ビッグ データを使用した深層学習
通常、深層ニューラル ネットワークの学習では大量のデータが必要となりますが、データがメモリに収まらないことがよくあります。大きすぎてメモリに収まらないデータ セットを使用して問題を解決するために、複数のコンピューターは必要ありません。代わりに、データ セットの一部が含まれるミニバッチに学習データを分割します。ミニバッチに対して反復処理を行うことで、すべてのデータを一度にメモリへ読み込ませることなく、大きなデータ セットでネットワークに学習させることができます。
データが大きすぎてメモリに収まらない場合は、データストアを使用してデータのミニバッチを処理し、学習と推論を行います。MATLAB® では、さまざまなアプリケーション向けに調整された多様なデータストアが豊富に用意されています。各種アプリケーション向けのデータストアの詳細については、深層学習用のデータストアを参照してください。
augmentedImageDatastore は、機械学習とコンピューター ビジョンの応用に、イメージ データのバッチの前処理と拡張を行うことを目的として設計されています。詳細については、イメージの深層学習向け前処理を参照してください。
ビッグ データの並列処理
大量のデータを使用してネットワークに学習させる場合、並列学習が有効なことがあります。それにより、同時に複数のミニバッチを使用して学習させることができるため、ネットワークの学習時間が短縮されます。
GPU を使用して学習させることを推奨します。GPU を使用できない場合にのみ、CPU を使用するようにしてください。通常、学習と推論のどちらの場合も GPU と比べて CPU は非常に低速です。一般に、複数の CPU コアで実行するよりも 1 つの GPU で実行する方がはるかに高いパフォーマンスを得られます。
並列学習の詳細については、Scale Up Deep Learning in Parallel, on GPUs, and in the Cloudを参照してください。
バックグラウンドでのデータの前処理
大量のデータを前処理すると、学習時間が大幅に長くなる可能性があります。この前処理を高速化するには、データストアから学習データをバックグラウンドまたは並列で取得し、前処理します。
次の図に示すように、取得、前処理、および学習計算を逐次実行すると、GPU (または他のハードウェア) の使用率が低い場合にダウンタイムが発生する可能性があります。GPU が現在のバッチを処理している間に、バックグラウンド プールまたは並列ワーカーを使用して学習データの次のバッチを取得し、前処理させることで、ハードウェアの使用率が向上し、学習を高速化できる可能性があります。大きなイメージを操作する場合など、学習データに大幅な前処理が必要な場合は、バックグラウンドまたは並列での前処理を使用します。
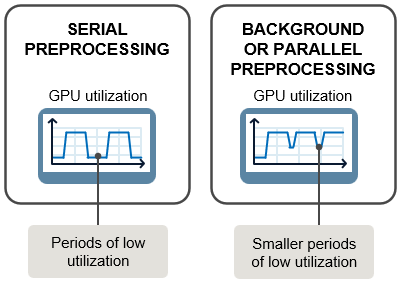
バックグラウンドおよび並列での前処理では、学習時に並列プールを使用してデータを取得および前処理します。バックグラウンド前処理では、スレッドベースの環境である backgroundPool を使用します。また、並列前処理では現在の並列プールを使用するか、プールが開いていない場合は、既定でプロセスベースの環境となる既定クラスター プロファイルを使用してプールを起動します。スレッドベースのプールにはプロセスベースのプールに比べていくつかの利点があるため、可能な場合はバックグラウンド前処理を使用する必要があります。ただし、前処理がスレッドでサポートされていない場合、またはプール内のワーカーの数を制御する必要がある場合は、並列前処理を使用します。スレッドベースおよびプロセスベースの環境の詳細については、スレッドベースの環境またはプロセスベースの環境の選択 (Parallel Computing Toolbox)を参照してください。
バックグラウンドまたは並列でデータを前処理するには、次のいずれかのオプションを使用します。
組み込み学習の場合は、
trainingOptions関数を使用して、PreprocessingEnvironmentオプションを"background"または"parallel"として指定する。カスタム学習ループでは、
minibatchqueueのPreprocessingEnvironmentプロパティを"background"または"parallel"に設定する。
PreprocessingEnvironment オプションを "parallel" に設定することは、ローカル並列プールでのみサポートされており、Parallel Computing Toolbox™ が必要になります。
"background" オプションまたは "parallel" オプションを使用するには、入力データストアがサブセット化可能または分割可能でなければなりません。カスタム データストアには matlab.io.datastore.Subsettable クラスが実装されていなければなりません。
クラウドでのビッグ データの処理
クラウドにデータを保存すると、クラウド リソースを作成するたびに大量のデータをアップロードまたはダウンロードする必要がなくなり、クラウド アプリケーションに簡単にアクセスできるようになります。AWS® と Azure® は、AWS S3 や Azure Blob Storage といったデータ ストレージ サービスをそれぞれ提供しています。
大量のデータを転送するのにかかる時間とコストを節約するため、クラウドへのデータ保存に使用しているのと同じクラウド プロバイダーとリージョンを使用して深層学習アプリケーション用のクラウド リソースを設定することを推奨します。
クラウドに保存されたデータに MATLAB からアクセスするには、マシンにアクセス資格情報を設定する必要があります。環境変数を使用すると、MATLAB 内部からアクセスできるように設定できます。MATLAB クライアントからクラウド データにアクセスできるように環境変数を設定する方法の詳細については、リモート データの操作を参照してください。リモート クラスター内の並列ワーカーに関する環境変数を設定する方法の詳細については、ワーカー上での環境変数の設定 (Parallel Computing Toolbox)を参照してください。
データをクラウドにアップロードして MATLAB からそのデータにアクセスする方法を示す例については、AWS での深層学習データの処理およびWork with Deep Learning Data in Azureを参照してください。
クラウドでの深層学習の詳細については、クラウドでの深層学習を参照してください。
参考
trainnet | trainingOptions | dlnetwork | minibatchqueue