ウェーブレットベースの特徴とサポート ベクター マシンを使用した信号分類
この例では、ウェーブレットベースの特徴抽出とサポート ベクター マシン (SVM) 分類器を使用して人間の心電図 (ECG) 信号を分類する方法を示します。生の ECG 信号を、異なるクラスを集計的に区別するのに役立つはるかに小さい特徴のセットに変換することで、信号分類の問題が単純化されます。この例を実行するには、Wavelet Toolbox™、Signal Processing Toolbox™、Statistics and Machine Learning Toolbox™ が必要です。この例で使用されているデータは、PhysioNet から公的に入手可能です。
データの説明
この例では、人の 3 つのグループ (クラス) から取得された ECG データを使用します。3 つのグループとは、心不整脈の患者、鬱血性心不全の患者、および正常洞調律の患者です。この例では、次の 3 つの PhysioNet データベースから 162 個の ECG 記録を使用します。MIT-BIH Arrhythmia Database [3][7]、MIT-BIH Normal Sinus Rhythm Database [3]、BIDMC Congestive Heart Failure Database [1][3]。合計で、不整脈の患者の記録は 96 個、鬱血性心不全の患者の記録は 30 個、正常洞調律の患者の記録は 36 個あります。目的は、不整脈 (ARR)、鬱血性心不全 (CHF)、および正常洞調律 (NSR) 間を区別できるように分類器に学習させることです。
データのダウンロード
1 番目のステップは、GitHub リポジトリからデータをダウンロードすることです。データをダウンロードするには、[Code] をクリックして [Download ZIP] を選択します。書き込み権限のあるフォルダーに、ファイル physionet_ECG_data-main.zip を保存します。この例の手順では、ファイルを一時ディレクトリ (MATLAB の tempdir) にダウンロードしているものと仮定します。tempdir とは異なるフォルダーにデータをダウンロードすることを選択した場合は、データの解凍および読み込みに関する後続の手順を変更してください。
ファイル physionet_ECG_data-main.zip には次のものが含まれています。
ECGData.zip
README.md
また、ECGData.zip には次のものが含まれています。
ECGData.mat
Modified_physionet_data.txt
License.txt
ECGData.mat は、この例で使用されるデータを保持します。.txt ファイルの Modified_physionet_data.txt は PhysioNet のコピー ポリシーで必要になり、データのソース属性、および ECG の各記録に適用される前処理手順の説明を提供します。
ファイルの読み込み
前の節のダウンロード手順に従った場合、次のコマンドを入力して 2 つのアーカイブ ファイルを解凍します。
unzip(fullfile(tempdir,'physionet_ECG_data-main.zip'),tempdir) unzip(fullfile(tempdir,'physionet_ECG_data-main','ECGData.zip'),... fullfile(tempdir,'ECGData'))
ECGData.zip ファイルを解凍したら、データを MATLAB に読み込みます。
load(fullfile(tempdir,'ECGData','ECGData.mat'))
ECGData は 2 つのフィールド (Data と Labels) を持つ構造体配列です。Data は 162 行 65,536 列の行列で、各行は 128 ヘルツでサンプリングした ECG 記録です。Labels は 162 行 1 列の診断ラベルの cell 配列で、それぞれが Data の各行に対応します。診断カテゴリは次の 3 つです。'ARR' (心不整脈)、'CHF' (鬱血性心不全)、'NSR' (正常洞調律)。
学習データとテスト データの作成
データを 2 つのセット (学習データセットとテスト データセット) に無作為に分割します。補助関数 helperRandomSplit は、無作為の分割を実行します。helperRandomSplit は、学習データと ECGData に対して希望する分割割合を受け入れます。関数 helperRandomSplit は、2 つのデータセットと、それぞれのラベル セットを出力します。trainData と testData の各行は ECG 信号です。trainLabels と testLabels の各要素には、データ行列の対応する行のクラス ラベルが含まれています。この例では、各クラスのデータの 70% を無作為に学習セットに割り当てます。残りの 30% はテスト (予測) 用に取り分けられ、テスト セットに割り当てられます。
percent_train = 70;
[trainData,testData,trainLabels,testLabels] = ...
