trackerJPDA
Joint probabilistic data association tracker
Description
The trackerJPDA
System object™ is a tracker capable of processing detections of multiple targets from multiple
sensors using the joint probabilistic data association (JPDA) assignment algorithm. The
tracker applies a soft assignment where multiple detections can contribute to each track. The
tracker initializes, confirms, corrects, predicts (performs coasting), and deletes tracks.
Inputs to the tracker are detection reports generated by objectDetection, fusionRadarSensor,
irSensor, or
sonarSensor
objects. The tracker estimates the state vector and state estimate error covariance matrix for
each track. Each detection is assigned to at least one track. If the detection cannot be
assigned to any existing track, the tracker creates a new track.
Any new track starts in a tentative state. If enough detections are
assigned to a tentative track, its status changes to confirmed (see the
ConfirmationThreshold property). If the detection already has a known
classification (i.e., the ObjectClassID field of the returned track is
nonzero), that corresponding track is confirmed immediately. When a track is confirmed, the
tracker considers the track to represent a physical object. If detections are not assigned to
the track within a specifiable number of updates, the track is deleted.
You can enable different JPDA tracking modes by specifying the TrackLogic and MaxNumEvents properties.
Setting the TrackLogic property to
'Integrated'to enable the joint integrated data association (JIPDA) tracker, in which track confirmation and deletion is based on the probability of track existence.Setting the MaxNumEvents property to a finite integer to enable the k-best joint integrated data association (k-best JPDA) tracker, which generates a maximum of k events per cluster.
Setting the ClassFusionMethod property to
"Bayes"to enable detection class fusion.
To track targets using this object:
Create the
trackerJPDAobject and set its properties.Call the object with arguments, as if it were a function.
To learn more about how System objects work, see What Are System Objects?
Creation
Description
tracker = trackerJPDAtrackerJPDA
System object with default property values.
tracker = trackerJPDA(Name,Value)trackerJPDA('FilterInitializationFcn',@initcvukf,'MaxNumTracks',100)
creates a multi-object tracker that uses a constant-velocity, unscented Kalman filter and
allows a maximum of 100 tracks. Enclose each property name in quotes.
Properties
Usage
To process detections and update tracks, call the tracker with arguments, as if it were a function (described here).
Syntax
Description
confirmedTracks = tracker(detections,time)time.
confirmedTracks = tracker(detections,time,costMatrix)
To enable this syntax, set the HasCostMatrixInput property to
true.
confirmedTracks = tracker(___,detectableTrackIDs)detectableTrackIDs. This argument can be used with any of the
previous input syntaxes.
To enable this syntax, set the HasDetectableTrackIDsInput
property to true.
[
also returns a list of tentative tracks and a list of all tracks. You can use any of the
input arguments in the previous syntaxes.confirmedTracks,tentativeTracks,allTracks] = tracker(___)
[
also returns analysis information that can be used for track analysis. You can use any of
the input arguments in the previous syntaxes.confirmedTracks,tentativeTracks,allTracks,analysisInformation] = tracker(___)
Input Arguments
Output Arguments
Object Functions
To use an object function, specify the
System object as the first input argument. For
example, to release system resources of a System object named obj, use
this syntax:
release(obj)
Examples
Construct a trackerJPDA object with a default constant velocity Extended Kalman Filter and 'History' track logic. Set AssignmentThreshold to 100 to allow tracks to be jointly associated.
tracker = trackerJPDA('TrackLogic','History', 'AssignmentThreshold',100,... 'ConfirmationThreshold', [4 5], ... 'DeletionThreshold', [10 10]);
Specify the true initial positions and velocities of the two objects.
pos_true = [0 0 ; 40 -40 ; 0 0]; V_true = 5*[cosd(-30) cosd(30) ; sind(-30) sind(30) ;0 0];
Create a theater plot to visualize tracks and detections.
tp = theaterPlot('XLimits',[-1 150],'YLimits',[-50 50]); trackP = trackPlotter(tp,'DisplayName','Tracks','MarkerFaceColor','g','HistoryDepth',0); detectionP = detectionPlotter(tp,'DisplayName','Detections','MarkerFaceColor','r');
![]()
To obtain the position and velocity, create position and velocity selectors.
positionSelector = [1 0 0 0 0 0; 0 0 1 0 0 0; 0 0 0 0 0 0]; % [x, y, 0] velocitySelector = [0 1 0 0 0 0; 0 0 0 1 0 0; 0 0 0 0 0 0 ]; % [vx, vy, 0]
Update the tracker with detections, display cost and marginal probability of association information, and visualize tracks with detections.
