HOG 特徴を使用した数字の分類
この例では、HOG 特徴およびマルチクラス SVM 分類器を使用して数字を分類する方法を説明します。
オブジェクトの分類は、監視、自動車安全性、イメージの検索など、多くのコンピューター ビジョンの応用において重要なタスクです。たとえば、自動車安全性アプリケーションでは、近くのオブジェクトを歩行者や車両として分類しなければならないことがあります。分類するオブジェクトのタイプにかかわらず、オブジェクト分類器を作成する基本的な手順は次のようになります。
対象オブジェクトのイメージを含むラベル付きデータセットを取得する。
データセットを学習セットとテスト セットに分割する。
学習セットから抽出された特徴を使用して分類器に学習を行わせる。
テスト セットから抽出された特徴を使用して分類器をテストする。
説明のために、この例では HOG (勾配方向ヒストグラム) 特徴 [1] とマルチクラスの SVM (サポート ベクター マシン) 分類器を使用して数字を分類する方法を示します。このタイプの分類は、多くの光学式文字認識 (OCR) アプリケーションでよく使用されます。
この例では、Statistics and Machine Learning Toolbox™ の関数 fitcecoc および Computer Vision Toolbox™ の関数 extractHOGFeatures を使用します。
数字のデータセット
学習には数字の合成イメージが使用されます。各学習用イメージでは、1 つの数字が他の数字に囲まれています。これは、複数の数字が通常目にされる状態を模倣したものです。合成イメージを使用すると、さまざまな学習サンプルを作成でき、手作業で集める必要がなくなるので便利です。テストでは手書きの数字のスキャン画像を使用して、学習データとは異なるデータに対する分類器のパフォーマンスを検証します。これは最も典型的なデータセットではありませんが、分類器の学習とテストを行い、この方法の実行可能性を示すうえで十分なデータが含まれています。
% Load training and test data using |imageDatastore|. syntheticDir = fullfile(toolboxdir("vision"),"visiondata","digits","synthetic"); handwrittenDir = fullfile(toolboxdir("vision"),"visiondata","digits","handwritten"); % |imageDatastore| recursively scans the directory tree containing the % images. Folder names are automatically used as labels for each image. trainingSet = imageDatastore(syntheticDir,IncludeSubfolders=true,LabelSource="foldernames"); testSet = imageDatastore(handwrittenDir,IncludeSubfolders=true,LabelSource="foldernames");
countEachLabel を使用して、それぞれのラベルに関連付けられているイメージの数を集計します。この例の学習セットは、10 個の数字それぞれにつき 101 個のイメージで構成されています。テスト セットは数字ごとに 12 個のイメージで構成されています。
countEachLabel(trainingSet)
ans=10×2 table
0 101
1 101
2 101
3 101
4 101
5 101
6 101
7 101
8 101
9 101
countEachLabel(testSet)
ans=10×2 table
0 12
1 12
2 12
3 12
4 12
5 12
6 12
7 12
8 12
9 12
一部の学習イメージおよびテスト イメージを表示します。
figure;
subplot(2,3,1);
imshow(trainingSet.Files{102});
subplot(2,3,2);
imshow(trainingSet.Files{304});
subplot(2,3,3);
imshow(trainingSet.Files{809});
subplot(2,3,4);
imshow(testSet.Files{13});
subplot(2,3,5);
imshow(testSet.Files{37});
subplot(2,3,6);
imshow(testSet.Files{97});
分類器の学習とテストを行う前に、前処理手順を適用してイメージ サンプルの収集時に取り込まれたノイズ アーティファクトを削除します。これにより、分類器の学習用により適した特徴ベクトルが得られます。
% Show pre-processing results
exTestImage = readimage(testSet,37);
