このページの内容は最新ではありません。最新版の英語を参照するには、ここをクリックします。
テキストの検出と認識
イメージ内のテキストの検出と認識は、コンピューター ビジョン アプリケーションで実行される一般的なタスクです。たとえば、走行中の車両から路上シーンのビデオをキャプチャし、キャプチャしたシーンの標識を認識して、ドライバーに標識について知らせることができます。
検出と認識を 2 段階のプロセスに組み合わせることができます。最初のステップでテキストを含む領域を検出し、次に 2 番目のステップで領域内のテキストを認識します。
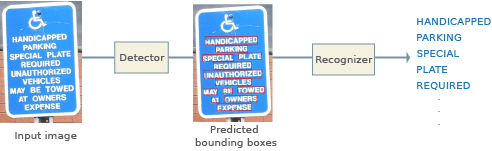
テキスト検出アルゴリズムは、局所的なイメージ特徴、機械学習または深層学習を使用して、イメージ内のテキストを特定またはセグメント化します。Computer Vision Toolbox™ の例では、ブロブ解析、maximally stable extremal regions (MSER) 特徴検出器、および character region awareness for text detection (CRAFT) 深層学習モデルを使用してテキストを検出する方法を示しています。
テキストを検出すると、機械学習または深層学習ベースのテキスト認識モデルがテキスト領域を処理して、予測されたテキストを返します。関数 ocr は、事前学習済みの言語モデルを使用して、複数の言語のテキストを認識します。関数 trainOCR を使用してカスタム言語モデルに学習させることもできます。詳細については、Getting Started with OCRを参照してください。
アプリ
| イメージ ラベラー | コンピューター ビジョン アプリケーションに使用するラベル イメージ |
関数
トピック
開始
- Getting Started with OCR
Detect and recognize text in multiple languages, train OCR models to recognize custom text. - Train Custom OCR Model
Train an optical character recognition (OCR) model to recognize custom text. - OCR Language Data Files のインストール
光学式文字認識 (OCR) 言語のファイルをサポートしています。 - 局所特徴の検出と抽出
局所特徴の検出と抽出の利点と用途の学習。 - 特徴点のタイプ
いくつかの種類の特徴の点オブジェクトを返したり受け入れたりする関数の選択。
注目の例

光学式文字認識 (OCR) を使用したテキストの認識
光学式文字認識を使用してイメージ内のテキストを認識する。

Recognize Seven-Segment Digits Using OCR
Use OCR to recognize seven-segmented digits in text detected by CRAFT and region properties.

イメージ内のテキストのセグメント化と読み取り
MSER と OCR を使用したイメージ内のテキストの自動検出と自動認識。

Automatically Detect and Recognize Text Using Pretrained CRAFT Network and OCR
Perform text recognition by using a deep learning based text detector and OCR.

Automate Ground Truth Labeling for OCR
Automate the labeling of text for OCR training and evaluation.

Train an OCR Model to Recognize Seven-Segment Digits
Train an OCR model that can recognize seven-segment numerals.

HOG 特徴を使用した数字の分類
この例では、HOG 特徴およびマルチクラス SVM 分類器を使用して数字を分類する方法を説明します。