helperRandomSplit(percent_train,ECGData);trainData セットには 113 個のレコード、testData には 49 個のレコードがあります。計画的に、学習データにはデータの 69.75% (113/162) が含まれています。ARR クラスはデータの 59.26% (96/162)、CHF クラスは 18.52% (30/162)、そして NSR クラスは 22.22% (36/162) を示すことを思い出してください。学習セットとテスト セットに含まれる各クラスの割合を調べます。各クラスの割合はデータセットに含まれるクラスの全体的な割合と一致します。
Ctrain = countcats(categorical(trainLabels))./numel(trainLabels).*100
Ctrain = 3×1
59.2920
18.5841
22.1239
Ctest = countcats(categorical(testLabels))./numel(testLabels).*100
Ctest = 3×1
59.1837
18.3673
22.4490
サンプルのプロット
ECGData から無作為に選択した 4 個のレコードのうちの最初の数千個のサンプルをプロットします。補助関数 helperPlotRandomRecords がこれを実行します。helperPlotRandomRecords は ECGData とランダムシードを入力として受け入れます。各クラスの少なくとも 1 つのレコードがプロットされるように、初期シードは 14 で設定されます。各クラスに関連付けられたさまざまな ECG 波形を把握するために、必要に応じて何度でも、ECGData を唯一の入力引数として指定して helperPlotRandomRecords を実行することができます。この補助関数のソース コードは、この例の最後にある「サポート関数」の節で見つけることができます。
helperPlotRandomRecords(ECGData,14)

特徴抽出
各信号の信号分類で使用される特徴を抽出します。この例では、各信号の 8 個のブロックで約 1 分間抽出した次の特徴を使用します (8,192 サンプル)。
次数 4 の自己回帰モデル (AR) 係数 [8]。
レベル 4 の最大重複離散ウェーブレット パケット変換 (MODPWT) のシャノン エントロピー (SE) 値 [5]。
スケーリング指数の 2 番目のキュムラントおよびヘルダー指数の範囲、または特異点スペクトルのマルチフラクタル ウェーブレット リーダー推定 [4]。
さらに、マルチスケール ウェーブレット分散推定がデータ長全体の各信号に対して抽出されます [6]。ウェーブレット分散の不偏推定が使用されます。そのためには、境界条件の影響を受けないウェーブレット係数を 1 つ以上もつレベルのみが分散推定で使用される必要があります。2^16 (65,536) の信号長および 'db2' ウェーブレットの場合、14 レベルになります。
これらの特徴は、ECG 波形の分類における効果を実証している公開済みの研究に基づいて選択されました。これは、特徴を網羅したリストまたは最適化したリストにすることを目的としていません。
各ウィンドウの AR 係数はバーグ メソッド arburg を使用して推定されます。[8] では、著者はモデル次数の選択メソッドを使用して、同様の分類問題の ECG 波形に対して最適な近似を提供したのは AR(4) モデルであると判断しました。[5] では、情報理論的尺度のシャノン エントロピーがウェーブレット パケット ツリーの終端ノードで計算され、ランダム フォレスト分類器で使用されました。ここで、非間引きウェーブレット パケット変換の modwpt をレベル 4 まで下げて使用します。
[5] に続く非間引きウェーブレット パケット変換のシャノン エントロピーの定義は によって指定されます。ここで、 は、j 番目のノードにある対応する係数の数です。また、 は、j 番目の終端ノードにあるウェーブレット パケット係数の正規化された二乗です。
ウェーブレット メソッドによって推定される 2 つのフラクタル尺度は特徴として使用されます。[4] に続いて、dwtleader から取得された特異点スペクトルの幅を ECG 信号のマルチフラクタル特性の尺度として使用します。また、スケーリング指数の 2 番目のキュムラントも使用します。スケーリング指数は、異なる分解能での信号でのべき乗則の動作を記述するスケールベースの指数です。2 番目のキュムラントは、線形性からのスケーリング指数の逸脱を大まかに表します。
信号全体のウェーブレット分散は modwtvar を使用して取得されます。ウェーブレット分散は、スケールごとの信号の変動性、またはオクターブバンドの周波数範囲の信号の等価な変動性を測定します。
合計で 190 個の特徴があります。つまり、32 個の AR 特徴 (ブロックごとに 4 個の係数)、128 個のシャノン エントロピー値 (ブロックごとに 16 個の値)、16 個のフラクタル推定 (ブロックごとに 2 個)、14 個のウェーブレット分散推定があります。
関数 helperExtractFeatures はこれらの特徴を計算し、各信号の特徴ベクトルに連結します。この補助関数のソース コードは、この例の最後にある「サポート関数」の節で見つけることができます。
timeWindow = 8192;
ARorder = 4;
MODWPTlevel = 4;
[trainFeatures,testFeatures,featureindices] = ...
