RegressionEnsemble Predict ブロックの使用による応答の予測
この例では、最適なハイパーパラメーターでアンサンブル モデルの学習を行い、RegressionEnsemble Predictブロックを Simulink® の応答予測に使用する方法を示します。このブロックは、観測値 (予測子データ) を受け入れて、学習済みのアンサンブル回帰モデルを使用することにより、その観測値の予測された応答を返します。
最適なハイパーパラメーターでの回帰モデルの学習
carbig データ セットを読み込みます。このデータ セットには、1970 年代と 1980 年代初期に製造された自動車の測定値が格納されています。
load carbig
whosName Size Bytes Class Attributes Acceleration 406x1 3248 double Cylinders 406x1 3248 double Displacement 406x1 3248 double Horsepower 406x1 3248 double MPG 406x1 3248 double Mfg 406x13 10556 char Model 406x36 29232 char Model_Year 406x1 3248 double Origin 406x7 5684 char Weight 406x1 3248 double cyl4 406x5 4060 char org 406x7 5684 char when 406x5 4060 char
Origin はカテゴリカル変数です。RegressionEnsemble Predict ブロックのモデルの学習を行う場合、カテゴリカル予測子をモデルに含めるには、関数 dummyvar を使用してカテゴリカル予測子を前処理しなければなりません。名前と値の引数 'CategoricalPredictors' は使用できません。Origin についてダミー変数を作成します。
c_Origin = categorical(cellstr(Origin)); d_Origin = dummyvar(c_Origin);
c_Origin の各カテゴリに対応するダミー変数が dummyvar で作成されます。c_Origin のカテゴリの数と d_Origin のダミー変数の数を調べます。
unique(cellstr(Origin))
ans = 7×1 cell
{'England'}
{'France' }
{'Germany'}
{'Italy' }
{'Japan' }
{'Sweden' }
{'USA' }
size(d_Origin)
ans = 1×2
406 7
Origin の各カテゴリに対応するダミー変数が dummyvar で作成されます。
6 つの数値予測子変数と Origin の 7 つのダミー変数を格納する行列を作成します。また、応答変数のベクトルを作成します。
X = [Acceleration,Cylinders,Displacement,Horsepower,Model_Year,Weight,d_Origin]; Y = MPG;
X および Y と次のオプションを使用してアンサンブルの学習を行います。
最適なハイパーパラメーターでアンサンブルの学習を行うために、
'OptimizeHyperparameters'を'auto'に指定します。'auto'オプションは、fitrensembleの'Method'、'NumLearningCycles'、および'LearnRate'(適用可能な手法) と木学習器の'MinLeafSize'について最適な値を探します。再現性を得るために、乱数シードを設定し、
'expected-improvement-plus'の獲得関数を使用します。また、ランダム フォレスト アルゴリズムの再現性を得るため、木学習器の'Reproducible'をtrueに指定します。
rng('default') t = templateTree('Reproducible',true); ensMdl = fitrensemble(X,Y,'Learners',t, ... 'OptimizeHyperparameters','auto', ... 'HyperparameterOptimizationOptions', ... struct('AcquisitionFunctionName','expected-improvement-plus'))
|===================================================================================================================================|
| Iter | Eval | Objective: | Objective | BestSoFar | BestSoFar | Method | NumLearningC-| LearnRate | MinLeafSize |
| | result | log(1+loss) | runtime | (observed) | (estim.) | | ycles | | |
|===================================================================================================================================|
| 1 | Best | 2.7403 | 1.3765 | 2.7403 | 2.7403 | Bag | 184 | - | 69 |
| 2 | Accept | 4.1317 | 0.20183 | 2.7403 | 2.8143 | Bag | 10 | - | 176 |
| 3 | Best | 2.1687 | 1.0696 | 2.1687 | 2.1689 | Bag | 118 | - | 2 |
| 4 | Accept | 2.2747 | 0.26303 | 2.1687 | 2.1688 | LSBoost | 24 | 0.37779 | 7 |
| 5 | Best | 2.1421 | 0.76329 | 2.1421 | 2.1422 | Bag | 75 | - | 1 |
| 6 | Best | 2.1365 | 4.85 | 2.1365 | 2.1365 | Bag | 500 | - | 1 |
| 7 | Accept | 2.4302 | 0.087353 | 2.1365 | 2.1365 | LSBoost | 37 | 0.94779 | 71 |
| 8 | Accept | 2.1813 | 1.4822 | 2.1365 | 2.1365 | LSBoost | 497 | 0.023582 | 1 |
| 9 | Accept | 6.1992 | 0.31409 | 2.1365 | 2.1363 | LSBoost | 91 | 0.0012439 | 1 |
| 10 | Accept | 2.2119 | 1.4782 | 2.1365 | 2.1363 | LSBoost | 497 | 0.087441 | 11 |
