ndvi
正規化植生指標
説明
Add-On Required: この機能にはが必要です。
output = ndvi(spcube,BlockSize=blocksize)
この関数は、入力イメージを個別ブロックに分割して各ブロックを処理し、各ブロックの処理結果を連結して出力行列を形成します。スペクトル イメージは、大きすぎてそのままではシステム メモリに収まらない場合のある多次元データ セットです。そのため、関数 ndvi の実行中にシステムでメモリ不足が発生する場合があります。このような問題に直面した場合は、次の構文を使用してブロック処理を実行します。
たとえば、ndvi(spcube,BlockSize=[50 50]) は、入力イメージを 50 行 50 列のサイズのオーバーラップしないブロックに分割し、各ブロックのピクセルの NDVI 値を計算します。
メモ
Hyperspectral Imaging Library for Image Processing Toolbox™ は、MATLAB® Online™ および MATLAB Mobile™ によってサポートされないため、デスクトップの MATLAB が必要です。
例
ハイパースペクトル データをワークスペースに読み取ります。
hcube = imhypercube("indian_pines.dat");データ キューブ内のピクセルごとに NDVI 値を計算します。
ndviImg = ndvi(hcube);
関数 colorize を使用して、元のデータ キューブからコントラスト ストレッチを行った RGB イメージを推定します。
rgbImg = colorize(hcube,Method="rgb",ContrastStretching=true);元のイメージと NDVI イメージを表示します。
fig = figure(Position=[0 0 1200 600]); axes1 = axes(Parent=fig,Position=[0 0.1 0.4 0.8]); imshow(rgbImg,Parent=axes1) title("RGB Image of Data Cube") axes2 = axes(Parent=fig,Position=[0.45 0.1 0.4 0.8]); imagesc(ndviImg,Parent=axes2) colorbar title("NDVI Image")
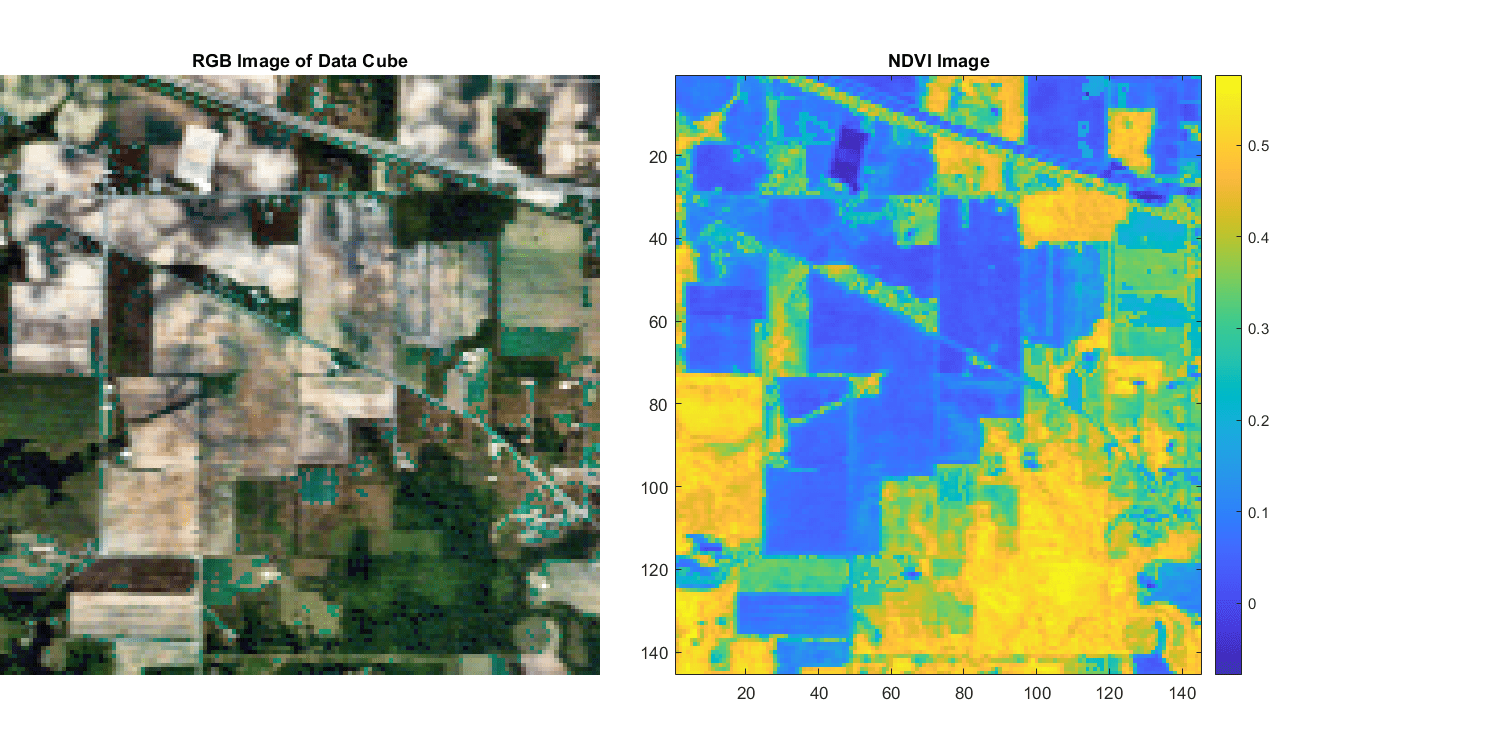
通常、植生領域の NDVI 値は 0.2 を超えます。0.2 以下の NDVI 値は植生がないことを示します。NDVI イメージのしきい値処理を実行し、植生領域をセグメント化します。しきい値を指定します。
threshold = 0.2;
しきい値を適用してバイナリ イメージを作成します。値が 1 のバイナリ イメージ内の領域は、データ キューブ内でしきい値より大きい NDVI 値を持つ植生領域に対応します。その他のすべてのピクセルは値が 0 になります。
