ldaModel
潜在的ディリクレ配分 (LDA) モデル
説明
潜在的ディリクレ配分 (LDA) モデルは、文書のコレクションに内在するトピックを発見し、トピック内の単語の確率を推測するトピック モデルです。bag-of-n-grams モデルを使用して当てはめられたモデルの場合、ソフトウェアは n-gram を個々の単語として扱います。
作成
関数 fitlda を使用して LDA モデルを作成します。
プロパティ
オブジェクト関数
logp | Document log-probabilities and goodness of fit of LDA model |
predict | Predict top LDA topics of documents |
resume | Resume fitting LDA model |
topkwords | Most important words in bag-of-words model or LDA topic |
transform | Transform documents into lower-dimensional space |
wordcloud | Create word cloud chart from text, bag-of-words model, bag-of-n-grams model, or LDA model |
例
この例の結果を再現するために、rng を 'default' に設定します。
rng('default')サンプル データを読み込みます。ファイル sonnetsPreprocessed.txt には、シェイクスピアのソネット集の前処理されたバージョンが格納されています。ファイルには、1 行に 1 つのソネットが含まれ、単語がスペースで区切られています。sonnetsPreprocessed.txt からテキストを抽出し、テキストを改行文字で文書に分割した後、文書をトークン化します。
filename = "sonnetsPreprocessed.txt";
str = extractFileText(filename);
textData = split(str,newline);
documents = tokenizedDocument(textData);bagOfWords を使用して bag-of-words モデルを作成します。
bag = bagOfWords(documents)
bag =
bagOfWords with properties:
Counts: [154×3092 double]
Vocabulary: ["fairest" "creatures" "desire" "increase" "thereby" "beautys" "rose" "might" "never" "die" "riper" "time" "decease" "tender" "heir" "bear" "memory" "thou" "contracted" … ]
NumWords: 3092
NumDocuments: 154
トピック数 4 の LDA モデルを当てはめます。
numTopics = 4; mdl = fitlda(bag,numTopics)
Initial topic assignments sampled in 0.263378 seconds. ===================================================================================== | Iteration | Time per | Relative | Training | Topic | Topic | | | iteration | change in | perplexity | concentration | concentration | | | (seconds) | log(L) | | | iterations | ===================================================================================== | 0 | 0.17 | | 1.215e+03 | 1.000 | 0 | | 1 | 0.02 | 1.0482e-02 | 1.128e+03 | 1.000 | 0 | | 2 | 0.02 | 1.7190e-03 | 1.115e+03 | 1.000 | 0 | | 3 | 0.01 | 4.3796e-04 | 1.118e+03 | 1.000 | 0 | | 4 | 0.01 | 9.4193e-04 | 1.111e+03 | 1.000 | 0 | | 5 | 0.01 | 3.7079e-04 | 1.108e+03 | 1.000 | 0 | | 6 | 0.01 | 9.5777e-05 | 1.107e+03 | 1.000 | 0 | =====================================================================================
mdl =
ldaModel with properties:
NumTopics: 4
WordConcentration: 1
TopicConcentration: 1
CorpusTopicProbabilities: [0.2500 0.2500 0.2500 0.2500]
DocumentTopicProbabilities: [154×4 double]
TopicWordProbabilities: [3092×4 double]
Vocabulary: ["fairest" "creatures" "desire" "increase" "thereby" "beautys" "rose" "might" "never" "die" "riper" "time" "decease" "tender" "heir" "bear" "memory" "thou" … ]
TopicOrder: 'initial-fit-probability'
FitInfo: [1×1 struct]
ワード クラウドを使用してトピックを可視化します。
figure for topicIdx = 1:4 subplot(2,2,topicIdx) wordcloud(mdl,topicIdx); title("Topic: " + topicIdx) end
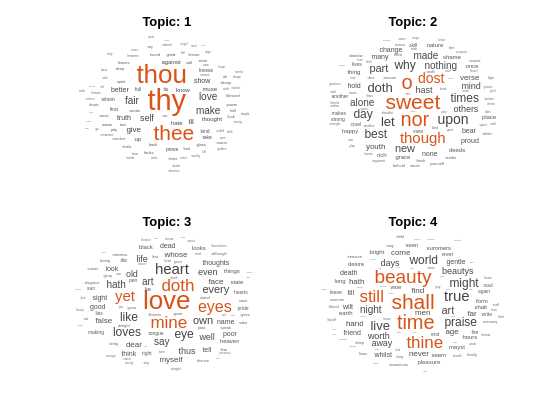
LDA トピックの最高確率単語の table を作成します。
結果を再現するために、rng を 'default' に設定します。
rng('default')サンプル データを読み込みます。ファイル sonnetsPreprocessed.txt には、シェイクスピアのソネット集の前処理されたバージョンが格納されています。ファイルには、1 行に 1 つのソネットが含まれ、単語がスペースで区切られています。sonnetsPreprocessed.txt からテキストを抽出し、テキストを改行文字で文書に分割した後、文書をトークン化します。
