ランダム部分空間の分類
次の例は、ランダム部分空間アンサンブルを使用して分類の精度を向上させる方法を示しています。また、交差検証を使用して、弱学習器テンプレートとアンサンブルの両方に適切なパラメーターを判別する方法も示します。
データの読み込み
ionosphere データを読み込みます。このデータには 34 の予測子に対する 351 の二項反応が含まれます。
load ionosphere;
[N,D] = size(X)N = 351
D = 34
resp = unique(Y)
resp = 2×1 cell
{'b'}
{'g'}
最近傍の数の選択
交差検証を実行して、分類器における最近傍の数 k の適切な選択を見つけます。対数スケールでほぼ等間隔にある近傍の数を選択します。
rng(8000,'twister') % for reproducibility K = round(logspace(0,log10(N),10)); % number of neighbors cvloss = zeros(numel(K),1); for k=1:numel(K) knn = fitcknn(X,Y,... 'NumNeighbors',K(k),'CrossVal','On'); cvloss(k) = kfoldLoss(knn); end figure; % Plot the accuracy versus k semilogx(K,cvloss); xlabel('Number of nearest neighbors'); ylabel('10 fold classification error'); title('KNN classification');

交差検証の誤差が最小なのは、k = 2 の場合です。
アンサンブルの作成
さまざまな次元数をもつ 2 最近傍分類のアンサンブルを作成し、結果アンサンブルの交差検証損失を調べます。
この手順の実行には時間がかかります。進捗を追跡するには、各次元が終了するごとにメッセージを表示させます。
NPredToSample = round(linspace(1,D,10)); % linear spacing of dimensions cvloss = zeros(numel(NPredToSample),1); learner = templateKNN('NumNeighbors',2); for npred=1:numel(NPredToSample) subspace = fitcensemble(X,Y,'Method','Subspace','Learners',learner, ... 'NPredToSample',NPredToSample(npred),'CrossVal','On'); cvloss(npred) = kfoldLoss(subspace); fprintf('Random Subspace %i done.\n',npred); end
Random Subspace 1 done. Random Subspace 2 done. Random Subspace 3 done. Random Subspace 4 done. Random Subspace 5 done. Random Subspace 6 done. Random Subspace 7 done. Random Subspace 8 done. Random Subspace 9 done. Random Subspace 10 done.
figure; % plot the accuracy versus dimension plot(NPredToSample,cvloss); xlabel('Number of predictors selected at random'); ylabel('10 fold classification error'); title('KNN classification with Random Subspace');
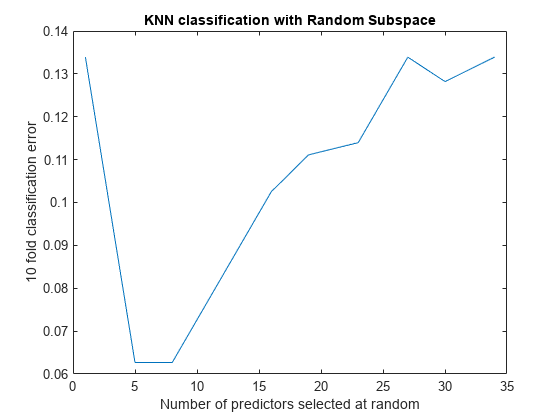
学習器ごとに 5 つの予測子があるアンサンブルと 8 つの予測子があるアンサンブルは、交差検証誤差が最も小さくなっています。これらのアンサンブルでは誤差率が約 0.06 ですが、他のアンサンブルでは交差検証誤差率が約 0.1 以上になっています。
適切なアンサンブル サイズの検出
アンサンブル内で最も数が少なく、なおかつ適切な分類が可能な学習器を求めます。
ens = fitcensemble(X,Y,'Method','Subspace','Learners',learner, ... 'NPredToSample',5,'CrossVal','on'); figure; % Plot the accuracy versus number in ensemble plot(kfoldLoss(ens,'Mode','Cumulative')) xlabel('Number of learners in ensemble'); ylabel('10 fold classification error'); title('KNN classification with Random Subspace');
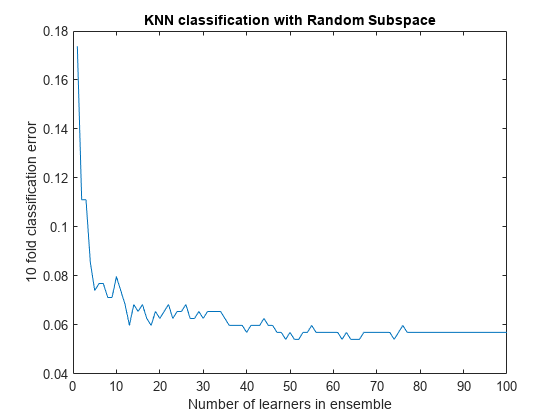
学習器が 50 を超えるアンサンブルには利点がないと考えられます。25 の学習器が含まれる場合に適正な予測ができる可能性があります。
最終的なアンサンブルの作成
50 の学習器を使用して最終的なアンサンブルを作成します。アンサンブルをコンパクト化し、コンパクト化したバージョンでそれなりのメモリ量が節約されるかどうかを確認します。
ens = fitcensemble(X,Y,'Method','Subspace','NumLearningCycles',50,... 'Learners',learner,'NPredToSample',5); cens = compact(ens); s1 = whos('ens'); s2 = whos('cens'); [s1.bytes s2.bytes] % si.bytes = size in bytes
ans = 1×2
1742840 1512100
コンパクトなアンサンブルは完全なアンサンブルに比べて約 10% 小さくなります。どちらの集合でも同じ予測が得られます。
参考
fitcknn | fitcensemble | kfoldLoss | templateKNN | compact