processedImage = imbinarize(im2gray(exTestImage));
figure;
subplot(1,2,1)
imshow(exTestImage)
subplot(1,2,2)
imshow(processedImage)
HOG 特徴の使用
分類器の学習に使用するデータは、学習イメージから抽出した HOG 特徴ベクトルです。したがって、HOG 特徴ベクトルではオブジェクトに関する適量の情報を必ずエンコードすることが重要です。関数 extractHOGFeatures は visualization 出力を返しますが、これは、「適量の情報」の意味を大まかに把握する助けとなります。HOG のセル サイズ パラメーターを変化させて結果を可視化すると、特徴ベクトルにエンコードされる形状情報の量に対する、セル サイズ パラメーターの影響を見ることができます。
img = readimage(trainingSet, 206); % Extract HOG features and HOG visualization [hog_2x2, vis2x2] = extractHOGFeatures(img,CellSize=[2 2]); [hog_4x4, vis4x4] = extractHOGFeatures(img,CellSize=[4 4]); [hog_8x8, vis8x8] = extractHOGFeatures(img,CellSize=[8 8]); % Show the original image figure; subplot(2,3,1:3); imshow(img); % Visualize the HOG features subplot(2,3,4); plot(vis2x2); title(["CellSize = [2 2]"; "Length = " + length(hog_2x2)]); subplot(2,3,5); plot(vis4x4); title(["CellSize = [4 4]"; "Length = " + length(hog_4x4)]); subplot(2,3,6); plot(vis8x8); title(["CellSize = [8 8]"; "Length = " + length(hog_8x8)]);

可視化から、[8 8] のセル サイズでは形状情報があまりエンコードされず、[2 2] のセル サイズでは大量の形状情報がエンコードされるものの HOG 特徴ベクトルの次元が大幅に増えることがわかります。適切な妥協点は 4 行 4 列のセル サイズとなります。このサイズ設定では、数字の形状を視覚的に特定する十分な空間情報をエンコードできると同時に、HOG 特徴ベクトルの次元数を抑えて学習速度を上げることができます。実際には、HOG パラメーターを変化させながら分類器の学習とテストを繰り返して、最適なパラメーター設定を見つけます。
cellSize = [4 4]; hogFeatureSize = length(hog_4x4);
数字分類器の学習
数字の分類はマルチクラス分類の問題であり、あるイメージを、10 個のとりうる数字のクラスのうち 1 つに分類しなければなりません。この例では Statistics and Machine Learning Toolbox™ の関数 fitcecoc を使用して、バイナリ SVM を用いたマルチクラス分類器を作成します。
はじめに、学習セットから HOG 特徴を抽出します。これらの特徴は分類器の学習に使用されます。
% Loop over the trainingSet and extract HOG features from each image. A % similar procedure will be used to extract features from the testSet. numImages = numel(trainingSet.Files); trainingFeatures = zeros(numImages,hogFeatureSize,"single"); for i = 1:numImages img = readimage(trainingSet,i); img = im2gray(img); % Apply pre-processing steps img = imbinarize(img); trainingFeatures(i, :) = extractHOGFeatures(img,CellSize=cellSize); end % Get labels for each image. trainingLabels = trainingSet.Labels;
次に、抽出した特徴を使用して分類器に学習させます。
% fitcecoc uses SVM learners and a 'One-vs-One' encoding scheme.
classifier = fitcecoc(trainingFeatures, trainingLabels);数字分類器の評価
