BERT を使用した文書からの回答の抽出
この例では、抽出型質問応答用に事前学習済みの BERT モデルを変更および微調整する方法を説明します。抽出型質問応答では、質問に加えて、回答が含まれているソース文書をモデルに提供します。その後、モデルによって、質問に回答する厳密な抜粋がソース文書から検出されます。
この例で使用されるデータセットは、Stanford Question Answering Dataset (SQuAD) 2.0 データセット [1] です。
データのインポート
前処理された SQuAD 2.0 のデータを読み込みます。
dataFolder = fullfile(tempdir,"squad2_data"); if ~datasetExists(dataFolder) zipFile = matlab.internal.examples.downloadSupportFile("textanalytics","data/squad2_data.zip"); unzip(zipFile,dataFolder); end data = load(fullfile(dataFolder,"squad2_data.mat"));
前処理されたデータセットには、学習データと検証データが含まれています。
trainData = data.trainingData; validationData = data.valData;
検証データセットの最初の質問を出力します。
validationData.Question(1)
ans = "In what country is Normandy located?"
検証データセットの最初のコンテキストを出力します。この情報には、AnswerStart インデックスから開始される、質問に対する回答が含まれています。
validationData.Context(1)
ans =
"The Normans (Norman: Nourmands; French: Normands; Latin: Normanni) were the people who in the 10th and 11th centuries gave their name to Normandy, a region in France. They were descended from Norse ("Norman" comes from "Norseman") raiders and pirates from Denmark, Iceland and Norway who, under their leader Rollo, agreed to swear fealty to King Charles III of West Francia. Through generations of assimilation and mixing with the native Frankish and Roman-Gaulish populations, their descendants would gradually merge with the Carolingian-based cultures of West Francia. The distinct cultural and ethnic identity of the Normans emerged initially in the first half of the 10th century, and it continued to evolve over the succeeding centuries."
validationData.AnswerStart(1)
ans = 159
質問に対する回答を出力します。
validationData.Answer(1)
ans = "France"
学習後にモデルを評価するには、検証データをより小さな検証セットとテスト セットに分割します。
cv = cvpartition(length(validationData.Question),Holdout=0.2); idxTest = cv.test; testData = validationData(idxTest,:); validationData = validationData(~idxTest,:);
事前学習済みの BERT モデルの読み込みと変更
bert関数を使用して、事前学習済みの BERT-tiny モデルを読み込みます。Text Analytics Toolbox™ Model for BERT-Tiny Network サポート パッケージがインストールされていない場合、関数によってダウンロード用リンクが表示されます。
[net,tokenizer] = bert(Model="tiny");抽出型質問応答では、コンテキスト内における回答の開始インデックスと終了インデックスを予測します。これを行うには、2 つの出力をもつ全結合層をネットワークの最後に追加します。
outputLayer = net.OutputNames{1};
net = addLayers(net,fullyConnectedLayer(2));
net = connectLayers(net,outputLayer,"fc");
net = initialize(net);学習用データの準備
この例の最後に定義されている補助関数 prepareData を使用し、データをトークン化して前処理します。このプロセスには数分かかる場合があります。