dt = 0.2; for time = 0:dt:30 % Update the true positions of objects. pos_true = pos_true + V_true*dt; % Create detections of the two objects with noise. detection(1) = objectDetection(time,pos_true(:,1)+1*randn(3,1)); detection(2) = objectDetection(time,pos_true(:,2)+1*randn(3,1)); % Step the tracker through time with the detections. [confirmed,tentative,alltracks,info] = tracker(detection,time); % Extract position, velocity and label info. [pos,cov] = getTrackPositions(confirmed,positionSelector); vel = getTrackVelocities(confirmed,velocitySelector); meas = cat(2,detection.Measurement); measCov = cat(3,detection.MeasurementNoise); % Update the plot if there are any tracks. if numel(confirmed)>0 labels = arrayfun(@(x)num2str([x.TrackID]),confirmed,'UniformOutput',false); trackP.plotTrack(pos,vel,cov,labels); end detectionP.plotDetection(meas',measCov); drawnow; % Display the cost and marginal probability of distribution every eight % seconds. if time>0 && mod(time,8) == 0 disp(['At time t = ' num2str(time) ' seconds,']); disp('The cost of assignment was: ') disp(info.CostMatrix); disp(['Number of clusters: ' num2str(numel(info.Clusters))]); if numel(info.Clusters) == 1 disp('The two tracks were in the same cluster.') disp('Marginal probabilities of association:') disp(info.Clusters{1}.MarginalProbabilities) end disp('-----------------------------') end end
At time t = 8 seconds,
The cost of assignment was:
1.0e+03 *
0.0020 1.1523
1.2277 0.0053
Number of clusters: 2
-----------------------------
At time t = 16 seconds,
The cost of assignment was:
1.3968 4.5123
2.0747 1.9558
Number of clusters: 1
The two tracks were in the same cluster.
Marginal probabilities of association:
0.8344 0.1656
0.1656 0.8344
0.0000 0.0000
-----------------------------
At time t = 24 seconds,
The cost of assignment was:
1.0e+03 *
0.0018 1.2962
1.2664 0.0013
Number of clusters: 2
-----------------------------
![]()
Create two objectDetection objects at time = 0 and = 1, respectively. The ObjectClassID of the two detections is 1. Specify the confusion matrix for each detection.
detection0 = objectDetection(0,[0 0 0],... ObjectClassID=1,... ObjectClassParameters=struct("ConfusionMatrix",[0.6 0.2 0.2; 0.2 0.6 0.2; 0.2 0.2 0.6])); detection1 = objectDetection(1,[0 0 0],... ObjectClassID=1,... ObjectClassParameters=struct("ConfusionMatrix",[0.5 0.3 0.2; 0.3 0.5 0.2; 0.2 0.2 0.6]));
Create a trackerJPDA object. Set the class fusion method to "Bayes" and specify the initial probability of each class as 1/3.
tracker = trackerJPDA(ClassFusionMethod="Bayes",InitialClassProbabilities=[1/3 1/3 1/3])tracker =
trackerJPDA with properties:
TrackerIndex: 0
FilterInitializationFcn: 'initcvekf'
MaxNumEvents: Inf
EventGenerationFcn: 'jpdaEvents'
MaxNumTracks: 100
MaxNumDetections: Inf
MaxNumSensors: 20
TimeTolerance: 1.0000e-05
AssignmentThreshold: [30 Inf]
InitializationThreshold: 0
DetectionProbability: 0.9000
ClutterDensity: 1.0000e-06
OOSMHandling: 'Terminate'
TrackLogic: 'History'
ConfirmationThreshold: [2 3]
DeletionThreshold: [5 5]
HitMissThreshold: 0.2000
HasCostMatrixInput: false
HasDetectableTrackIDsInput: false
StateParameters: [1×1 struct]
ClassFusionMethod: 'Bayes'
InitialClassProbabilities: [0.3333 0.3333 0.3333]
ClassFusionWeight: 0.7000
NumTracks: 0
NumConfirmedTracks: 0
EnableMemoryManagement: false
Update the track with the first and second detections sequentially.
tracker(detection0,0); [tracks,~,~,info] = tracker(detection1,1);
Show the maintained tracks and analysis information.
disp(tracks)
objectTrack with properties:
TrackID: 1
BranchID: 0
SourceIndex: 0
UpdateTime: 1
Age: 2
State: [6×1 double]
StateCovariance: [6×6 double]
StateParameters: [1×1 struct]
ObjectClassID: 1
ObjectClassProbabilities: [0.7409 0.1530 0.1060]
TrackLogic: 'History'
TrackLogicState: [1 1 0 0 0]
IsConfirmed: 1
IsCoasted: 0
IsSelfReported: 1
ObjectAttributes: [1×1 struct]
disp(info)
OOSMDetectionIndices: [1×0 uint32]
TrackIDsAtStepBeginning: 1
UnassignedTracks: [1×0 uint32]
UnassignedDetections: [1×0 uint32]
CostMatrix: 13.8823
Clusters: {[1×1 struct]}
InitializedTrackIDs: [1×0 uint32]
DeletedTrackIDs: [1×0 uint32]
TrackIDsAtStepEnd: 1
ClassCostMatrix: -0.1823
Display the cluster information.
