Voice Activity Detector
Detect presence of speech in audio signal

Libraries:
Audio Toolbox /
Measurements
Description
The Voice Activity Detector block detects the presence of speech in an audio signal. You can also use the Voice Activity Detector block to output an estimate of the noise variance per frequency bin.
Examples
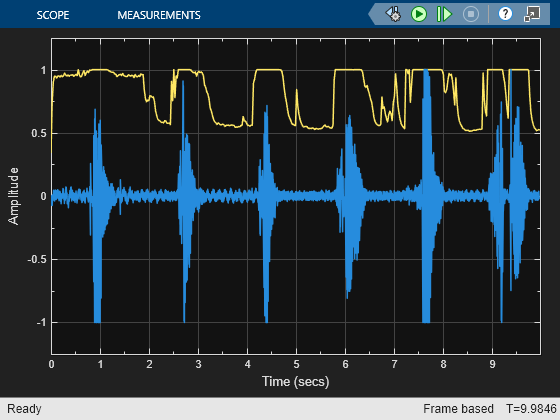
Detect Presence of Speech
This model uses the Voice Activity Detector block to visualize the probability of speech presence in an audio signal.
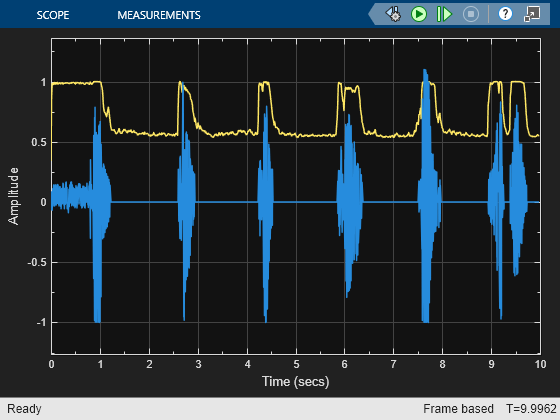
Gate Audio Signal Using VAD
This model uses if-else block signal routing to replace regions of no speech with zeros.
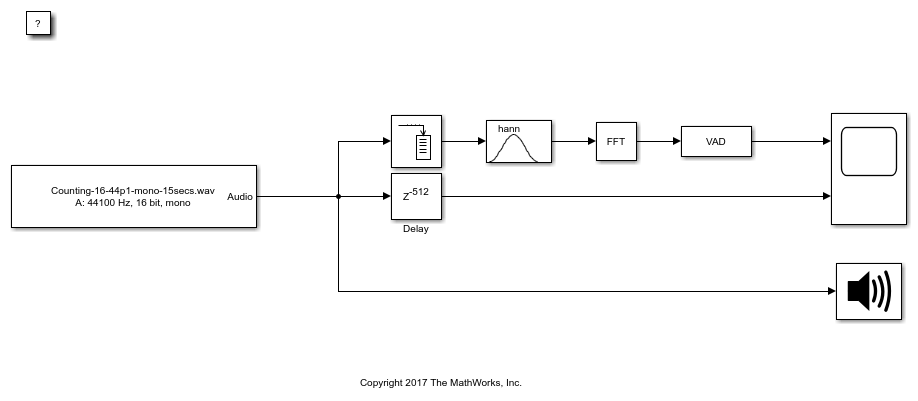
Frequency-Domain Voice Activity Detection
This model detects voice activity using a frequency-domain audio signal.

Visualize Noise Power
This model plots the noise power estimated by the Voice Activity Detector.
Ports
Input
Output
Parameters
Block Characteristics
Data Types |
|
Direct Feedthrough |
|
Multidimensional Signals |
|
Variable-Size Signals |
|
Zero-Crossing Detection |
|
Algorithms
The Voice Activity Detector implements the algorithm described in [1].

If Domain of the input is specified as
Time, the input signal is windowed and then converted to
the frequency domain according to the Window, Sidelobe
attenuation of the window (dB), and FFT length
parameters. If Domain of the input is specified as
Frequency, the input is assumed to be a windowed discrete
time Fourier transform (DTFT) of an audio signal. The signal is then converted to the
power domain. Noise variance is estimated according to [2]. The posterior and
prior SNR are estimated according to the Minimum Mean-Square Error (MMSE) formula
described in [3]. A log likelihood
ratio test with a Hidden Markov Model (HMM)-based hang-over scheme is used, according to
[1].
References
[1] Sohn, Jongseo., Nam Soo Kim, and Wonyong Sung. "A Statistical Model-Based Voice Activity Detection." Signal Processing Letters IEEE. Vol. 6, No. 1, 1999.
[2] Martin, R. "Noise Power Spectral Density Estimation Based on Optimal Smoothing and Minimum Statistics." IEEE Transactions on Speech and Audio Processing. Vol. 9, No. 5, 2001, pp. 504–512.
[3] Ephraim, Y., and D. Malah. "Speech Enhancement Using a Minimum Mean-Square Error Short-Time Spectral Amplitude Estimator." IEEE Transactions on Acoustics, Speech, and Signal Processing. Vol. 32, No. 6, 1984, pp. 1109–1121.
Extended Capabilities
Version History
Introduced in R2018a