| 11 | Accept | 4.7782 | 0.073962 | 2.1365 | 2.1366 | LSBoost | 15 | 0.055744 | 1 |
| 12 | Accept | 2.3093 | 1.2804 | 2.1365 | 2.1366 | LSBoost | 493 | 0.39665 | 1 |
| 13 | Accept | 4.1304 | 0.1217 | 2.1365 | 2.1366 | LSBoost | 198 | 0.33031 | 201 |
| 14 | Accept | 2.595 | 0.077647 | 2.1365 | 2.1367 | LSBoost | 16 | 0.99848 | 1 |
| 15 | Accept | 2.6643 | 0.083333 | 2.1365 | 2.1363 | LSBoost | 25 | 0.97637 | 5 |
| 16 | Accept | 2.2388 | 0.05832 | 2.1365 | 2.1363 | LSBoost | 11 | 0.42205 | 1 |
| 17 | Accept | 4.1304 | 0.028928 | 2.1365 | 2.1789 | LSBoost | 19 | 0.79808 | 202 |
| 18 | Accept | 2.3399 | 0.22537 | 2.1365 | 2.1363 | LSBoost | 71 | 0.44856 | 1 |
| 19 | Accept | 2.7734 | 0.29145 | 2.1365 | 2.1394 | LSBoost | 107 | 0.020776 | 2 |
| 20 | Accept | 2.3204 | 2.055 | 2.1365 | 2.136 | Bag | 463 | - | 16 |
|===================================================================================================================================|
| Iter | Eval | Objective: | Objective | BestSoFar | BestSoFar | Method | NumLearningC-| LearnRate | MinLeafSize |
| | result | log(1+loss) | runtime | (observed) | (estim.) | | ycles | | |
|===================================================================================================================================|
| 21 | Accept | 2.2005 | 0.97649 | 2.1365 | 2.137 | LSBoost | 464 | 0.10107 | 10 |
| 22 | Accept | 2.479 | 0.086373 | 2.1365 | 2.136 | LSBoost | 40 | 0.93931 | 26 |
| 23 | Accept | 4.4432 | 0.03166 | 2.1365 | 2.1366 | LSBoost | 16 | 0.094719 | 189 |
| 24 | Accept | 2.2531 | 0.92824 | 2.1365 | 2.137 | LSBoost | 497 | 0.32798 | 5 |
| 25 | Accept | 2.158 | 0.80393 | 2.1365 | 2.1366 | LSBoost | 433 | 0.015137 | 1 |
| 26 | Accept | 2.6254 | 0.48985 | 2.1365 | 2.1369 | LSBoost | 467 | 0.94779 | 50 |
| 27 | Accept | 2.5612 | 0.039979 | 2.1365 | 2.1369 | LSBoost | 12 | 0.19061 | 17 |
| 28 | Accept | 2.256 | 0.049121 | 2.1365 | 2.1366 | LSBoost | 10 | 0.37427 | 2 |
| 29 | Accept | 2.2065 | 1.3604 | 2.1365 | 2.1366 | LSBoost | 499 | 0.018238 | 5 |
| 30 | Accept | 2.2539 | 0.11707 | 2.1365 | 2.1369 | Bag | 10 | - | 7 |
__________________________________________________________
Optimization completed.
MaxObjectiveEvaluations of 30 reached.
Total function evaluations: 30
Total elapsed time: 29.1513 seconds
Total objective function evaluation time: 21.0653
Best observed feasible point:
Method NumLearningCycles LearnRate MinLeafSize
______ _________________ _________ ___________
Bag 500 NaN 1
Observed objective function value = 2.1365
Estimated objective function value = 2.1369
Function evaluation time = 4.85
Best estimated feasible point (according to models):
Method NumLearningCycles LearnRate MinLeafSize
______ _________________ _________ ___________
Bag 500 NaN 1
Estimated objective function value = 2.1369
Estimated function evaluation time = 3.8853

ensMdl =
RegressionBaggedEnsemble
ResponseName: 'Y'
CategoricalPredictors: []
ResponseTransform: 'none'
NumObservations: 398
HyperparameterOptimizationResults: [1×1 classreg.learning.paramoptim.SupervisedLearningBayesianOptimization]
NumTrained: 500
Method: 'Bag'
LearnerNames: {'Tree'}
ReasonForTermination: 'Terminated normally after completing the requested number of training cycles.'