helperExtractFeatures(trainData,testData,timeWindow,ARorder,MODWPTlevel);trainFeatures および testFeatures は、それぞれ 113 行 190 列と 49 行 190 列の行列です。これらの行列の各行は、それぞれ trainData と testData の対応する ECG データの特徴ベクトルです。特徴ベクトルの作成時に、データは 65,536 個のサンプルから 190 個の要素ベクトルに削減されます。これは大幅なデータ削減ですが、目的は単にデータを削減することではありません。目的は、分類器が信号を正確に分離できるように、クラス間の差を捉えるはるかに小さい特徴セットにデータを削減することです。trainFeatures と testFeatures の両方を構成する特徴のインデックスは、構造体配列 featureindices に含まれています。このインデックスを使用して、グループ別の特徴を調べることができます。例として、最初の時間枠の特異点スペクトルにあるヘルダー指数の範囲を調べます。データセット全体のデータをプロットします。
allFeatures = [trainFeatures;testFeatures]; allLabels = [trainLabels;testLabels]; figure boxplot(allFeatures(:,featureindices.HRfeatures(1)),allLabels,'notch','on') ylabel('Holder Exponent Range') title('Range of Singularity Spectrum by Group (First Time Window)') grid on
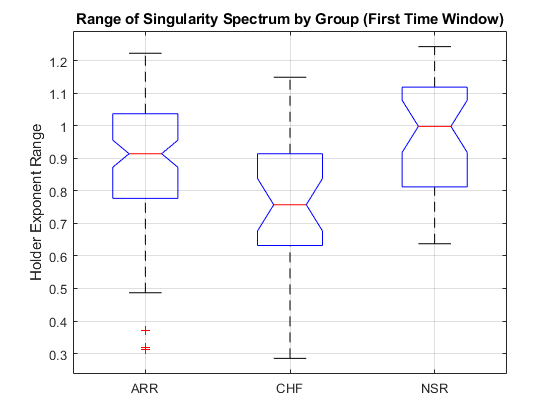
この特徴に対して 1 因子分散分析を実行し、箱ひげ図に表示されるもの、すなわち ARR グループと NSR グループの範囲が CHF グループより大幅に大きいことを確認できます。
[p,anovatab,st] = anova1(allFeatures(:,featureindices.HRfeatures(1)),...
allLabels);
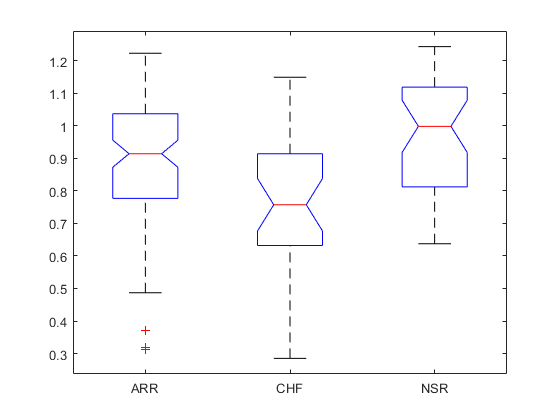
c = multcompare(st,'display','off')
c = 3×6
1.0000 2.0000 0.0176 0.1144 0.2112 0.0155
1.0000 3.0000 -0.1591 -0.0687 0.0218 0.1764
2.0000 3.0000 -0.2975 -0.1831 -0.0687 0.0005
追加の例として、3 つのグループの 2 番目に低い周波数 (2 番目に大きいスケール) のウェーブレット サブバンドにおける分散の差異について考えます。
boxplot(allFeatures(:,featureindices.WVARfeatures(end-1)),allLabels,'notch','on') ylabel('Wavelet Variance') title('Wavelet Variance by Group') grid on
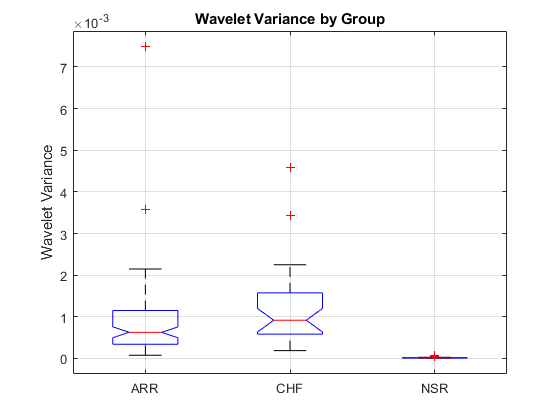
この特徴に対して分散分析を実行すると、このウェーブレット サブバンドの中で NSR グループの分散が ARR グループおよび CHF グループよりも大幅に低いことがわかります。これらの例は、個々の特徴がどのようにクラスを分離する役割を担っているかを示すことだけを目的にしています。1 つの特徴だけでは十分でありませんが、目的は分類器が 3 つすべてのクラスを分離できるのに十分な、豊富な特徴セットを取得することです。
信号分類
データが各信号の特徴ベクトルに削減されたので、次のステップは ECG 信号を分類するためにこれらの特徴ベクトルを使用することです。分類学習器アプリを使用すると、多数の分類器を迅速に評価できます。この例では、二次カーネルを持つマルチクラス SVM を使用します。2 つの解析が実行されます。まずはデータセット全体 (学習セットとテスト セット) を使用し、5 分割の交差検証を使用して誤分類率と混同行列を推定します。
features = [trainFeatures; testFeatures]; rng(1) template = templateSVM(... 'KernelFunction','polynomial',... 'PolynomialOrder',2,... 'KernelScale','auto',... 'BoxConstraint',1,... 'Standardize',true); model = fitcecoc(... features,... [trainLabels;testLabels],... 'Learners',template,... 'Coding','onevsone',... 'ClassNames',{'ARR','CHF','NSR'}); kfoldmodel = crossval(model,'KFold',5); classLabels = kfoldPredict(kfoldmodel); loss = kfoldLoss(kfoldmodel)*100
