スレッドベースの環境またはプロセスベースの環境の選択
Parallel Computing Toolbox™ を使用すると、スレッドベースまたはプロセスベースの環境などのさまざまな並列環境で並列コードを実行できます。これらの環境には異なる利点があります。
スレッドベースの環境は、プロセス ワーカーで使用できる MATLAB® 関数のサブセットのみをサポートすることに注意してください。サポートされていない関数については、MathWorks テクニカル サポート チームまでご連絡ください。サポートの詳細については、スレッドベースの環境に関するサポートの確認を参照してください。
並列環境の選択
選択した並列環境のタイプに応じて、プロセス ワーカーまたはスレッドワーカーのいずれかで機能が実行されます。自分に適した環境を選択するには、以下の図と表を参照してください。
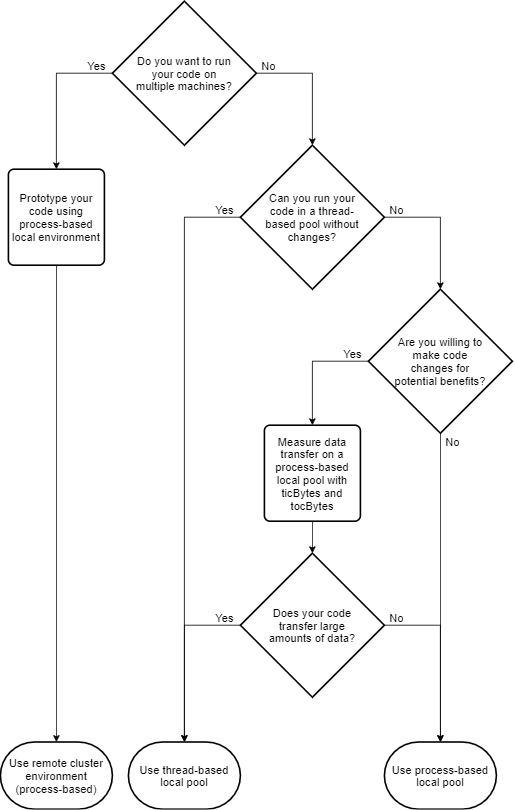
parfor、parfevalなどの並列プール機能を使用するには、選択した環境で関数parpoolを使用して並列プールを作成します。環境 推奨事項 例 ローカル マシン上のスレッドベースの環境 メモリ使用量を削減し、スケジューリングを高速化し、データ転送コストを低減するには、この設定を使用します。
parpool('Threads')メモ
'Threads'を選択する場合は、コードがサポートされていることを確認してください。詳細については、スレッドベースの環境に関するサポートの確認を参照してください。スレッドベースのプールから十分なメリットが受けられるかどうかを調べるには、
ticBytesとtocBytesを使用してプロセスベースのプールのデータ転送量を測定します。100 MB を上回るほどデータ転送量が大きい場合は、'Threads'を使用してください。ローカル マシン上のプロセスベースの環境 ほとんどのユース ケース、およびクラスターまたはクラウドにスケーリングする前のプロトタイピングには、この設定を使用します。
parpool('Processes')リモート クラスター上のプロセスベースの環境 計算をスケール アップするには、この設定を使用します。
parpool('MyCluster')MyClusterはクラスター プロファイルの名前です。batchなどのクラスター機能を使用するには、選択した環境で関数parclusterを使用してクラスター オブジェクトを作成します。クラスター機能は、プロセスベースの環境でのみサポートされています。環境 推奨事項 例 ローカル マシン上のプロセスベースの環境 十分なローカル リソースがある場合、あるいはクラスターまたはクラウドにスケーリングする前のプロトタイプを作成するには、この設定を使用します。
parcluster('Processes')リモート クラスター上のプロセスベースの環境 計算をスケール アップするには、この設定を使用します。
parcluster('MyCluster')MyClusterはクラスター プロファイルの名前です。
推奨事項
プロセスベースの環境を既定にすることを推奨します。
並列言語を完全にサポートする。
以前のリリースとの下位互換性を備える。
クラッシュ時に、より高いロバスト性を有する。
外部ライブラリをスレッド セーフにする必要がない。
以下の場合にスレッドベースの環境を選択します。
並列コードがスレッドベースの環境でサポートされている。
メモリ使用量の削減、スケジューリングの高速化、およびデータ転送コストの低減が必要である。
プロセス ワーカーとスレッド ワーカーの比較
以下に、スレッド ワーカーの効率を活用する例として、プロセス ワーカーとスレッド ワーカーとのパフォーマンス比較を示します。
何らかのデータを作成します。
X = rand(10000, 10000);
プロセス ワーカーの並列プールを作成します。
pool = parpool('Processes');Starting parallel pool (parpool) using the 'Processes' profile ... Connected to the parallel pool (number of workers: 6).