FitInfo: []
FitInfoDescription: 'None'
Regularization: []
FResample: 1
Replace: 1
UseObsForLearner: [398×500 logical]
Properties, Methods
fitrensemble は、ランダム フォレスト アルゴリズム ('Bag') が最適な手法であると特定し、RegressionBaggedEnsembleオブジェクトを返します。
Simulink モデルの作成
この例では、RegressionEnsemble Predictブロックを含む Simulink モデル slexCarDataRegressionEnsemblePredictExample.slx が用意されています。この節の説明に従って、この Simulink モデルを開くことも、新しいモデルを作成することもできます。
Simulink モデル slexCarDataRegressionEnsemblePredictExample.slx を開きます。
SimMdlName = 'slexCarDataRegressionEnsemblePredictExample';
open_system(SimMdlName)
Simulink モデルを開くと、Simulink モデルを読み込む前に、ソフトウェアがコールバック関数 PreLoadFcn のコードを実行します。slexCarDataRegressionEnsemblePredictExample のコールバック関数 PreLoadFcn には、学習済みモデルの変数 ensMdl がワークスペースにあるかどうかをチェックするコードが含まれています。ワークスペースに変数がない場合、PreLoadFcn は標本データを読み込み、最適なハイパーパラメーターを使用してモデルに学習させ、Simulink モデルの入力信号を作成します。コールバック関数を表示するには、[モデル化] タブの [設定] セクションで、[モデル設定] をクリックし、[モデル プロパティ] を選択します。次に、[コールバック] タブで、[モデルのコールバック] ペインのコールバック関数 PreLoadFcn を選択します。
新しい Simulink モデルを作成するには、[空のモデル] テンプレートを開き、RegressionEnsemble Predict ブロックを追加します。Inport ブロックと Outport ブロックを追加して、それらを RegressionEnsemble Predict ブロックに接続します。
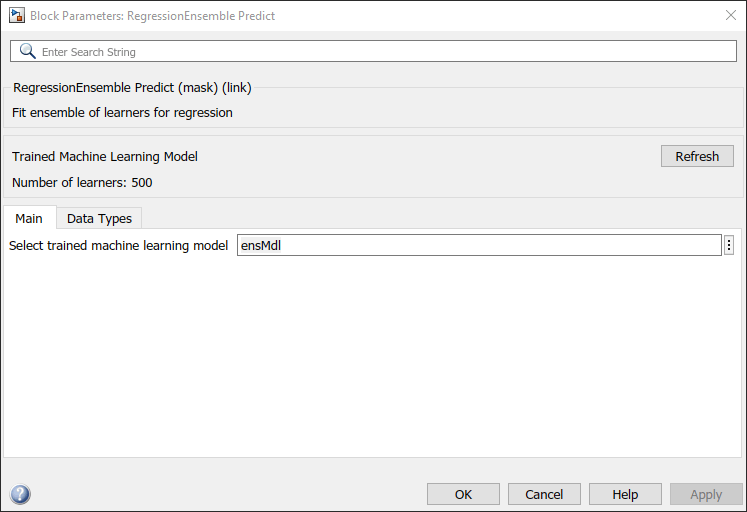
RegressionEnsemble Predict ブロックをダブルクリックして、[ブロック パラメーター] ダイアログ ボックスを開きます。[Select trained machine learning model] パラメーターを ensMdl として指定します。これは、学習済みのモデルを含むワークスペース変数の名前です。[リフレッシュ] ボタンをクリックします。ダイアログ ボックスの [Trained Machine Learning Model] に、モデル ensMdl の学習に使用されるオプションが表示されます。
RegressionEnsemble Predict ブロックには、13 個の予測子の値を含む観測値が必要です。Inport ブロックをダブルクリックし、[信号属性] タブで [端子の次元] を 13 に設定します。
Simulink モデルの構造体配列の形式で、入力信号を作成します。構造体配列には、次のフィールドが含まれていなければなりません。
time— 観測値がモデルに入力された時点。方向は予測子データ内の観測値に対応しなければなりません。したがって、この例の場合はtimeが列ベクトルでなければなりません。signals—valuesフィールドとdimensionsフィールドが含まれている、入力データを説明する 1 行 1 列の構造体配列。valuesは予測子データの行列、dimensionsは予測子変数の個数です。
carsmall データ セットから、slexCarDataRegressionEnsemblePredictExample モデルに適切な構造体配列を作成します。carsmall の Origin を categorical データ型配列 c_Origin_small に変換する際は、c_Origin と c_Origin_small に同じ数のカテゴリが同じ順序で含まれるように categories(c_Origin) を使用します。
load carsmall
c_Origin_small = categorical(cellstr(Origin),categories(c_Origin));
d_Origin_small = dummyvar(c_Origin_small);
testX = [Acceleration,Cylinders,Displacement,Horsepower,Model_Year,Weight,d_Origin_small];
testX = rmmissing(testX);
carsmallInput.time = (0:size(testX,1)-1)';
carsmallInput.signals(1).values = testX;
carsmallInput.signals(1).dimensions = size(testX,2);ワークスペースから信号データをインポートするには、次を実行します。
[コンフィギュレーション パラメーター] ダイアログ ボックスを開く。[モデル化] タブで、[モデル設定] をクリック。
[データのインポート/エクスポート] ペインで [入力] チェック ボックスをオンにし、隣のテキスト ボックスに
carsmallInputと入力。[ソルバー] ペインの [シミュレーション時間] で、[終了時間] を
carsmallInput.time(end)に設定。[ソルバーの選択] で、[タイプ] をFixed-stepに、[ソルバー] をdiscrete (no continuous states)に設定。
詳細は、シミュレーションのための信号データの読み込み (Simulink)を参照してください。
モデルをシミュレートします。
sim(SimMdlName);
Inport ブロックは観測値を検出すると、その観測値を RegressionEnsemble Predict ブロックに送ります。シミュレーション データ インスペクター (Simulink)を使用して、Outport ブロックのログ データを表示できます。