random
ランダム ノイズがある応答を一般化線形回帰モデルに対するシミュレート
説明
例
一般化線形回帰モデルを作成し、新しいデータに対するランダム ノイズのある応答をシミュレートします。
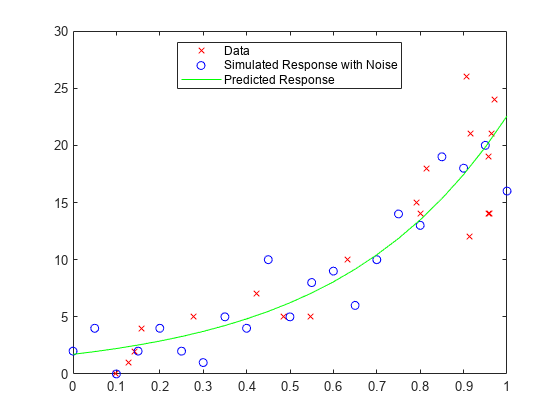
基となる 1 つの予測子 X をもつポアソン乱数を使って標本データを生成します。
rng('default') % For reproducibility X = rand(20,1); mu = exp(1 + 2*X); y = poissrnd(mu);
ポアソン データの一般化線形回帰モデルを作成します。
mdl = fitglm(X,y,'y ~ x1','Distribution','poisson');
予測に使用するデータ点を作成します。
Xnew = (0:.05:1)';
データ点でランダム ノイズがある応答をシミュレートします。
ysim = random(mdl,Xnew);
シミュレートされた値と元の値をプロットします。
plot(X,y,'rx',Xnew,ysim,'bo',Xnew,feval(mdl,Xnew),'g-') legend('Data','Simulated Response with Noise','Predicted Response', ... 'Location','best')
一般化線形回帰モデルを当てはめてから、saveLearnerForCoder を使用してモデルを保存します。loadLearnerForCoderを使用してモデルを読み込み、当てはめたモデルの関数 predict を呼び出す、エントリポイント関数を定義します。その後、codegen (MATLAB Coder) を使用して C/C++ コードを生成します。C/C++ コードの生成には MATLAB® Coder™ が必要であることに注意してください。
この例では、コマンド ラインで線形回帰モデルの予測を行うためのコード生成ワークフローについて簡単に説明します。詳細は、機械学習モデルの予測をコマンド ラインで行うコードの生成を参照してください。MATLAB Coder アプリを使用してコードを生成することもできます。詳細については、機械学習モデルの予測を MATLAB Coder アプリを使用して行うコードの生成を参照してください。
モデルの学習
次の分布で予測子 x および応答 y の標本データを生成します。
.
および
.
rng('default') % For reproducibility x = 1 + randn(100,1)*0.5; beta = -2; p = exp(1 + x*beta)./(1 + exp(1 + x*beta)); % Inverse logit n = 10; y = binornd(n,p,100,1);
二項データの一般化線形回帰モデルを作成します。二項標本サイズとして 10 を指定します。
mdl = fitglm(x,y,'y ~ x1','Distribution','Binomial','BinomialSize',n);
モデルの保存
当てはめた一般化線形回帰モデルを saveLearnerForCoder を使用して GLMMdl.mat というファイルに保存します。
saveLearnerForCoder(mdl,'GLMMdl');エントリポイント関数の定義
現在のフォルダーで、以下を行う myrandomGLM.m という名前のエントリポイント関数を定義します。
新しい予測子入力と、有効な名前と値のペアの引数を受け入れます。
GLMMdl.mat内の当てはめた一般化線形回帰モデルをloadLearnerForCoderを使用して読み込みます。読み込んだ GLM モデルから応答をシミュレートします。
function y = myrandomGLM(x,varargin) %#codegen %MYRANDOMGLM Simulate responses using GLM model % MYRANDOMGLM simulates responses for the n observations in the n-by-1 % vector x using the GLM model stored in the MAT-file GLMMdl.mat, and % then returns the simulations in the n-by-1 vector y. CompactMdl = loadLearnerForCoder('GLMMdl'); narginchk(1,Inf); y = random(CompactMdl,x,varargin{:}); end
MATLAB のアルゴリズムについてのコードを生成しようとしていることを指示するため、コンパイラ命令 %#codegen (またはプラグマ) をエントリポイント関数のシグネチャの後に追加します。この命令を追加すると、MATLAB Code Analyzer はコード生成時にエラーになる違反の診断と修正を支援します。
コードの生成
codegen (MATLAB Coder) を使用して、エントリポイント関数のコードを生成します。C および C++ は静的な型の言語なので、エントリポイント関数内のすべての変数のプロパティをコンパイル時に決定しなければなりません。データ型と正確な入力配列のサイズを指定するため、特定のデータ型および配列サイズをもつ一連の値を表す MATLAB® 式を渡します。名前と値のペアの引数の名前に対してcoder.Constant (MATLAB Coder)を使用します。
予測子データ x と二項パラメーター n を指定します。
codegen -config:mex myrandomGLM -args {x,coder.Constant('BinomialSize'),coder.Constant(n)}
Code generation successful.
codegen は、プラットフォームに依存する拡張子をもつ MEX 関数 myrandomGLM_mex を生成します。
コンパイル時に観測値の個数が不明である場合、coder.typeof (MATLAB Coder) を使用して可変サイズの入力を指定することもできます。詳細は、機械学習モデルのコード生成用の可変サイズ引数の指定 と エントリポイント関数の入力の型の指定 (MATLAB Coder) を参照してください。
生成されたコードの確認
MEX 関数を使用して応答をシミュレートします。予測子データ x と二項パラメーター n を指定します。
ysim = myrandomGLM_mex(x,'BinomialSize',n);シミュレートした値とデータを同じ Figure にプロットします。
figure plot(x,y,'bo',x,ysim,'r*') legend('Observed responses','Simulated responses') xlabel('x') ylabel('y')

観測された応答とシミュレートされた応答は、同じ分布になっているように見えます。
入力引数
名前と値の引数
出力引数
代替機能
ランダム ノイズのない予測では、predict または feval を使用します。
predictは、すべての予測子変数を格納する単一の入力引数を受け入れ、予測に対する信頼区間を返します。fevalは、各予測子変数に 1 つの入力が対応する複数の入力引数を受け入れます。table またはデータセット配列から作成したモデルの場合、この関数をより簡単に使用できます。関数fevalは、名前と値のペアの引数'Offset'および'BinomialSize'をサポートしていません。この関数は、オフセット値として 0 を使用し、出力値は予測確率です。
拡張機能
バージョン履歴
R2012a で導入