LDA モデルのトピック数の選択
この例では、潜在的ディリクレ配分 (LDA) モデルの適切なトピック数を決定する方法を示します。
適切なトピック数を決定するために、さまざまなトピック数での LDA モデルの当てはまり具合を比較できます。ホールドアウトされた文書セットのパープレキシティを計算することで、LDA モデルの当てはまり具合を評価できます。パープレキシティは、モデルが文書セットをどの程度適切に記述しているかを示します。パープレキシティが低いほど、当てはめが優れていることを示します。
テキスト データの抽出と前処理
サンプル データを読み込みます。ファイル factoryReports.csv には、各イベントの説明テキストとカテゴリカル ラベルを含む工場レポートが格納されています。フィールド Description からテキスト データを抽出します。
filename = "factoryReports.csv"; data = readtable(filename,TextType="string"); textData = data.Description;
この例の最後にリストされている関数 preprocessText を使用して、テキスト データをトークン化し、前処理します。
documents = preprocessText(textData); documents(1:5)
ans =
5×1 tokenizedDocument:
6 tokens: item occasionally get stuck scanner spool
7 tokens: loud rattling bang sound come assembler piston
4 tokens: cut power start plant
3 tokens: fry capacitor assembler
3 tokens: mixer trip fuse
ランダムに選んだ文書の 10% を検証用に残しておきます。
numDocuments = numel(documents); cvp = cvpartition(numDocuments,HoldOut=0.1); documentsTrain = documents(cvp.training); documentsValidation = documents(cvp.test);
学習文書から bag-of-words モデルを作成します。合計で 2 回以上出現しない単語を削除します。単語を含まない文書すべてを削除します。
bag = bagOfWords(documentsTrain); bag = removeInfrequentWords(bag,2); bag = removeEmptyDocuments(bag);
トピック数の選択
目標は、他のトピック数と比較してパープレキシティが最も小さくなるトピック数を選択することです。考慮事項はこれだけではありません。多数のトピックを当てはめたモデルは、収束に時間がかかる場合があります。トレードオフの影響を確認するには、当てはまり具合と当てはめのための時間の両方を計算します。最適なトピック数の値が高い場合、当てはめプロセスを高速化するために、より低い値を選択するということもあり得ます。
トピック数の値の範囲に対して、いくつかの LDA モデルを当てはめます。ホールドアウトされたテスト文書セットについて、各モデルの当てはめのための時間とパープレキシティを比較します。パープレキシティは関数 logp の 2 番目の出力です。最初の出力を何も割り当てずに 2 番目の出力を取得するには、~ 記号を使用します。当てはめのための時間は、最後の反復に対する TimeSinceStart 値です。この値は、LDA モデルの FitInfo プロパティの History struct にあります。
より高速に当てはめるには、'Solver' を 'savb' に指定します。詳細出力を抑制するには、'Verbose' を 0 に設定します。この実行には数分かかることがあります。
numTopicsRange = [5 10 15 20 40]; for i = 1:numel(numTopicsRange) numTopics = numTopicsRange(i); mdl = fitlda(bag,numTopics, ... Solver="savb", ... Verbose=0); [~,validationPerplexity(i)] = logp(mdl,documentsValidation); timeElapsed(i) = mdl.FitInfo.History.TimeSinceStart(end); end
トピック数ごとのパープレキシティと経過時間をプロットに表示します。左の軸にパープレキシティ、右の軸に経過時間をプロットします。
figure yyaxis left plot(numTopicsRange,validationPerplexity,"+-") ylabel("Validation Perplexity") yyaxis right plot(numTopicsRange,timeElapsed,"o-") ylabel("Time Elapsed (s)") legend(["Validation Perplexity" "Time Elapsed (s)"],Location="southeast") xlabel("Number of Topics")
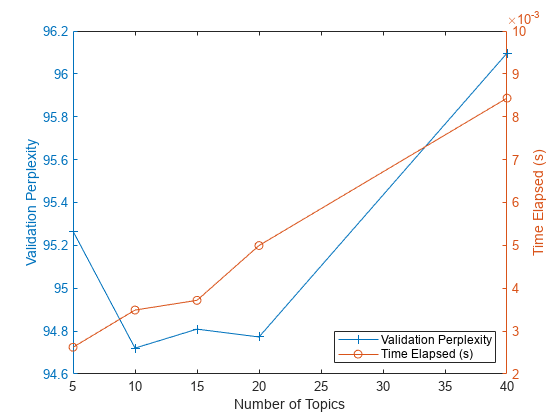
プロットは、10 ~ 20 個のトピックのモデルを当てはめるのが適切な選択であることを示唆しています。パープレキシティは、他のトピック数のモデルと比較して低くなっています。このソルバーでは、これだけのトピックに対する経過時間も妥当です。さまざまなソルバーを使用する場合、トピックの数を増やすと当てはめが向上する可能性がありますが、モデルの当てはめが収束するまで時間がかかることがわかります。
例の前処理関数
関数 preprocessText は、以下の手順を順番に実行します。
tokenizedDocumentを使用してテキストをトークン化する。レンマ化を改善するために、
addPartOfSpeechDetailsを使用して品詞の詳細を追加する。normalizeWordsを使用して単語をレンマ化する。removeShortWordsを使用して、2 文字以下の単語を削除する。removeLongWordsを使用して、15 文字以上の単語を削除する。removeStopWordsを使用して、ストップ ワード ("and"、"of"、"the" など) のリストを削除する。erasePunctuationを使用して句読点を消去する。
テキスト処理のオプションを対話的に調べる方法を示す例については、Preprocess Text Data in Live Editorを参照してください。
function documents = preprocessText(textData) % Tokenize. documents = tokenizedDocument(textData); % Lemmatize. documents = addPartOfSpeechDetails(documents); documents = normalizeWords(documents,Style="lemma"); % Remove short and long words. documents = removeShortWords(documents,2); documents = removeLongWords(documents,15); % Remove stop words. documents = removeStopWords(documents,IgnoreCase=false); % Erase punctuation. documents = erasePunctuation(documents); end
参考
tokenizedDocument | bagOfWords | removeStopWords | logp | bagOfWords | fitlda | ldaModel | erasePunctuation | removeShortWords | removeLongWords | normalizeWords | addPartOfSpeechDetails | removeInfrequentWords | removeEmptyDocuments