filename = "sonnetsPreprocessed.txt";
str = extractFileText(filename);
textData = split(str,newline);
documents = tokenizedDocument(textData);bagOfWords を使用して bag-of-words モデルを作成します。
bag = bagOfWords(documents);
トピック数 20 の LDA モデルを当てはめます。詳細出力を抑制するには、'Verbose' を 0 に設定します。
numTopics = 20;
mdl = fitlda(bag,numTopics,'Verbose',0);最初のトピックの上位 20 語を見つけます。
k = 20; topicIdx = 1; tbl = topkwords(mdl,k,topicIdx)
tbl=20×2 table
"eyes" 0.1116
"beauty" 0.0578
"hath" 0.0558
"still" 0.0498
"true" 0.0438
"mine" 0.0339
"find" 0.0319
"black" 0.0259
"look" 0.0239
"tis" 0.0239
"kind" 0.0219
"seen" 0.0219
"found" 0.0179
"sin" 0.0159
⋮
スコアに対して逆平均スケーリングを使用して、最初のトピックの上位 20 語を見つけます。
tbl = topkwords(mdl,k,topicIdx,'Scaling','inversemean')
tbl=20×2 table
"eyes" 1.2718
"beauty" 0.5902
"hath" 0.5692
"still" 0.5027
"true" 0.4372
"mine" 0.3276
"find" 0.3254
"black" 0.2593
"tis" 0.2375
"look" 0.2252
"kind" 0.2159
"seen" 0.2159
"found" 0.1733
"sin" 0.1522
⋮
スケーリングされたスコアをサイズ データとして使用してワード クラウドを作成します。
figure wordcloud(tbl.Word,tbl.Score);

LDA モデルを当てはめるために使用される文書の文書トピック確率 (トピック混合率とも呼ばれる) を取得します。
結果を再現するために、rng を 'default' に設定します。
rng('default')サンプル データを読み込みます。ファイル sonnetsPreprocessed.txt には、シェイクスピアのソネット集の前処理されたバージョンが格納されています。ファイルには、1 行に 1 つのソネットが含まれ、単語がスペースで区切られています。sonnetsPreprocessed.txt からテキストを抽出し、テキストを改行文字で文書に分割した後、文書をトークン化します。
filename = "sonnetsPreprocessed.txt";
str = extractFileText(filename);
textData = split(str,newline);
documents = tokenizedDocument(textData);bagOfWords を使用して bag-of-words モデルを作成します。
bag = bagOfWords(documents);
トピック数 20 の LDA モデルを当てはめます。詳細出力を抑制するには、'Verbose' を 0 に設定します。
numTopics = 20;
mdl = fitlda(bag,numTopics,'Verbose',0)mdl =
ldaModel with properties:
NumTopics: 20
WordConcentration: 1
TopicConcentration: 5
CorpusTopicProbabilities: [0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500]
DocumentTopicProbabilities: [154×20 double]
TopicWordProbabilities: [3092×20 double]
Vocabulary: ["fairest" "creatures" "desire" "increase" "thereby" "beautys" "rose" "might" "never" "die" "riper" "time" "decease" "tender" "heir" "bear" "memory" … ] (1×3092 string)
TopicOrder: 'initial-fit-probability'
FitInfo: [1×1 struct]
学習データ内の最初の文書のトピック確率を表示します。
topicMixtures = mdl.DocumentTopicProbabilities; figure bar(topicMixtures(1,:)) title("Document 1 Topic Probabilities") xlabel("Topic Index") ylabel("Probability")

この例の結果を再現するために、rng を 'default' に設定します。
rng('default')サンプル データを読み込みます。ファイル sonnetsPreprocessed.txt には、シェイクスピアのソネット集の前処理されたバージョンが格納されています。ファイルには、1 行に 1 つのソネットが含まれ、単語がスペースで区切られています。sonnetsPreprocessed.txt からテキストを抽出し、テキストを改行文字で文書に分割した後、文書をトークン化します。
filename = "sonnetsPreprocessed.txt";
str = extractFileText(filename);
textData = split(str,newline);
documents = tokenizedDocument(textData);bagOfWords を使用して bag-of-words モデルを作成します。
bag = bagOfWords(documents)
bag =
bagOfWords with properties:
Counts: [154×3092 double]
Vocabulary: ["fairest" "creatures" "desire" "increase" "thereby" "beautys" "rose" "might" "never" "die" "riper" "time" "decease" "tender" "heir" "bear" "memory" "thou" "contracted" … ]