何らかの並列コードの実行時間およびデータ転送量を測定します。この例では、parfeval の実行を使用します。
ticBytes(pool);
tProcesses = timeit(@() fetchOutputs(parfeval(@sum,1,X,'all')))
tocBytes(pool)tProcesses = 3.9060
BytesSentToWorkers BytesReceivedFromWorkers
__________________ ________________________
1 0 0
2 0 0
3 0 0
4 0 0
5 5.6e+09 16254
6 0 0
Total 5.6e+09 16254 データ転送量の著しいことが分かります。データ転送コストの負担を回避するために、スレッド ワーカーを使用できます。現在の並列プールを削除し、スレッドベースの並列プールを作成します。
delete(pool);
pool = parpool('Threads');同じコードの実行時間を測定します。
tThreads = timeit(@() fetchOutputs(parfeval(@sum,1,X,'all')))tThreads = 0.0232
時間を比較します。
fprintf('Without data transfer, this example is %.2fx faster.\n', tProcesses/tThreads)Without data transfer, this example is 168.27x faster.
スレッド ワーカーのパフォーマンスがプロセス ワーカーより高くなっています。これは、スレッド ワーカーはデータ X をコピーせずに使用でき、スケジュールのオーバーヘッドが低いためです。
プロセスベースおよびスレッドベースのプールにおける最適化問題の並列求解
この例では、プロセスベースおよびスレッドベースのプールを使用して最適化問題の解を並列で求める方法を説明します。
スレッドベースのプールはデータ転送の低減、スケジューリングの高速化、およびメモリ使用量の低減に向けて最適化されているため、結果としてアプリケーションで高いパフォーマンスが得られます。
問題の説明
問題は、大砲の位置と角度を変更して、壁を越えてできるだけ遠くに発射体を射出することです。大砲の砲口速度は 300 m/s です。壁の高さは 20 m です。大砲が壁に近すぎると、射出角度が大きすぎ、発射体の飛行距離が十分に長くなりません。大砲と壁が離れすぎると、発射体の飛行距離が十分に長くなりません。問題の網羅的な詳細については、並列で常微分方程式を最適化する (Global Optimization Toolbox)、または Surrogate Optimization のビデオの後半部分を参照してください。
MATLAB での問題の定式化
問題を解くには、Global Optimization Toolbox から patternsearch ソルバーを呼び出します。この目的関数は、指定された位置と角度について、発射体が壁を越えて着地する距離を計算する補助関数 cannonobjective の中にあります。制約は、発射体が壁に衝突するか、または地面に衝突する前に壁に到達するかを計算する補助関数 cannonconstraint の中にあります。これらの補助関数は個別のファイルに含まれており、この例の実行時に表示できます。
patternsearch ソルバーに以下の入力を設定します。Parallel Computing Toolbox を使用するには、最適化オプションの 'UseParallel' を true に設定しなければならない点に注意してください。
lb = [-200;0.05]; ub = [-1;pi/2-.05]; x0 = [-30,pi/3]; opts = optimoptions('patternsearch',... 'UseCompletePoll', true, ... 'Display','off',... 'UseParallel',true); % No linear constraints, so set these inputs to empty: A = []; b = []; Aeq = []; beq = [];
プロセスベースのプールでの求解
比較の目的で、まずプロセスベースの並列プールを使用してこの問題を解きます。
プロセス ワーカーの並列プールを起動します。
p = parpool('Processes');Starting parallel pool (parpool) using the 'Processes' profile ... Connected to the parallel pool (number of workers: 6).
後で同じ計算を再現するために、乱数発生器のシードに既定値を使用します。
rng default;ループを使用して問題の解を数回求め、結果を平均します。
tProcesses = zeros(5,1); for repetition = 1:numel(tProcesses) tic [xsolution,distance,eflag,outpt] = patternsearch(@cannonobjective,x0, ... A,b,Aeq,beq,lb,ub,@cannonconstraint,opts); tProcesses(repetition) = toc; end tProcesses = mean(tProcesses)
tProcesses = 2.7677
スレッドベースのプールとの比較に備えて、現在の並列プールを削除します。
delete(p);
スレッドベースのプールでの求解
スレッド ワーカーの並列プールを起動します。
p = parpool('Threads');Starting parallel pool (parpool) using the 'Threads' profile ... Connected to the parallel pool (number of workers: 6).
