LIME を使用したネットワーク予測の理解
この例では、Locally Interpretable Model-agnostic Explanations (LIME) を使用し、深層ニューラル ネットワークによる分類の判定理由を解釈する方法を説明します。
深層ニューラル ネットワークは極めて複雑であり、その判定は解釈が困難な場合もあります。LIME 技術では、回帰木など、より単純かつ解釈しやすいモデルを使用し、深層ニューラル ネットワークの分類動作を近似します。この単純なモデルの判定を解釈することにより、ニューラル ネットワークの判定に関する洞察が得られます [1]。この単純なモデルは、深層ニューラル ネットワークに対する特徴量の重要度に関するプロキシとして、入力データの特徴量の重要度を判断するために使用されます。
特定の特徴が深層ネットワークの分類判定に極めて重要である場合、その特徴を削除すると分類スコアに著しい影響が及びます。そのため、この特徴は、単純なモデルにとっても重要です。
Deep Learning Toolbox には、LIME 技術によって判断された特徴量重要度マップを計算する関数 imageLIME が用意されています。イメージ用の LIME アルゴリズムは、次によって動作します。
特徴へのイメージのセグメント化。
特徴をランダムに追加または除外することによる、多数の合成イメージの生成。除外された特徴は、すべてのピクセルがイメージ平均の値で置き換えられているため、それらがネットワークに有益な情報を含むことはありません。
深層ネットワークでの合成イメージの分類。
各合成イメージに関するイメージの特徴の有無を、ターゲット クラスのスコアに対するバイナリ回帰予測子として使用することによる、単純な回帰モデルの当てはめ。このモデルは、観測領域における複雑な深層ニューラル ネットワークの動作を近似します。
単純なモデルを使用した特徴量の重要度の計算。および、その特徴量の重要度を、モデルにとって最も重要なイメージの部分を示すマップへと変換すること。
LIME 技術によって得られた結果を、他の説明可能性技術 (オクルージョン感度、Grad-CAM など) と比較できます。これらの関連技術の使用方法の例については、次の例を参照してください。
事前学習済みのネットワークとイメージの読み込み
事前学習済みの GoogLeNet ネットワークと対応するクラス名を読み込みます。これには、Deep Learning Toolbox™ Model for GoogLeNet Network サポート パッケージが必要です。このサポート パッケージがインストールされていない場合、ソフトウェアによってダウンロード用リンクが表示されます。使用可能なすべてのネットワークについては、事前学習済みの深層ニューラル ネットワークを参照してください。
[net,classNames] = imagePretrainedNetwork("googlenet");イメージの入力サイズとネットワークの出力クラスを抽出します。
inputSize = net.Layers(1).InputSize(1:2);
イメージを読み込みます。イメージは Sherlock という名前のレトリバーです。イメージのサイズをネットワークの入力サイズに変更します。
img = imread("sherlock.jpg");
img = imresize(img,inputSize);イメージを分類します。単一の観測値を使用して予測を行うには、関数 predict を使用します。予測スコアをラベルに変換するには、関数 scores2label を使用します。GPU を使用するには、まずデータを gpuArray に変換します。GPU を使用するには、Parallel Computing Toolbox™ ライセンスとサポートされている GPU デバイスが必要です。サポートされているデバイスの詳細については、GPU 計算の要件 (Parallel Computing Toolbox)を参照してください。
if canUseGPU img = gpuArray(img); end scores = predict(net,single(img)); [label,score] = scores2label(scores,classNames); [topScores,topIdx] = maxk(scores, 3); topClasses = classNames(topIdx); imshow(img) titleString = compose("%s (%.2f)",topClasses,gather(topScores)'); title(sprintf(join(titleString, "; ")));