bw = ndviImg > threshold;
RGB イメージ上にバイナリ イメージを重ね合わせ、重ね合わせたイメージを表示します。
overlayImg = imoverlay(rgbImg,bw,[0 1 0]);
figure
imagesc(overlayImg)
title("Vegetation Region Overlaid on RGB Image")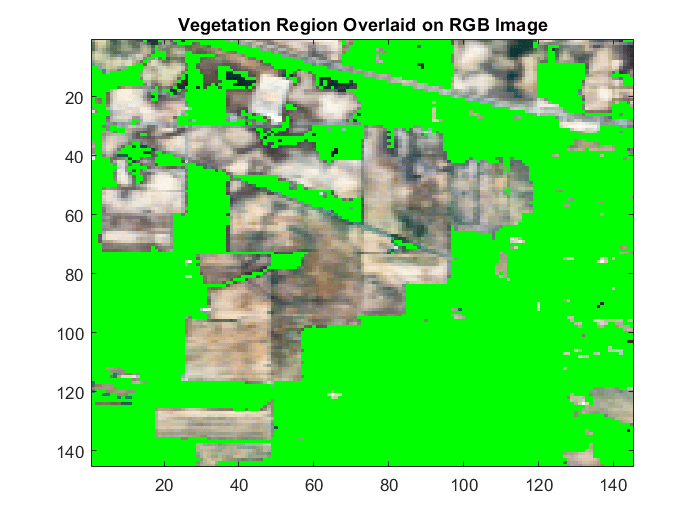
スペクトル バンドのピクセルの総数および 0.2 より大きい NDVI 値を持つピクセルの数に基づいて植被率を計算します。
numVeg = find(bw == 1); datacube = gather(hcube); imgSize = size(datacube,1)*size(datacube,2); vegetationCover = length(numVeg)/imgSize
vegetationCover = 0.5696
この例では、以下を行う方法を説明します。
ハイパースペクトル関数用の超立方体として 2 次元スペクトル データを使用する。
関数
ndviを使用して植生スペクトルと非植生スペクトルを区別する。
この例には、Hyperspectral Imaging Library for Image Processing Toolbox™ が必要です。Hyperspectral Imaging Library for Image Processing Toolbox は、アドオン エクスプローラーからインストールできます。アドオンのインストールの詳細については、アドオンの取得と管理を参照してください。Hyperspectral Imaging Library for Image Processing Toolbox は、MATLAB® Online™ および MATLAB® Mobile™ でサポートされないため、デスクトップの MATLAB® が必要です。
2 次元スペクトル データの読み込み
インディアン パイン データセットの 20 個のエンドメンバーを含む 2 次元スペクトル データをワークスペースに読み込みます。
load("indian_pines_endmembers_20.mat")インディアン パイン データセットの各バンドの波長値をワークスペースに読み込みます。
load("indian_pines_wavelength.mat")ハイパースペクトル関数に使用するテスト データの準備
関数 reshape を使用して 2 次元スペクトル データを 3 次元ボリューム データに形状変更します。
[numSpectra,spectralDim] = size(endmembers); dataCube = reshape(endmembers,[numSpectra 1 spectralDim]);
3 次元ボリューム データ dataCube および波長情報 wavelength を関数 hypercube に指定して、大きさが 1 の次元で 3 次元 hypercube オブジェクトを作成します。