disp(info.Clusters{:}) DetectionIndices: 1
TrackIDs: 1
ValidationMatrix: [1 1]
SensorIndex: 1
TimeStamp: 1
MarginalProbabilities: [2×1 double]
Likelihood: [2×2 double]
ClassLikelihood: [2×2 double]
Algorithms
In the typical workflow for a tracking system, the tracker needs to determine if a detection can be associated with any of the existing tracks. If the tracker only maintains one track, the assignment can be done by evaluating the validation gate around the predicted measurement and deciding if the measurement falls within the validation gate. In the measurement space, the validation gate is a spatial boundary, such as a 2-D ellipse or a 3-D ellipsoid, centered at the predicted measurement. The validation gate is defined using the probability information (state estimation and covariance, for example) of the existing track, such that the correct or ideal detections have high likelihood (97% probability, for example) of falling within this validation gate.
However, if a tracker maintains multiple tracks, the data association process becomes more complicated, because one detection can fall within the validation gates of multiple tracks. For example, in the following figure, tracks T1 and T2 are actively maintained in the tracker, and each of them has its own validation gate. Since the detection D2 is in the intersection of the validation gates of both T1 and T2, the two tracks (T1 and T2) are connected and form a cluster. A cluster is a set of connected tracks and their associated detections.
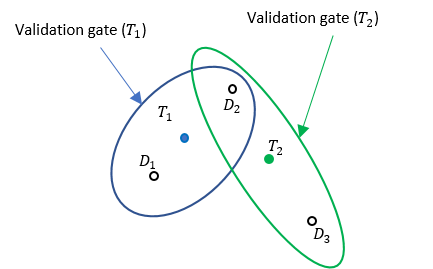
To represent the association relationship in a cluster, the validation matrix is commonly used. Each row of the validation matrix corresponds to a detection while each column corresponds to a track. To account for the eventuality of each detection being clutter, a first column is added and usually referred to as "Track 0" or T0. If detection Di is inside the validation gate of track Tj, then the (i, j+1) entry of the validation matrix is 1. Otherwise, it is zero. For the cluster shown in the figure, the validation matrix Ω is
Note that all the elements in the first column of Ω are 1, because any detection can be clutter or false alarm. One important step in the logic of joint probabilistic data association (JPDA) is to obtain all the feasible independent joint events in a cluster. Two assumptions for the feasible joint events are:
A detection cannot be emitted by more than one track.
A track cannot be detected more than once by the sensor during a single scan.
Based on these two assumptions, feasible joint events (FJEs) can be formulated. Each FJE is mapped to an FJE matrix Ωp from the initial validation matrix Ω. For example, with the validation matrix Ω, eight FJE matrices can be obtained:
As a direct consequence of the two assumptions, the Ωp matrices have
exactly one "1" value per row. Also, except for the first column which maps to clutter,
there can be at most one "1" per column. When the number of connected tracks grows in a
cluster, the number of FJE increases rapidly. The jpdaEvents function
uses an efficient depth-first search algorithm to generate all the feasible joint event
matrices.
References
[1] Fortmann, T., Y. Bar-Shalom, and M. Scheffe. "Sonar Tracking of Multiple Targets Using Joint Probabilistic Data Association." IEEE Journal of Ocean Engineering. Vol. 8, Number 3, 1983, pp. 173-184.
[2] Musicki, D., and R. Evans. "Joint Integrated Probabilistic Data Association: JIPDA." IEEE transactions on Aerospace and Electronic Systems. Vol. 40, Number 3, 2004, pp 1093-1099.
[3] Bar-Shalom, Y., et al. “Tracking with Classification-Aided Multiframe Data Association.” IEEE Transactions on Aerospace and Electronic Systems, vol. 41, no. 3, July 2005, pp. 868–78.
[4] Bar-Shalom, Y., et al. “Multitarget-multisensor tracking: principles and techniques” Vol. 19. Storrs, CT: YBs, 1995
[5] Challa, Sudha, editor. Fundamentals of Object Tracking. Cambridge University Press, 2011.
Extended Capabilities
Version History
Introduced in R2019aSee Also
Functions
Objects
objectDetection|trackingKF|trackingUKF|trackingEKF|trackingCKF|trackingIMM|trackingABF|trackHistoryLogic|objectTrack|staticDetectionFuser|trackerTOMHT|trackerGNN