[trainInputID,trainSegmentID,trainStartIdx,trainEndIdx] = prepareData(trainData,tokenizer); [validationInputID,validationSegmentID,validationStartIdx,validationEndIdx] = prepareData(validationData,tokenizer); [testInputID,testSegmentID,testStartIdx,testEndIdx] = prepareData(testData,tokenizer);
BERT ミニバッチ キューの作成
学習中に学習データと検証データをモデルに与えるための minibatchqueue オブジェクトを作成します。
mbqTrain = bertMiniBatchQueueForTraining(trainInputID,trainSegmentID,trainStartIdx,trainEndIdx,tokenizer.PaddingCode); mbqValidation = bertMiniBatchQueueForTraining(validationInputID,validationSegmentID,validationStartIdx,validationEndIdx,tokenizer.PaddingCode);
学習オプションの指定
学習オプションを指定します。オプションの中から選択するには、経験的解析が必要です。実験を実行してさまざまな学習オプションの構成を調べるには、Experiment Managerアプリを使用できます。
Adam オプティマイザーを使用して学習させます。
学習を 5 エポック行います。
微調整を行うため、学習率を下げます。学習率
2e-5を使用して学習させます。ミニバッチのサイズを
32に設定します。検証データを使用してネットワークを検証します。
すべてのエポックでデータをシャッフルします。
プロットで学習の進行状況を監視し、カスタム メトリクス
exactMatchを監視して評価を行います。この関数はこの例の最後で定義されています。詳細出力を無効にします。
miniBatchSize = 32; numEpochs = 5; learnRate = 2e-5; options = trainingOptions("adam", ... MaxEpochs=numEpochs, ... InitialLearnRate=learnRate, ... MiniBatchSize=miniBatchSize, ... ValidationData=mbqValidation, ... Shuffle="every-epoch", ... Metrics=@exactMatch, ... Plots="training-progress", ... Verbose=false);
カスタム損失関数を定義します。questionAnsweringLoss 関数は、クロスエントロピー損失関数を使用して、予測された回答開始位置と回答終了位置を実際の位置と比較することにより、質問応答タスクの損失を計算します。
function L = questionAnsweringLoss(Y,T) YStart = dlarray(stripdims(reshape(Y(1,:,:),[],size(Y,3))),"BC"); YEnd = dlarray(stripdims(reshape(Y(2,:,:),[],size(Y,3))),"BC"); TStart = T(1,:); TEnd = T(2,:); YStart = softmax(YStart); YEnd = softmax(YEnd); LStart = indexcrossentropy(YStart,TStart); LEnd = indexcrossentropy(YEnd,TEnd); L = (LStart + LEnd) / 2; end
ネットワークの学習
BERT ネットワークに学習させます。
net = trainnet(mbqTrain,net,@(Y,T) questionAnsweringLoss(Y,T),options);
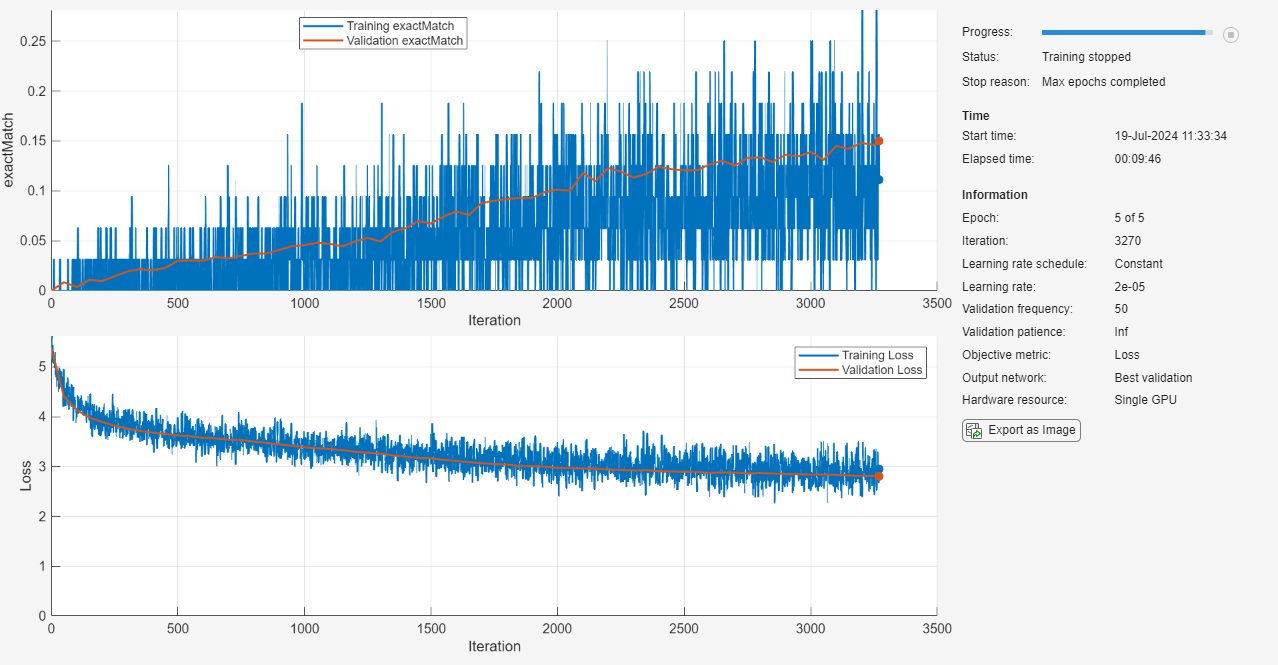
ネットワークのテスト
入力データに基づいて、予測に適したミニバッチ キューを作成します。
mbqTest = bertMiniBatchQueueForPrediction(testInputID,testSegmentID,tokenizer)
mbqTest =
minibatchqueue with 3 outputs and properties:
Mini-batch creation:
MiniBatchSize: 128
PartialMiniBatch: 'return'
MiniBatchFcn: @(inputIds,segmentIds)preprocessPredictors(inputIds,segmentIds,paddingValue)
PreprocessingEnvironment: 'serial'
Outputs:
OutputCast: {'single' 'single' 'single'}
