップします。
kはスキップするフィールドを識別する任意の変換指定子です。textscanはそのようなフィールドには出力セルを作成しません。例:
'%s %*s %s %s %*s %*s %s'(スペースはオプション) は、テキスト
'Blackbird singing in the dead of night'を
'Blackbird' 'in' 'the' 'night'の 4 つの出力セルに変換します。'%*ns'n文字までスキップします。ここで、nはフィールド内の文字数以下の整数です。例:
'%*3s %s'は、'abcdefg'を'defg'に変換します。区切り記号がコンマの場合、同じ区切り記号によって'abcde,fghijkl'は'de';'ijkl'を含む cell 配列に変換されます。'%*nc'区切り記号を含めて
n文字をスキップします。フィールド幅
textscanは、フィールド幅または精度で指定された文字数または桁数、あるいは最初の区切り記号までの、どちらか先に出現した方を読み取ります。小数点、記号 (+または-)、指数文字、および数値指数の桁はフィールド幅の文字および桁としてカウントされます。複素数の場合、フィールド幅は実数部と虚数部の個々の幅を指します。虚数部の場合、フィールド幅には + または − が含まれますが、iまたはjは含まれません。変換指定子内のパーセント文字 (%) の後に数値を挿入して、フィールド幅を指定します。例:
%5fは'123.456'を123.4として読み取ります。例:
%5cは'abcdefg'を'abcde'として読み取ります。フィールド幅演算子を 1 つの文字と組み合わせて
%cのように使用すると、textscanは区切り記号、空白および行末の文字も読み取ります。
例:%7cと指定すると空白を含む 7 文字が読み取られます。したがって、'Day and night'は'Day and'として読み取られます。精度
浮動小数点数 (
%n、%f、%f32、%f64) の場合、読み取る小数点の桁数を指定することができます。例:
%7.2fは'123.456'を123.45として読み取ります。無視するリテラル テキスト
textscanは、formatSpec変換指定子に付加されたテキストを無視します。例:
Level%u8は'Level1'を1として読み取ります。例:
%u8Stepは'2Step'を2として読み取ります。
データ型: char | string
formatSpec の適用回数。正の整数として指定します。
データ型: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64
読み取る入力テキスト。
データ型: char | string
名前と値の引数
出力引数
アルゴリズム
関数 textscan は、オーバーフロー、切り捨て、および NaN、Inf、-Inf の使用に関する MATLAB の規則に応じて、数値フィールドを指定された出力タイプに変換します。たとえば、MATLAB は整数 NaN をゼロとして表示します。関数 textscan が、整数の書式指定子 (%d、%u など) に関連付けられた空のフィールドを検出すると、空の値を NaN ではなくゼロとして返します
データとテキスト変換指定子を照合する場合、textscan は区切り記号または行末の文字を見つけるまで読み取ります。データと数値変換指定子を照合する場合、textscan は数値以外の文字を見つけるまで読み取ります。textscan はデータを特定の変換指定子に照合できなくなると、formatSpec の次の変換指定子にデータを照合しようとします。符号 (+ または -)、指数文字および小数点は数字であると見なされます。
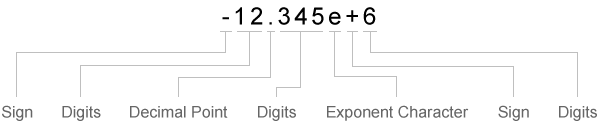
| 符号 | 桁数 | 小数点 | 桁数 | 指数文字 | 符号 | 桁数 |
|---|---|---|---|---|---|---|
| 符号文字が存在する場合、符号文字を 1 文字読み取ります。 | 1 桁以上を読み取ります。 | 小数点が存在する場合、小数点を 1 つ読み取ります。 | 小数点が存在する場合、その直後 1 桁以上を読み取ります。 | 指数文字が存在する場合、指数文字を 1 文字読み取ります。 | 指数文字が存在する場合、符号文字を 1 文字読み取ります。 | 指数文字が存在する場合、それに続く 1 桁以上を読み取ります。 |
関数 textscan は、指定した数値タイプに実数部と虚数部を変換し (%dまたは %f)、複素数全体を複素数フィールドに取り込みます。複素数の有効な形式は、以下のようになります。
±<real>±<imag>i|j | 例: |
±<imag>i|j | 例: |
組み込んだ空白を複素数に含めないでください。textscan は、組み込んだ空白をフィールドの区切り記号と解釈します。