hcube = imhypercube(dataCube,wavelength);
NDVI の計算による植生スペクトルと非植生スペクトルの区別
hypercube オブジェクト内のスペクトルごとに NDVI 値を計算します。
ndviVal = ndvi(hcube);
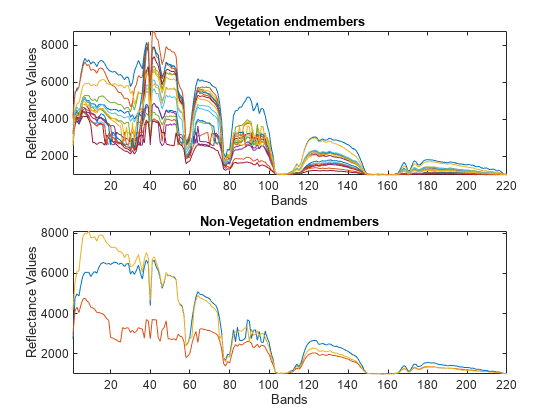
植生スペクトルは一般的に 0 より大きい NDVI 値をもち、非植生スペクトルは一般的に 0 より小さい NDVI 値をもちます。しきい値処理を実行して植生スペクトルと非植生スペクトルを分離します。
index = ndviVal > 0;
植生エンドメンバーと非植生エンドメンバーをプロットします。
subplot(2,1,1) plot(endmembers(index,:)') title("Vegetation endmembers") xlabel("Bands") ylabel("Reflectance Values") axis tight subplot(2,1,2) plot(endmembers(~index,:)') title("Non-Vegetation endmembers") xlabel("Bands") ylabel("Reflectance Values") axis tight
入力引数
出力引数
参照
“Change Detection of Vegetation Cover by NDVI Technique on Catchment Area of the Panchet Hill Dam, India.” International Journal of Research in Geography 2, no. 3 (2016). https://doi.org/10.20431/2454-8685.0203002.
[1] Haboudane, D. “Hyperspectral Vegetation Indices and Novel Algorithms for Predicting Green LAI of Crop Canopies: Modeling and Validation in the Context of Precision Agriculture.” Remote Sensing of Environment 90, no. 3 (April 15, 2004): 337–52. https://doi.org/10.1016/j.rse.2003.12.013.
[2] “Change Detection of Vegetation Cover by NDVI Technique on Catchment Area of the Panchet Hill Dam, India.” International Journal of Research in Geography 2, no. 3 (2016). https://doi.org/10.20431/2454-8685.0203002.