NumWords: 3092
NumDocuments: 154
トピック数 20 の LDA モデルを当てはめます。
numTopics = 20; mdl = fitlda(bag,numTopics)
Initial topic assignments sampled in 0.513255 seconds. ===================================================================================== | Iteration | Time per | Relative | Training | Topic | Topic | | | iteration | change in | perplexity | concentration | concentration | | | (seconds) | log(L) | | | iterations | ===================================================================================== | 0 | 0.04 | | 1.159e+03 | 5.000 | 0 | | 1 | 0.05 | 5.4884e-02 | 8.028e+02 | 5.000 | 0 | | 2 | 0.04 | 4.7400e-03 | 7.778e+02 | 5.000 | 0 | | 3 | 0.04 | 3.4597e-03 | 7.602e+02 | 5.000 | 0 | | 4 | 0.03 | 3.4662e-03 | 7.430e+02 | 5.000 | 0 | | 5 | 0.03 | 2.9259e-03 | 7.288e+02 | 5.000 | 0 | | 6 | 0.03 | 6.4180e-05 | 7.291e+02 | 5.000 | 0 | =====================================================================================
mdl =
ldaModel with properties:
NumTopics: 20
WordConcentration: 1
TopicConcentration: 5
CorpusTopicProbabilities: [0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500]
DocumentTopicProbabilities: [154×20 double]
TopicWordProbabilities: [3092×20 double]
Vocabulary: ["fairest" "creatures" "desire" "increase" "thereby" "beautys" "rose" "might" "never" "die" "riper" "time" "decease" "tender" "heir" "bear" "memory" "thou" … ]
TopicOrder: 'initial-fit-probability'
FitInfo: [1×1 struct]
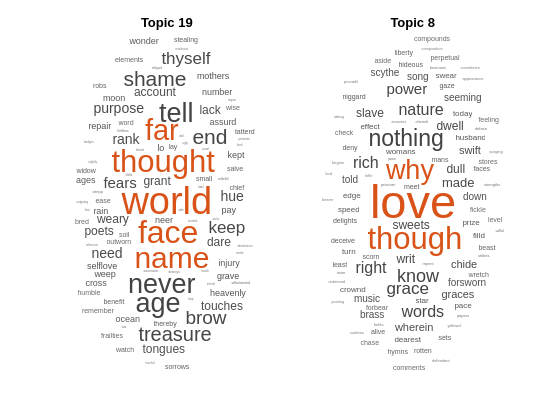
新しい文書の配列の上位トピックを予測します。
newDocuments = tokenizedDocument([
"what's in a name? a rose by any other name would smell as sweet."
"if music be the food of love, play on."]);
topicIdx = predict(mdl,newDocuments)topicIdx = 2×1
19
8
ワード クラウドを使用して、予測されたトピックを可視化します。
figure subplot(1,2,1) wordcloud(mdl,topicIdx(1)); title("Topic " + topicIdx(1)) subplot(1,2,2) wordcloud(mdl,topicIdx(2)); title("Topic " + topicIdx(2))
詳細
"潜在的ディリクレ配分" (LDA) モデルは、文書のコレクションに内在するトピックを発見し、トピック内の単語の確率を推測する文書トピック モデルです。LDA は、D 個の文書のコレクションを、単語確率 のベクトルによって特徴付けられた K 個のトピックにわたって、トピック混合率 としてモデル化します。このモデルは、トピック混合率 とトピック がそれぞれ集中度パラメーター と をもつディリクレ分布に従うと仮定します。
トピックの混合率 は、長さ K の確率ベクトルです。ここで、K はトピックの数です。エントリ は、トピック i が d 番目の文書に出現する確率です。トピックの混合率は、ldaModel オブジェクトの DocumentTopicProbabilities プロパティの行に対応します。
トピック は、長さ V の確率ベクトルです。ここで、V はボキャブラリの単語数です。エントリ は、ボキャブラリの v 番目の単語が i 番目のトピックに出現する確率に対応します。トピック は、ldaModel オブジェクトの TopicWordProbabilities プロパティの列に対応します。
トピック とそのトピック混合率でのディリクレ事前分布 について、LDA は文書に対して次の生成プロセスを仮定します。
トピックの混合率を でサンプリングします。確率変数 は、長さ K の確率ベクトルです。ここで、K はトピックの数です。
文書内の単語ごとに、次のようにします。
トピック インデックスを でサンプリングします。確率変数 z は 1 から K までの整数です。ここで、K はトピックの数です。
単語を でサンプリングします。確率変数 w は 1 ~ V の整数です。ここで、V はボキャブラリの単語数であり、ボキャブラリ内の対応する単語を表します。
この生成プロセスの下で、単語 を含む文書の同時分布と、トピックの混合率 、トピック インデックス が次によって与えられます。
ここで、N は文書内の単語数です。z に対する同時分布を合計し、 で積分することで、文書 w の周辺分布が得られます。
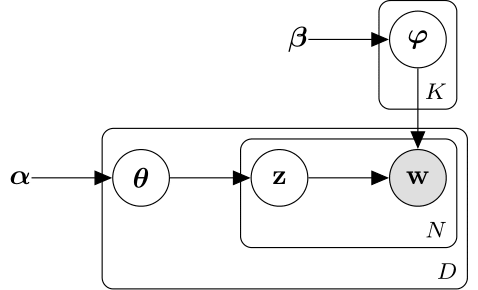
次の図は、LDA モデルを確率的グラフィカル モデルとして示したものです。網かけのあるノードは観測変数、網かけのないノードは潜在変数、枠線のないノードはモデル パラメーターです。矢印は確率変数間の依存関係を強調しており、各グループは繰り返しノードを示しています。
バージョン履歴
R2017b で導入