OutputAsDlarray: [1 1 1]
MiniBatchFormat: {'CTB' 'CTB' 'CTB'}
OutputEnvironment: {'auto' 'auto' 'auto'}
テスト データでモデルを評価し、完全一致メトリクスを計算します。
YPred = minibatchpredict(net,mbqTest,MiniBatchSize=miniBatchSize,UniformOutput=false); YTest = [testStartIdx testEndIdx];
すべてのバッチを比較してその結果を結合し、すべてのバッチについて平均した結果を取得します。
totalExactMatch = 0; for k=1:length(YPred) totalExactMatch = totalExactMatch + exactMatch(YPred{k}, YTest(k,:)); end testExactMatch = totalExactMatch/length(YPred)
testExactMatch =
1(C) × 1(B) × 1(T) dlarray
0.1528
質問への回答
微調整されたモデルを使用することで、新しい質問に対する回答を予測できます。
question = wordTokenize(tokenizer,"When was the Hubble Space Telescope launched?"); context = wordTokenize(tokenizer,"The Hubble Space Telescope is a large telescope in space launched in 1990." + ... " It is one of the largest and most versatile telescopes, renowned for its deep space images" + ... " and has made many astronomical discoveries.");
開始トークンと終了トークンを予測します。
[inputIds, segIds, idx2words] = encodeTokens(tokenizer,question,context); attMask = ones("like",segIds{1}); Y = predict(net,inputIds{1},segIds{1},attMask,InputDataFormats=["CTB","CTB","CTB"]); [~, idx] = max(Y, [], 2); YStart = idx(1)
YStart = 25
YEnd = idx(2)
YEnd = 25
取得したトークンを元の単語に戻して回答を表示します。
idx2words = idx2words{1};
answerIdx = unique(idx2words(YStart:YEnd));
context = context{1};
answer = context(answerIdx)answer = "1990"
補助関数
prepareData 関数は、入力トークナイザーを使用して SQuAD データセットからの質問とコンテキストをトークン化し、トークンレベルにおける回答の位置を見つけます。この例では、最大 128 個のトークンをもつ短いコンテキストを使用します。
function [allInputIds, allSegIds, allStartIdx, allEndIdx] = prepareData(data, tokenizer) maxSeqLength = 128; numElements = height(data); allInputIds = cell(numElements,1); allSegIds = cell(numElements,1); allStartIdx = zeros(numElements,1); allEndIdx = zeros(numElements,1); % Process each data element for i = 1:numElements question = data(i,:).Question; context = data(i,:).Context; answer = data(i,:).Answer; % Tokenize and truncate input [inputIds, segIds] = encode(tokenizer,question,context); inputIds = inputIds{:}; segIds = segIds{:}; % Only process if within max sequence length if numel(inputIds) <= maxSeqLength tokenizedAnswer = encode(tokenizer,answer,AddSpecialTokens=false); tokenizedAnswer = tokenizedAnswer{:}; indices = strfind(inputIds,tokenizedAnswer); % If answer is found in the context if ~isempty(indices) startIndex = indices(1); endIndex = startIndex + numel(tokenizedAnswer) - 1; allInputIds{i} = inputIds; allSegIds{i} = segIds; allStartIdx(i) = startIndex; allEndIdx(i) = endIndex; end end end % Remove empty entries validEntries = allStartIdx > 0; allInputIds = allInputIds(validEntries); allSegIds = allSegIds(validEntries); allStartIdx = allStartIdx(validEntries); allEndIdx = allEndIdx(validEntries); end