loss = 8.0247
[confmatCV,grouporder] = confusionmat([trainLabels;testLabels],classLabels);
5 分割分類誤差は 8.02% です (91.98% は正しい)。混同行列 confmatCV は、どのレコードが誤分類されたかを示します。grouporder はグループの順序を指定します。ARR グループのうちの 2 個が CHF として誤分類されました。CHF グループのうちの 8 個が ARR、1 個が NSR として誤分類され、NSR グループのうちの 2 個が ARR として誤分類されました。
適合率、再現率および F1 スコア
分類タスクにおいて、クラスの適合率とは正しい正の結果の数を正の結果の数で除算したものです。言い換えれば、分類器が特定のラベルを割り当てるすべてのレコードのうち、実際にクラスに属している割合のことです。再現率は、正しいラベルの数を特定のクラスのラベル数で除算したものと定義されます。具体的には、クラスに属しているすべてのレコードのうち、分類器によってそのクラスのラベルが付けられた割合です。機械学習システムの精度を判断する場合に、理想的には適合率と再現率の両方で良い結果を得る必要があります。たとえば、1 つ 1 つのレコードに ARR のラベルを付けた分類器があると仮定します。ARR クラスの再現率は 1 (100%) になります。ARR クラスに属しているすべてのレコードが ARR とラベル付けされます。しかし、適合率は低くなります。分類器によってすべてのレコードが ARR とラベル付けされたため、この場合は 66 個の偽陽性があり、適合率は 96/162 (つまり 0.5926) になります。F1 スコアは適合率および再現率の調和平均であり、再現率と適合率の両方の観点から分類器のパフォーマンスを要約する 1 つのメトリクスを提供します。次の補助関数は 3 つのクラスに関する適合率、再現率、F1 スコアを計算します。「サポート関数」の節にあるコードを調べることで、helperPrecisionRecall が混同行列に基づいて適合率、再現率、および F1 スコアを計算する方法を確認できます。
CVTable = helperPrecisionRecall(confmatCV);
次のコマンドを使用して、helperPrecisionRecall によって返されるテーブルを表示できます。
disp(CVTable)
Precision Recall F1_Score
_________ ______ ________
ARR 90.385 97.917 94
CHF 91.304 70 79.245
NSR 97.143 94.444 95.775
ARR クラスと NSR クラスでは適合率と再現率の両方が良い結果ですが、CHF クラスでは再現率が大幅に低下します。
次の解析では、マルチクラスの 2 次 SVM を学習データのみ (70%) に当てはめてから、そのモデルを使用してテスト用に取り分けられた 30% のデータに対して予測を行います。テスト セットには 49 個のデータ レコードがあります。
model = fitcecoc(... trainFeatures,... trainLabels,... 'Learners',template,... 'Coding','onevsone',... 'ClassNames',{'ARR','CHF','NSR'}); predLabels = predict(model,testFeatures);
次を使用して、正しい予測の数を判断し、混同行列を取得します。
correctPredictions = strcmp(predLabels,testLabels); testAccuracy = sum(correctPredictions)/length(testLabels)*100
testAccuracy = 97.9592
[confmatTest,grouporder] = confusionmat(testLabels,predLabels);
テスト データセットに関する分類精度は約 98% であり、混同行列は 1 つの CHF レコードが NSR と誤分類されたことを示しています。
交差検証解析で行ったことと同様に、テスト セットに関する適合率、再現率、および F1 スコアを取得します。
testTable = helperPrecisionRecall(confmatTest); disp(testTable)
Precision Recall F1_Score
_________ ______ ________
ARR 100 100 100
CHF 100 88.889 94.118
NSR 91.667 100 95.652
生データの分類とクラスタリング
前回の解析で、当然の疑問が 2 つ生じます。良好な分類結果を得るには特徴抽出が必要ですか。分類器は必要ですか、または、分類器を使用せずにこれらの特徴によってグループを分離できますか。1 番目の疑問に対処するには、生の時系列データの交差検証結果を繰り返します。SVM を 162 行 65,536 列の行列に適用しているため、次のコードは大量の計算が必要なステップであることに注意してください。このステップをお客様自身で実行することを希望されない場合は、次の段落で結果が説明されています。
