テキスト散布図を使用した単語埋め込みの可視化
この例では、2 次元および 3 次元の t-SNE とテキスト散布図を使用して単語埋め込みを可視化する方法を示します。
単語埋め込みは、ボキャブラリ内の単語を実数ベクトルにマッピングします。ベクトルは単語のセマンティクスを取得しようとするため、互いに類似する単語はベクトルも類似するようになります。一部の埋め込みでは、"Italy is to France as Rome is to Paris" (フランスに対してのイタリアは、パリに対してのローマに同じ) のような単語間の関係も取得されます。ベクトル形式では、この関係は になります。
事前学習済みの単語埋め込みの読み込み
fastTextWordEmbedding を使用して、事前学習済みの単語埋め込みを読み込みます。この関数には、Text Analytics Toolbox™ Model for fastText English 16 Billion Token Word Embedding サポート パッケージが必要です。このサポート パッケージがインストールされていない場合、関数によってダウンロード用リンクが表示されます。
emb = fastTextWordEmbedding
emb =
wordEmbedding with properties:
Dimension: 300
Vocabulary: [1×999994 string]
word2vec と vec2word を使用して単語埋め込みを調査します。word2vec を使用して、"Italy"、"Rome"、および "Paris" という単語をベクトルに変換します。
italy = word2vec(emb,"Italy"); rome = word2vec(emb,"Rome"); paris = word2vec(emb,"Paris");
italy - rome + paris で指定されたベクトルを計算します。このベクトルは、単語 "Rome" のセマンティクスを除いた単語 "Italy" のセマンティクスの意味をカプセル化するとともに、単語 "Paris" のセマンティクスも含めます。
vec = italy - rome + paris
vec2word を使用して、vec への埋め込みで最も近い単語を見つけます。
word = vec2word(emb,vec)
word = "France"
2 次元テキスト散布図の作成
tsne と textscatter を使用して 2 次元テキスト散布図を作成し、単語埋め込みを可視化します。
word2vec を使用して、最初の 5000 語をベクトルに変換します。V は長さ 300 の単語ベクトルの行列です。
words = emb.Vocabulary(1:5000); V = word2vec(emb,words); size(V)
tsne を使用して単語ベクトルを 2 次元空間に埋め込みます。関数の実行には数分かかる場合があります。収束情報を表示する場合は、名前と値のペア 'Verbose' を 1 に設定します。
XY = tsne(V);
2 次元テキスト散布図の XY で指定された座標に単語をプロットします。読みやすくするために、textscatter は、既定ですべての入力単語を表示するのではなく、代わりにマーカーを表示します。
figure
textscatter(XY,words)
title("Word Embedding t-SNE Plot")
プロットのセクションにズームインします。
xlim([-18 -5]) ylim([11 21])

3 次元テキスト散布図の作成
tsne と textscatter を使用して 3 次元テキスト散布図を作成し、単語埋め込みを可視化します。
word2vec を使用して、最初の 5000 語をベクトルに変換します。V は長さ 300 の単語ベクトルの行列です。
words = emb.Vocabulary(1:5000); V = word2vec(emb,words); size(V)
次元数を 3 に指定して tsne を使用し、単語ベクトルを 3 次元空間に埋め込みます。関数の実行には数分かかる場合があります。収束情報を表示する場合は、名前と値のペア 'Verbose' を 1 に設定できます。
XYZ = tsne(V,'NumDimensions',3);3 次元テキスト散布図の XYZ で指定された座標に単語をプロットします。
figure
ts = textscatter3(XYZ,words);
title("3-D Word Embedding t-SNE Plot")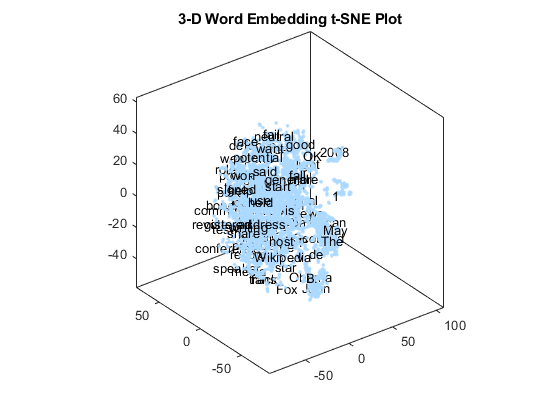
プロットのセクションにズームインします。
xlim([12.04 19.48]) ylim([-2.66 3.40]) zlim([10.03 14.53])

クラスター解析の実行
word2vec を使用して、最初の 5000 語をベクトルに変換します。V は長さ 300 の単語ベクトルの行列です。
words = emb.Vocabulary(1:5000); V = word2vec(emb,words); size(V)
kmeans を使用して 25 個のクラスターを検出します。
cidx = kmeans(V,25,'dist','sqeuclidean');
前に計算した 2 次元 t-SNE データ座標を使用して、クラスターをテキスト散布図で可視化します。
figure textscatter(XY,words,'ColorData',categorical(cidx)); title("Word Embedding t-SNE Plot")
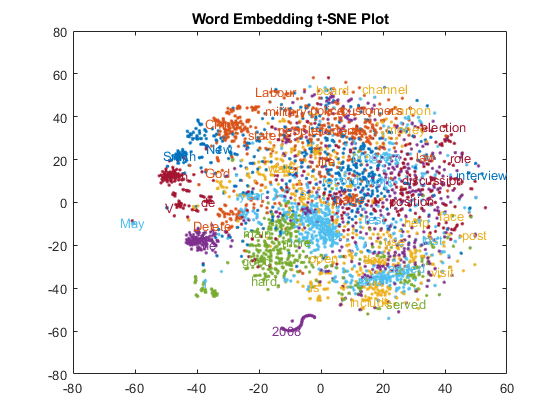
プロットのセクションにズームインします。
xlim([13 24]) ylim([-47 -35])

参考
readWordEmbedding | textscatter | textscatter3 | word2vec | vec2word | wordEmbedding | tokenizedDocument