exactMatch 関数は、予測された回答開始位置と回答終了位置が実際の位置と完全に一致するかどうかを測定する完全一致メトリクスを計算します。
function val = exactMatch(Y,T) batchSize = size(Y,finddim(Y,"B")); [~, idx] = max(Y,[],3); val = idx == T; val = all(val,1); val = sum(val)/batchSize; end
bertMiniBatchQueueForTraining 関数は、質問応答用の BERT モデルに学習させるため、文書とラベルから minibatchqueue オブジェクトを作成します。bertMiniBatchQueueForPrediction 関数は、学習済みの BERT モデルを使用して予測を行うため、文書から minibatchqueue オブジェクトを作成します。
function mbq = bertMiniBatchQueueForTraining(inputIDs,segmentIDs,startIdx,endIdx,paddingValue) inputIDsDS = arrayDatastore(inputIDs,OutputType="same"); segIDsDS = arrayDatastore(segmentIDs,OutputType="same"); Y = arrayDatastore([startIdx endIdx]); cds = combine(inputIDsDS,segIDsDS,Y); mbq = minibatchqueue(cds,4,... MiniBatchFcn=@(inputIds,segmentIds,targets) preprocessMiniBatch(inputIds, ... segmentIds, ... targets, ... paddingValue), ... MiniBatchFormat=["CTB" "CTB" "CTB" "BC"]); end function mbq = bertMiniBatchQueueForPrediction(inputIDs,segmentIDs,paddingValue) inputIDsDS = arrayDatastore(inputIDs,OutputType="same"); segIDsDS = arrayDatastore(segmentIDs,OutputType="same"); cds = combine(inputIDsDS,segIDsDS); mbq = minibatchqueue(cds,3,... MiniBatchFcn=@(inputIds,segmentIds) preprocessPredictors(inputIds, ... segmentIds, ... paddingValue), ... MiniBatchFormat=["CTB" "CTB" "CTB"]); end function [inputIDs, mask, segmentIDs, targets] = preprocessMiniBatch(inputIDs,segmentIDs,targets,paddingValue) [inputIDs, mask] = padsequences(inputIDs,2,PaddingValue=paddingValue); segmentIDs = padsequences(segmentIDs,2,PaddingValue=paddingValue); targets = cell2mat(targets); end
参考文献
[1] Rajpurkar, Pranav, Robin Jia, and Percy Liang. "Know What You Don’t Know: Unanswerable Questions for SQuAD." Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). Association for Computational Linguistics, 2018.
参考
bert | trainnet (Deep Learning Toolbox) | wordTokenize | encodeTokens | trainingOptions (Deep Learning Toolbox) | minibatchqueue (Deep Learning Toolbox) | minibatchpredict (Deep Learning Toolbox)