このページの内容は最新ではありません。最新版の英語を参照するには、ここをクリックします。
attentionLayer
説明
ドット積注意層は、重み付き乗算演算を使用して入力の一部に焦点を当てます。
作成
説明
layer = attentionLayer( は、1 つ以上の名前と値の引数を使用して、numHeads,Name=Value)Scale、HasPaddingMaskInput、HasScoresOutput、AttentionMask、DropoutProbability、および Name の各プロパティも設定します。
プロパティ
例
10 個のヘッドをもつドット積注意層を作成します。
layer = attentionLayer(10)
layer =
AttentionLayer with properties:
Name: ''
NumInputs: 3
InputNames: {'query' 'key' 'value'}
NumHeads: 10
Scale: 'auto'
AttentionMask: 'none'
DropoutProbability: 0
HasPaddingMaskInput: 0
HasScoresOutput: 0
Learnable Parameters
No properties.
State Parameters
No properties.
Show all properties
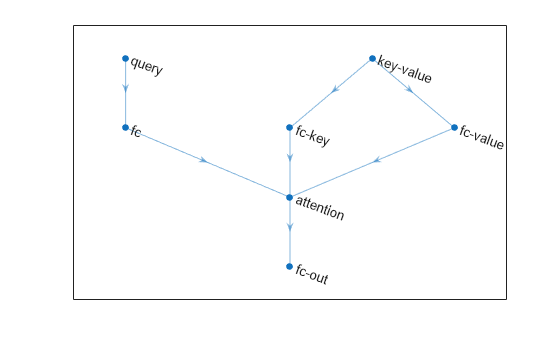
クロスアテンションによるシンプルなニューラル ネットワークを作成します。
numChannels = 256;
numHeads = 8;
net = dlnetwork;
layers = [
sequenceInputLayer(1,Name="query")
fullyConnectedLayer(numChannels)
attentionLayer(numHeads,Name="attention")
fullyConnectedLayer(numChannels,Name="fc-out")];
net = addLayers(net,layers);
layers = [
sequenceInputLayer(1, Name="key-value")
fullyConnectedLayer(numChannels,Name="fc-key")];
net = addLayers(net,layers);
net = connectLayers(net,"fc-key","attention/key");
net = addLayers(net, fullyConnectedLayer(numChannels,Name="fc-value"));
net = connectLayers(net,"key-value","fc-value");
net = connectLayers(net,"fc-value","attention/value");ネットワークをプロットで表示します。
figure plot(net)
アルゴリズム
参照
[1] Vaswani, Ashish, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. "Attention is all you need." In Advances in Neural Information Processing Systems, Vol. 30. Curran Associates, Inc., 2017. https://papers.nips.cc/paper/7181-attention-is-all-you-need.
拡張機能
バージョン履歴
R2024a で導入