rangesearch
入力データを使用して指定距離内の近傍をすべて探索
説明
例
各 Y 点のユークリッド距離 1.5 内にある X 点を求めます。X と Y はどちらも、5 次元正規分布変数の標本です。
rng('default') % For reproducibility X = randn(100,5); Y = randn(10,5); [Idx,D] = rangesearch(X,Y,1.5)
Idx=10×1 cell array
{[ 25 62 33 99 87 92 16]}
{[ 92 25]}
{[ 93 42 31 73 60 28 78 83 48 89 85]}
{[ 92 41]}
{[44 7 28 78 75 42 69 31 1 26 83 93]}
{[ 15 31 89 41 27 17 29 60 34]}
{[ 89]}
{1×0 double }
{1×0 double }
{1×0 double }
D=10×1 cell array
{[ 0.9546 1.0987 1.2730 1.3981 1.4140 1.4249 1.4822]}
{[ 1.4203 1.4558]}
{[ 0.7114 0.7552 1.0081 1.1324 1.1424 1.1637 1.2108 1.3824 1.3944 1.4116 1.4605]}
{[ 1.1244 1.4672]}
{[0.7863 0.9326 0.9773 1.0508 1.1722 1.1934 1.3218 1.3623 1.3869 1.3919 1.4814 1.4978]}
{[ 1.2824 1.2843 1.3342 1.3469 1.4154 1.4237 1.4625 1.4626 1.4744]}
{[ 1.1739]}
{1×0 double }
{1×0 double }
{1×0 double }
このケースでは、Y の最後の 3 つの点は、X のどの点からも距離が 1.5 より離れています。X(89,:) は Y(7,:) から距離が 1.1739 離れており、他の X の点はすべて Y(7,:) からの距離が 1.5 より離れています。X には、Y(5,:) からの距離が 1.5 以内である点が 12 個含まれています。
3 つの異なる多変量正規分布のそれぞれから、5000 個のランダムな点を生成します。無作為に生成した点が 3 つの異なるクラスターを形成する可能性が高くなるように、分布の平均をシフトします。
rng('default') % For reproducibility N = 5000; dist = 10; X = [mvnrnd([0 0],eye(2),N); mvnrnd(dist*[1 1],eye(2),N); mvnrnd(dist*[-1 -1],eye(2),N)];
X 内の各点について、その点から半径 dist 以内にある X 内の点を求めます。計算を高速化するため、最近傍のインデックスを並べ替えないように指定します。X 内の最初の点を選択し、その最近傍を求めます。
Idx = rangesearch(X,X,dist,'SortIndices',false);
x = X(1,:);
nearestPoints = X(Idx{1},:);x の最近傍ではない X 内の値を求めます。これらの点をある色で、x の最近傍を別の色で表示します。黒で塗りつぶした円で点 x にラベルを付けます。
nonNearestIdx = true(size(X,1),1);
nonNearestIdx(Idx{1}) = false;
scatter(X(nonNearestIdx,1),X(nonNearestIdx,2))
hold on
scatter(nearestPoints(:,1),nearestPoints(:,2))
scatter(x(1),x(2),'black','filled')
hold off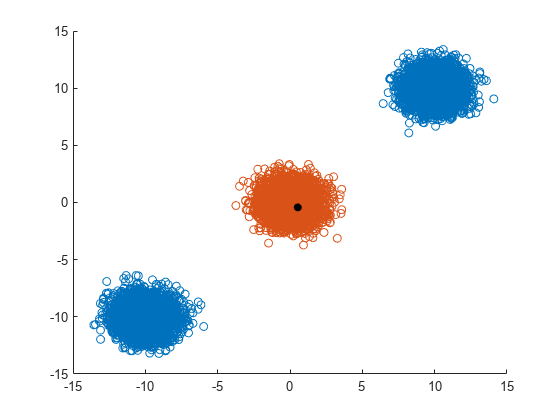
年齢および体重が Y 内の患者に対して特定の範囲内にある patients データ セット内の患者を求めます。
patients データ セットを読み込みます。Age の値の単位は年、Weight の値の単位はポンドです。
load patients X = [Age Weight]; Y = [20 162; 30 169; 40 168]; % New patients
年齢と体重に関する患者間の距離を決定するカスタム距離関数 distfun を作成します。distfun に従うと、たとえば、年齢が 1 年離れており体重が同じである 2 人の患者は、距離が 1 単位離れています。同様に、年齢が同じであり体重が 5 ポンド離れている 2 人の患者も、距離が 1 単位離れています。
type distfun.m % Display contents of distfun.m file
function D2 = distfun(ZI,ZJ) ageDifference = abs(ZI(1)-ZJ(:,1)); weightDifference = abs(ZI(2)-ZJ(:,2)); D2 = ageDifference + 0.2*weightDifference; end
メモ: この例の右上にあるボタンをクリックして MATLAB® で例を開くと、MATLAB は例のフォルダーを開きます。このフォルダーには、関数のファイル distfun.m が含まれています。
Y 内の患者に対する距離が 2 以内である X 内の患者を求めます。
[Idx,D] = rangesearch(X,Y,2,'Distance',@distfun)Idx=3×1 cell array
{1×0 double}
{1×0 double}
{[ 41]}
D=3×1 cell array
{1×0 double}
{1×0 double}
{[ 1.8000]}
距離が 2 以内である患者が X 内に存在するのは、Y 内の 3 番目の患者だけです。
年齢が 40、体重が 168 である患者に最も近い X 内の患者の Age と Weight の値を表示します。
X(Idx{3},:)ans = 1×2
39 164
入力引数
名前と値の引数
出力引数
ヒント
アルゴリズム
kd 木アルゴリズムの概要については、Kd 木を使用した k 最近傍探索を参照してください。
代替機能
関数 rangesearch の名前と値のペアの引数 'NSMethod' を適切な値 (網羅的探索アルゴリズムの場合は 'exhaustive'、Kd 木アルゴリズムの場合は 'kdtree') に設定した場合、オブジェクト関数 rangesearch を使用して距離探索を実行することにより得られる結果と同じ探索結果になります。関数 rangesearch とは異なり、オブジェクト関数 rangesearch では ExhaustiveSearcher または KDTreeSearcher モデル オブジェクトが必要です。
拡張機能
バージョン履歴
R2011b で導入
参考
createns | ExhaustiveSearcher | KDTreeSearcher | knnsearch | pdist2 | rangesearch