logp
インクリメンタル学習用の単純ベイズ分類モデルの対数条件なし確率密度
説明
例
fitcnb を使用して単純ベイズ分類モデルに学習させ、それをインクリメンタル学習器に変換してから、そのインクリメンタル モデルを使用してストリーミング データの外れ値を検出します。
データの読み込みと前処理
人の行動のデータ セットを読み込みます。データをランダムにシャッフルします。
load humanactivity rng(1); % For reproducibility n = numel(actid); idx = randsample(n,n); X = feat(idx,:); Y = actid(idx);
データ セットの詳細については、コマンド ラインで Description を入力してください。
単純ベイズ分類モデルの学習
単純ベイズ分類モデルをデータの約 25% の無作為標本に当てはめます。
idxtt = randsample([true false false false],n,true); TTMdl = fitcnb(X(idxtt,:),Y(idxtt))
TTMdl =
ClassificationNaiveBayes
ResponseName: 'Y'
CategoricalPredictors: []
ClassNames: [1 2 3 4 5]
ScoreTransform: 'none'
NumObservations: 6167
DistributionNames: {1×60 cell}
DistributionParameters: {5×60 cell}
Properties, Methods
TTMdl は、従来式の学習済みモデルを表す ClassificationNaiveBayes モデル オブジェクトです。
学習済みモデルの変換
従来式の学習済み分類モデルをインクリメンタル学習用の単純ベイズ分類モデルに変換します。
IncrementalMdl = incrementalLearner(TTMdl)
IncrementalMdl =
incrementalClassificationNaiveBayes
IsWarm: 1
Metrics: [1×2 table]
ClassNames: [1 2 3 4 5]
ScoreTransform: 'none'
DistributionNames: {1×60 cell}
DistributionParameters: {5×60 cell}
Properties, Methods
IncrementalMdl は incrementalClassificationNaiveBayes オブジェクトです。IncrementalMdl はインクリメンタル学習用の単純ベイズ分類モデルを表し、パラメーター値は TTMdl のパラメーターと同じです。
外れ値の検出
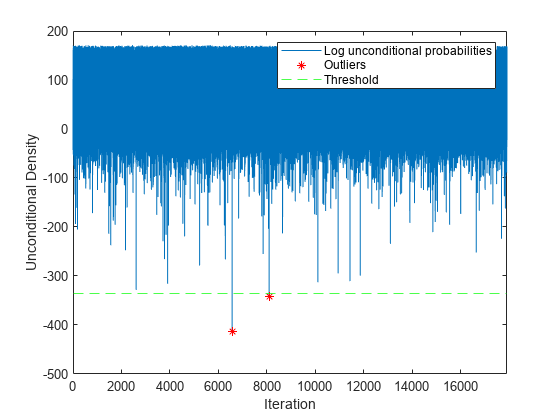
従来式の学習済みモデルと学習データを使用して、外れ値の条件なし密度のしきい値を調べます。外れ値は、密度がしきい値より小さいストリーミング データの観測値です。
ttlp = logp(TTMdl,X(idxtt,:)); [~,lower] = isoutlier(ttlp)
lower = -336.0424
残りのデータでこれらの外れ値を検出します。観測値を一度に 1 個ずつ処理して、データ ストリームをシミュレートします。各反復で logp を呼び出して観測値の対数条件なし確率密度を計算し、それぞれの値を保存します。
% Preallocation idxil = ~idxtt; nil = sum(idxil); numObsPerChunk = 1; nchunk = floor(nil/numObsPerChunk); lp = zeros(nchunk,1); iso = false(nchunk,1); Xil = X(idxil,:); Yil = Y(idxil); % Incremental processing for j = 1:nchunk ibegin = min(nil,numObsPerChunk*(j-1) + 1); iend = min(nil,numObsPerChunk*j); idx = ibegin:iend; lp(j) = logp(IncrementalMdl,Xil(idx,:)); iso(j) = lp(j) < lower; end
ストリーミング データの対数条件なし確率密度をプロットします。外れ値を特定します。
figure; h1 = plot(lp); hold on x = 1:nchunk; h2 = plot(x(iso),lp(iso),'r*'); h3 = yline(lower,'g--'); xlim([0 nchunk]); ylabel('Unconditional Density') xlabel('Iteration') legend([h1 h2 h3],["Log unconditional probabilities" "Outliers" "Threshold"]) hold off
入力引数
出力引数
詳細
バージョン履歴
R2021a で導入