rawData = [trainData;testData]; Labels = [trainLabels;testLabels]; rng(1) template = templateSVM(... 'KernelFunction','polynomial', ... 'PolynomialOrder',2, ... 'KernelScale','auto', ... 'BoxConstraint',1, ... 'Standardize',true); model = fitcecoc(... rawData,... [trainLabels;testLabels],... 'Learners',template,... 'Coding','onevsone',... 'ClassNames',{'ARR','CHF','NSR'}); kfoldmodel = crossval(model,'KFold',5); classLabels = kfoldPredict(kfoldmodel); loss = kfoldLoss(kfoldmodel)*100
loss = 33.3333
[confmatCVraw,grouporder] = confusionmat([trainLabels;testLabels],classLabels); rawTable = helperPrecisionRecall(confmatCVraw); disp(rawTable)
Precision Recall F1_Score
_________ ______ ________
ARR 64 100 78.049
CHF 100 13.333 23.529
NSR 100 22.222 36.364
生の時系列データの誤分類率は 33.3% です。適合率、再現率、F1 スコアの解析を繰り返し行うことで、CHF グループ (23.52) と NSR グループ (36.36) の両方の F1 スコアが非常に悪いことが明らかになりました。各信号の振幅離散フーリエ変換 (DFT) 係数を取得して、周波数領域で解析を実行します。データは実数値であるため、フーリエ振幅が偶関数であるという事実を利用することで、DFT を使用して一定のデータ削減を達成できます。
rawDataDFT = abs(fft(rawData,[],2)); rawDataDFT = rawDataDFT(:,1:2^16/2+1); rng(1) template = templateSVM(... 'KernelFunction','polynomial',... 'PolynomialOrder',2,... 'KernelScale','auto',... 'BoxConstraint',1,... 'Standardize',true); model = fitcecoc(... rawDataDFT,... [trainLabels;testLabels],... 'Learners',template,... 'Coding','onevsone',... 'ClassNames',{'ARR','CHF','NSR'}); kfoldmodel = crossval(model,'KFold',5); classLabels = kfoldPredict(kfoldmodel); loss = kfoldLoss(kfoldmodel)*100
loss = 19.1358
[confmatCVDFT,grouporder] = confusionmat([trainLabels;testLabels],classLabels); dftTable = helperPrecisionRecall(confmatCVDFT); disp(dftTable)
Precision Recall F1_Score
_________ ______ ________
ARR 76.423 97.917 85.845
CHF 100 26.667 42.105
NSR 93.548 80.556 86.567
DFT 振幅を使用すると誤分類率が 19.13% まで下がりますが、依然として 190 個の特徴を使用して取得される誤り率の 2 倍以上です。これらの解析は、特徴を慎重に選択することで、分類器が良い結果を得られたことを実証しています。
分類器の役割に関する質問に回答するには、特徴ベクトルのみを使用してデータのクラスタリングを試みてください。k-means クラスタリングとギャップ統計を使用して、最適なクラスター数とクラスター割り当ての両方を判断します。データに対して 1 ~ 6 個のクラスターが存在する可能性を考慮してください。
rng default eva = evalclusters(features,'kmeans','gap','KList',[1:6]); eva
eva =
GapEvaluation with properties:
NumObservations: 162
InspectedK: [1 2 3 4 5 6]