GoogLeNet は Sherlock を golden retriever として分類します。当然ながら、ネットワークは Labrador retriever クラスにも高い確率を割り当てています。imageLIME を使用することで、ネットワークがイメージのどの部分を使用してこの分類判定を下したかを理解できます。
ネットワークが分類に使用するイメージ領域の特定
LIME を使用することで、クラスにとってイメージのどの部分が重要かを理解できます。最初に、golden retriever の予測クラスを確認します。イメージのどの部分がこのクラスを提示するのでしょうか。
既定では、imageLIME は、イメージをスーパーピクセルにセグメント化することで、入力イメージの特徴を特定します。このセグメント化の方法では、Image Processing Toolbox が必要になります。ただし、Image Processing Toolbox がなければ、オプション "Segmentation","grid" を使用し、イメージを正方形の特徴にセグメント化できます。
関数 imageLIME を使用し、さまざまなスーパーピクセルの特徴量の重要度をマッピングします。既定では、単純なモデルは回帰木です。
channel = find(label == categorical(classNames)); map = imageLIME(net,img,channel);
LIME マップを重ね合わせた Sherlock のイメージを表示します。
figure imshow(img) hold on imagesc(map,AlphaData=0.5) colormap jet colorbar title(sprintf("Image LIME (%s)", ... label)) hold off
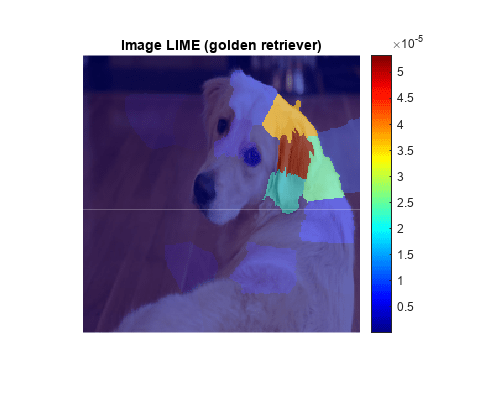
このマップには、golden retriever の分類にとってイメージのどの領域が重要かが示されます。マップの赤い領域は重要度が高い部分です。この領域を削除すると、golden retriever クラスのスコアが下がります。ネットワークは、犬の顔と耳に焦点を当て、この犬がゴールデン レトリバーであると予測します。これは、他の説明可能性技術 (オクルージョン感度、Grad-CAM など) の場合と同じ結果です。
異なるクラスの結果との比較
GoogLeNet は、golden retriever クラスのスコアを 55%、Labrador retriever クラスのスコアを 40% と予測しています。これらのクラスは非常によく似ています。各クラスについて計算された LIME マップを比較することで、犬のどの部分が両クラスにとってより重要かを判断できます。
同じ設定を使用し、Labrador retriever クラスの LIME マップを計算します。
secondClass = topClasses(2); channel = find(secondClass == categorical(classNames)); map = imageLIME(net,img,channel); figure; imshow(img) hold on imagesc(map,AlphaData=0.5) colormap jet colorbar title(sprintf("Image LIME (%s)",secondClass)) hold off
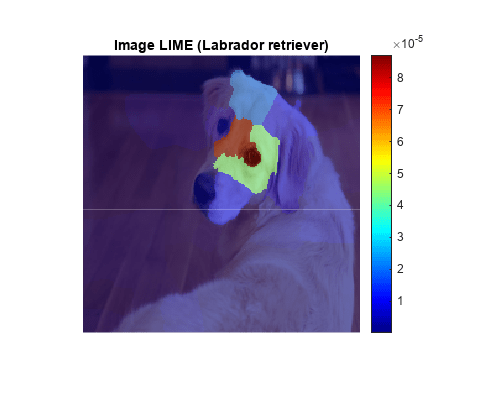
Labrador retriever クラスの場合、ネットワークは、犬の耳ではなく、鼻と目により焦点を当てています。両方のマップで犬の頭部前面が強調表示されていますが、ネットワークは犬の耳と首が golden retriever クラスを示し、犬の目と鼻が Labrador retriever クラスを示すと判断しています。
LIME と Grad-CAM の比較
他のイメージ解釈可能性の手法 (Grad-CAM など) では、結果として得られたマップをアップサンプリングし、イメージの重要領域の滑らかなヒートマップを生成します。imageLIME で見た目が似たマップを生成できます。そのためには、正方形または長方形の特徴量の重要度を計算し、結果として得られたマップをアップサンプリングします。
不規則なスーパーピクセルではなく、正方形の特徴のグリッドにイメージをセグメント化するには、名前と値のペア "Segmentation","grid" を使用します。"OutputUpsampling","bicubic" を設定し、双三次内挿を使用することにより、計算されたマップがイメージ解像度に一致するようにアップサンプリングします。
最初に計算されたマップの解像度を上げるには、名前と値のペア "NumFeatures",100 を指定することにより、特徴の数を 100 まで増やします。イメージは正方形であるため、10 x 10 グリッドの特徴が生成されます。
LIME 技術により、元の観測値に基づいて合成イメージが生成されます。その際、いくつかの特徴がランダムに選択され、選択された特徴に含まれるすべてのピクセルがイメージのピクセルの平均値に置き換えられ、事実上、それらの特徴が削除されます。"NumSamples",6000 を設定し、ランダムなサンプルの数を 6000 まで増やします。特徴の数を増やした場合、通常、サンプルの数を増やすとより良い結果が得られます。
既定では、関数 imageLIME はシンプルなモデルである回帰木を使用しています。代わりに、"Model","linear" を設定し、LASSO 回帰による線形回帰モデルを当てはめます。
channel = find(label == categorical(classNames)); map = imageLIME(net,img,channel, ... Segmentation="grid", ... OutputUpsampling="bicubic", ... NumFeatures=100, ... NumSamples=6000, ... Model="linear"); imshow(img) hold on imagesc(map,AlphaData=0.5) colormap jet title(sprintf("Image LIME (%s - linear model)", ... label)) hold off

LIME 技術の場合も、Grad-CAM で計算された勾配マップと同様に、golden retriever の予測にとって犬の耳が非常に重要であると認識されます。
最も重要な特徴のみの表示
LIME の結果をプロットする場合、通常、最も重要ないくつかの特徴のみが示されるようにプロットします。関数 imageLIME を使用する際、計算で使用した特徴マップを取得して各特徴量の重要度を計算することもできます。その結果に基づいて、スーパーピクセルの最も重要な特徴を 4 つ決定し、その 4 つの最も重要な特徴のみをイメージに表示します。
LIME マップを計算し、特徴マップと計算された各特徴量の重要度を取得します。
[map,featureMap,featureImportance] = imageLIME(net,img,channel);
最も重要な 4 つの特徴のインデックスを見つけます。
numTopFeatures = 4; [~,idx] = maxk(featureImportance,numTopFeatures);
次に、最も重要な 4 つのスーパーピクセルに含まれるピクセルのみが表示されるように、LIME マップを使用してイメージをマスクします。マスクしたイメージを表示します。
mask = ismember(featureMap,idx); maskedImg = uint8(mask).*img; figure imshow(maskedImg); title(sprintf("Image LIME (%s - top %i features)", ... label, numTopFeatures))

参考文献
[1] Ribeiro, Marco Tulio, Sameer Singh, and Carlos Guestrin. “‘Why Should I Trust You?’: Explaining the Predictions of Any Classifier.” In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 1135–44. San Francisco California USA: ACM, 2016. https://doi.org/10.1145/2939672.2939778.
参考
imagePretrainedNetwork | dlnetwork | trainingOptions | trainnet | occlusionSensitivity | imageLIME | gradCAM