テスト セットからのイメージを使用して数字分類器を評価し、分類器の精度を定量化する混同行列を生成します。
学習手順と同じように、まずテスト イメージから HOG 特徴を抽出します。これらの特徴は、学習済みの分類器を使用して予測を行うのに使用されます。
% Extract HOG features from the test set. The procedure is similar to what % was shown earlier and is encapsulated as a helper function for brevity. [testFeatures, testLabels] = helperExtractHOGFeaturesFromImageSet(testSet, hogFeatureSize, cellSize); % Make class predictions using the test features. predictedLabels = predict(classifier, testFeatures); % Display the confusion matrix. figure confusionchart(testLabels,predictedLabels,Normalization="row-normalized")
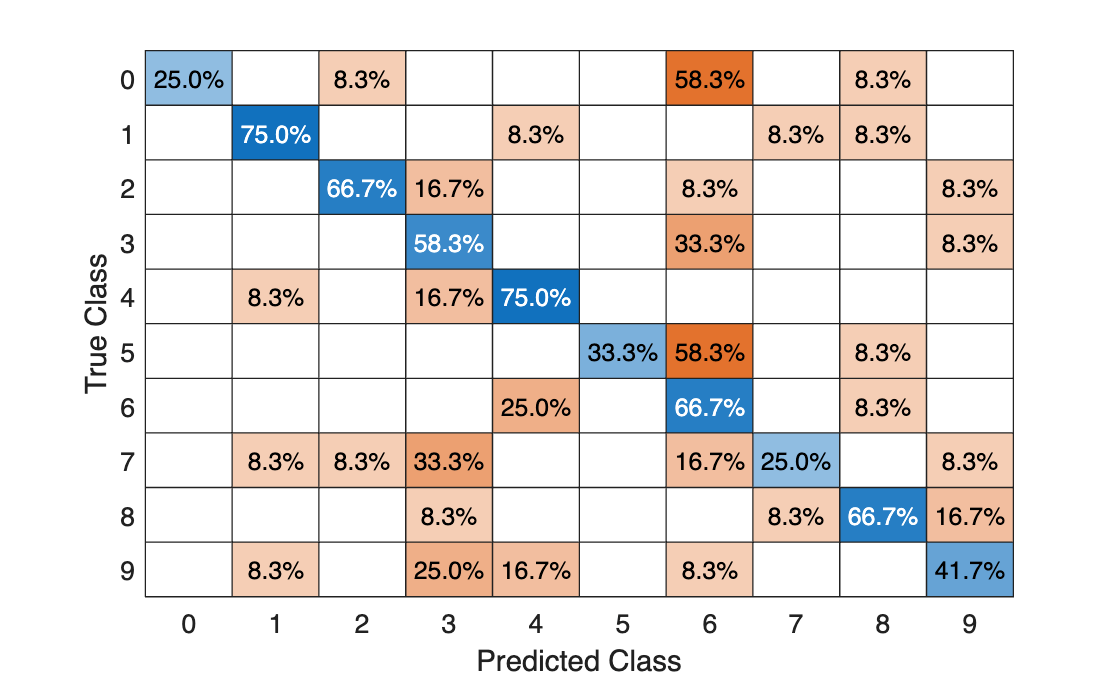
この表は混同行列をパーセンテージ形式で示しています。行列の各列は予測されたラベルを表し、各行は既知のラベルを表します。このテスト セットでは数字 0 が誤って 6 として分類されることが多く、これは形状の類似が原因であると推測されます。9 と 3 の場合にも同様のエラーが見られます。MNIST [2] や SVHN [3] のように何千という手書きの文字を含む、より典型的なデータセットを使って学習させれば、この合成データセットを使って作成されたものより優れた分類器が作成される可能性は高くなります。
まとめ
この例では、Computer Vision Toolbox の関数 extractHOGfeatures および Statistics and Machine Learning Toolbox™ の関数 fitcecoc を使用してマルチクラスのオブジェクト分類器を作成する基本的な手順について説明しました。ここでは HOG 特徴と ECOC 分類器を使用しましたが、他の特徴や機械学習アルゴリズムを同じように使用することも可能です。たとえば、分類器の学習に異なる特徴タイプを使って調べたり、Statistics and Machine Learning Toolbox™ で利用できる k 近傍法のような他の機械学習アルゴリズムを使用した場合の効果を確認することができます。
サポート関数
function [features, setLabels] = helperExtractHOGFeaturesFromImageSet(imds, hogFeatureSize, cellSize) % Extract HOG features from an imageDatastore. setLabels = imds.Labels; numImages = numel(imds.Files); features = zeros(numImages,hogFeatureSize,"single"); % Process each image and extract features for j = 1:numImages img = readimage(imds,j); img = im2gray(img); % Apply pre-processing steps img = imbinarize(img); features(j, :) = extractHOGFeatures(img,"CellSize",cellSize); end end
参照
[1] N. Dalal and B. Triggs, "Histograms of Oriented Gradients for Human Detection", Proc. IEEE Conf. Computer Vision and Pattern Recognition, vol. 1, pp. 886-893, 2005.
[2] LeCun, Y., Bottou, L., Bengio, Y., and Haffner, P. (1998). Gradient-based learning applied to document recognition. Proceedings of the IEEE, 86, 2278-2324.
[3] Y. Netzer, T. Wang, A. Coates, A. Bissacco, B. Wu, A.Y. Ng, Reading Digits in Natural Images with Unsupervised Feature Learning NIPS Workshop on Deep Learning and Unsupervised Feature Learning 2011.