CriterionValues: [1.2777 1.3539 1.3644 1.3570 1.3591 1.3752]
OptimalK: 3
ギャップ統計から、最適なクラスター数が 3 であることがわかります。ただし、3 つのクラスターそれぞれのレコード数を確認すると、特徴ベクトルに基づく k-means クラスタリングによって実行された 3 つの診断カテゴリを分離するジョブの結果がよくなかったことがわかります。
countcats(categorical(eva.OptimalY))
ans = 3×1
61
74
27
ARR クラスに 96 人、CHF クラスに 30 人、NSR クラスに 36 人いることを思い出してください。
まとめ
この例では、信号処理を使用して ECG 信号からウェーブレット特徴を抽出し、これらの特徴を使用して ECG 信号を 3 つのクラスに分類しました。特徴を抽出することでデータ量が大幅に削減されただけでなく、交差検証結果やテスト セットに対する SVM 分類器のパフォーマンスが示すように、ARR クラス、CHF クラス、および NSR クラスの間の差異を得ることができました。この例ではさらに、SVM 分類器を生データに適用すると、分類器を使用せずに特徴ベクトルのクラスタリングを行った場合のように、性能が低下することを実証しました。分類器も特徴単体での使用もクラスを分離するのに十分ではありませんでした。しかし、分類器を使用する前に、特徴抽出をデータ削減手順として使用すると、3 つのクラスは適切に分離されました。
参考文献
Baim DS, Colucci WS, Monrad ES, Smith HS, Wright RF, Lanoue A, Gauthier DF, Ransil BJ, Grossman W, Braunwald E. Survival of patients with severe congestive heart failure treated with oral milrinone. J American College of Cardiology 1986 Mar; 7(3):661-670.
Engin, M., 2004. ECG beat classification using neuro-fuzzy network. Pattern Recognition Letters, 25(15), pp.1715-1722.
Goldberger AL, Amaral LAN, Glass L, Hausdorff JM, Ivanov PCh, Mark RG, Mietus JE, Moody GB, Peng C-K, Stanley HE. PhysioBank, PhysioToolkit,and PhysioNet: Components of a New Research Resource for Complex Physiologic Signals. Circulation. Vol. 101, No. 23, 13 June 2000, pp. e215-e220.
http://circ.ahajournals.org/content/101/23/e215.fullLeonarduzzi, R.F., Schlotthauer, G., and Torres. M.E. 2010. Wavelet leader based multifractal analysis of heart rate variability during myocardial ischaemia. Engineering in Medicine and Biology Society (EMBC), 2010 Annual International Conference of the IEEE.
Li, T. and Zhou, M., 2016. ECG classification using wavelet packet entropy and random forests. Entropy, 18(8), p.285.
Maharaj, E.A. and Alonso, A.M. 2014. Discriminant analysis of multivariate time series: Application to diagnosis based on ECG signals. Computational Statistics and Data Analysis, 70, pp. 67-87.
Moody GB, Mark RG. The impact of the MIT-BIH Arrhythmia Database. IEEE Eng in Med and Biol 20(3):45-50 (May-June 2001). (PMID: 11446209)
Zhao, Q. and Zhang, L., 2005. ECG feature extraction and classification using wavelet transform and support vector machines. IEEE International Conference on Neural Networks and Brain,2, pp. 1089-1092.
