vec2word
単語への埋め込みベクトルのマッピング
構文
説明
例
fastTextWordEmbedding を使用して、事前学習済みの単語埋め込みを読み込みます。この関数には、Text Analytics Toolbox™ Model for fastText English 16 Billion Token Word Embedding サポート パッケージが必要です。このサポート パッケージがインストールされていない場合、関数によってダウンロード用リンクが表示されます。
emb = fastTextWordEmbedding
emb =
wordEmbedding with properties:
Dimension: 300
Vocabulary: [1×1000000 string]
word2vec を使用して、"Italy"、"Rome"、および "Paris" という単語をベクトルにマッピングします。
italy = word2vec(emb,"Italy"); rome = word2vec(emb,"Rome"); paris = word2vec(emb,"Paris");
vec2word を使用して、ベクトル italy - rome + paris を単語にマッピングします。
word = vec2word(emb,italy - rome + paris)
word = "France"
単語埋め込みベクトルに最も近い上位 5 つの単語を見つけ、それらの距離を調べます。
fastTextWordEmbedding を使用して、事前学習済みの単語埋め込みを読み込みます。この関数には、Text Analytics Toolbox™ Model for fastText English 16 Billion Token Word Embedding サポート パッケージが必要です。このサポート パッケージがインストールされていない場合、関数によってダウンロード用リンクが表示されます。
emb = fastTextWordEmbedding;
word2vec を使用して、"Italy"、"Rome"、および "Paris" という単語をベクトルにマッピングします。
italy = word2vec(emb,"Italy"); rome = word2vec(emb,"Rome"); paris = word2vec(emb,"Paris");
vec2word を使用して、ベクトル italy - rome + paris を単語にマッピングします。ユークリッド距離計量を使用して、最も近い上位 5 つの単語を見つけます。
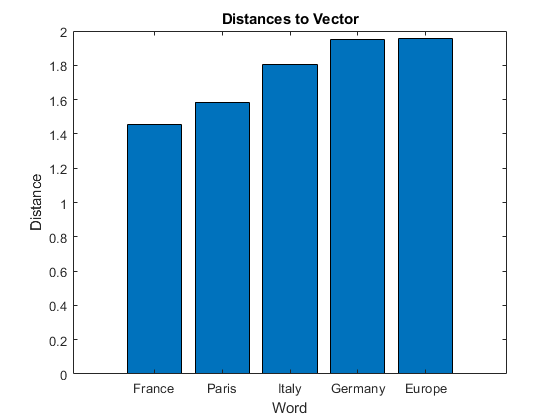
k = 5; M = italy - rome + paris; [words,dist] = vec2word(emb,M,k,'Distance','euclidean');
単語と距離を棒グラフにプロットします。
figure; bar(dist) xticklabels(words) xlabel("Word") ylabel("Distance") title("Distances to Vector")
入力引数
出力引数
バージョン履歴
R2017b で導入