乱数発生器を既定の設定に戻して、前と同じコードを実行します。
rng default tThreads = zeros(5,1); for repetition = 1:numel(tThreads) tic [xsolution,distance,eflag,outpt] = patternsearch(@cannonobjective,x0, ... A,b,Aeq,beq,lb,ub,@cannonconstraint,opts); tThreads(repetition) = toc; end tThreads = mean(tThreads)
tThreads = 1.5790
スレッド ワーカーとプロセス ワーカーのパフォーマンスを比較します。
fprintf('In this example, thread workers are %.2fx faster than process workers.\n', tProcesses/tThreads)In this example, thread workers are 1.75x faster than process workers.
スレッドベースのプールの最適化によりパフォーマンスが向上していることが分かります。
計算が完了したら、並列プールを削除します。
delete(p);
スレッドベースの環境とは
スレッドベースの環境では、並列言語機能は、マシンのコアでコードを実行する計算スレッドによりサポートされているワーカー上で実行されます。計算スレッドは、同じプロセス内に共存し、メモリを共有できるという点で、計算プロセスと異なります。
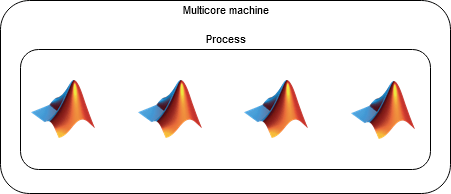
スレッドベースの環境は、プロセスベースの環境と比べて以下の利点があります。
スレッド ワーカーはメモリを共有できるため、コピーせずに数値データにアクセスでき、メモリ効率が高い。
スレッド間の通信時間が短い。このため、タスクのスケジューリングまたはワーカー間の通信のオーバーヘッドが小さい。
スレッドベースの環境を使用するときには、以下の考慮事項に留意してください。
コードがスレッドベースの環境でサポートされていることを確認する。詳細については、スレッドベースの環境に関するサポートの確認を参照してください。
ワーカーから外部ライブラリを使用する場合は、ライブラリ関数がスレッドセーフであることを確認しなければならない。
プロセスベースの環境とは
プロセスベースの環境では、並列言語機能は、マシンのコアでコードを実行する計算プロセスによりサポートされているワーカー上で実行されます。計算プロセスは、相互に独立しているという点で計算スレッドと異なります。
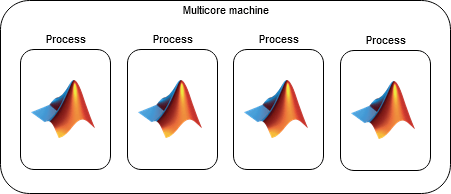
プロセスベースの環境は、スレッドベースの環境と比べて以下の利点があります。
すべての言語機能をサポートし、以前のリリースとの下位互換性を有する。
クラッシュ時に、より高いロバスト性を有する。プロセス ワーカーがクラッシュしても、MATLAB クライアントはクラッシュしません。プロセス ワーカーがクラッシュした場合、コードで
spmdまたは分散配列を使用していなければ、残りのワーカーは処理を継続できます。ワーカーから外部ライブラリを使用する場合は、スレッドセーフについて注意する必要がない。
batchなどのクラスター機能を使用できる。
プロセスベースの環境を使用するときには、以下の考慮事項に留意してください。
コードがワーカーからファイルにアクセスする場合は、
'AttachedFiles'、'AdditionalPaths'などの追加のオプションを使用してデータをアクセス可能にしなければならない。
スレッドベースの環境に関するサポートの確認
スレッド ワーカーは、プロセス ワーカーで使用できる MATLAB 関数のサブセットのみをサポートしています。サポートされていない関数については、MathWorks テクニカル サポート チームまでご連絡ください。
スレッド ワーカーは、MATLAB Compiler™ を使用して作成されたスタンドアロン アプリケーション、および MATLAB Web App Server™ 上でホストされている Web アプリでサポートされています。
スレッド ワーカーでサポートされている関数の詳細については、スレッドベースの環境での MATLAB 関数の実行を参照してください。