サポート関数
helperPlotRandomRecords - ECGData から無作為に選択した 4 個の ECG 信号をプロットします。
function helperPlotRandomRecords(ECGData,randomSeed) % This function is only intended to support the XpwWaveletMLExample. It may % change or be removed in a future release. if nargin==2 rng(randomSeed) end M = size(ECGData.Data,1); idxsel = randperm(M,4); for numplot = 1:4 subplot(2,2,numplot) plot(ECGData.Data(idxsel(numplot),1:3000)) ylabel('Volts') if numplot > 2 xlabel('Samples') end title(ECGData.Labels{idxsel(numplot)}) end end
helperExtractFeatures 指定されたサイズのデータのブロックに関するウェーブレット特性と AR 係数を抽出します。特徴は特徴ベクトルに連結されます。
function [trainFeatures, testFeatures,featureindices] = helperExtractFeatures(trainData,testData,T,AR_order,level) % This function is only in support of XpwWaveletMLExample. It may change or % be removed in a future release. trainFeatures = []; testFeatures = []; for idx =1:size(trainData,1) x = trainData(idx,:); x = detrend(x,0); arcoefs = blockAR(x,AR_order,T); se = shannonEntropy(x,T,level); [cp,rh] = leaders(x,T); wvar = modwtvar(modwt(x,'db2'),'db2'); trainFeatures = [trainFeatures; arcoefs se cp rh wvar']; %#ok<AGROW> end for idx =1:size(testData,1) x1 = testData(idx,:); x1 = detrend(x1,0); arcoefs = blockAR(x1,AR_order,T); se = shannonEntropy(x1,T,level); [cp,rh] = leaders(x1,T); wvar = modwtvar(modwt(x1,'db2'),'db2'); testFeatures = [testFeatures;arcoefs se cp rh wvar']; %#ok<AGROW> end featureindices = struct(); % 4*8 featureindices.ARfeatures = 1:32; startidx = 33; endidx = 33+(16*8)-1; featureindices.SEfeatures = startidx:endidx; startidx = endidx+1; endidx = startidx+7; featureindices.CP2features = startidx:endidx; startidx = endidx+1; endidx = startidx+7; featureindices.HRfeatures = startidx:endidx; startidx = endidx+1; endidx = startidx+13; featureindices.WVARfeatures = startidx:endidx; end function se = shannonEntropy(x,numbuffer,level) numwindows = numel(x)/numbuffer; y = buffer(x,numbuffer); se = zeros(2^level,size(y,2)); for kk = 1:size(y,2) wpt = modwpt(y(:,kk),level); % Sum across time E = sum(wpt.^2,2); Pij = wpt.^2./E; % The following is eps(1) se(:,kk) = -sum(Pij.*log(Pij+eps),2); end se = reshape(se,2^level*numwindows,1); se = se'; end function arcfs = blockAR(x,order,numbuffer) numwindows = numel(x)/numbuffer; y = buffer(x,numbuffer); arcfs = zeros(order,size(y,2)); for kk = 1:size(y,2) artmp = arburg(y(:,kk),order); arcfs(:,kk) = artmp(2:end); end arcfs = reshape(arcfs,order*numwindows,1); arcfs = arcfs'; end function [cp,rh] = leaders(x,numbuffer) y = buffer(x,numbuffer); cp = zeros(1,size(y,2)); rh = zeros(1,size(y,2)); for kk = 1:size(y,2) [~,h,cptmp] = dwtleader(y(:,kk)); cp(kk) = cptmp(2); rh(kk) = range(h); end end
helperPrecisionRecall 混同行列に基づいて適合率、再現率、および F1 スコアを返します。結果を MATLAB テーブルとして出力します。
function PRTable = helperPrecisionRecall(confmat) % This function is only in support of XpwWaveletMLExample. It may change or % be removed in a future release. precisionARR = confmat(1,1)/sum(confmat(:,1))*100; precisionCHF = confmat(2,2)/sum(confmat(:,2))*100 ; precisionNSR = confmat(3,3)/sum(confmat(:,3))*100 ; recallARR = confmat(1,1)/sum(confmat(1,:))*100; recallCHF = confmat(2,2)/sum(confmat(2,:))*100; recallNSR = confmat(3,3)/sum(confmat(3,:))*100; F1ARR = 2*precisionARR*recallARR/(precisionARR+recallARR); F1CHF = 2*precisionCHF*recallCHF/(precisionCHF+recallCHF); F1NSR = 2*precisionNSR*recallNSR/(precisionNSR+recallNSR); % Construct a MATLAB Table to display the results. PRTable = array2table([precisionARR recallARR F1ARR;... precisionCHF recallCHF F1CHF; precisionNSR recallNSR... F1NSR],'VariableNames',{'Precision','Recall','F1_Score'},'RowNames',... {'ARR','CHF','NSR'}); end
参考
関数
アプリ
- 分類学習器アプリ (Statistics and Machine Learning Toolbox)