factoran
因子分析
構文
説明
factoran は、因子分析モデルの因子負荷量行列 Λ の最尤推定 (MLE) を計算します。
ここで、x は観測変数のベクトル、μ は平均の定数ベクトル、Λ は因子負荷量の d 行 m 列の定数行列、f は標準化した独立共通因子のベクトル、e は独立した特殊因子のベクトルです。x、μ、および e の長さは d です。f の長さは m です。
あるいは、因子分析モデルは次のように指定することができます。
ここで、 は独自因子の分散から構成される d 行 d 列の対角行列です。
factoran の使用、およびその pca との関連性については、試験の成績に対する因子分析の実行を参照してください。
___ = factoran( は、前の構文の出力引数について、1 つ以上の名前と値のペアの引数を使用して、モデルの当てはめと出力を変更します。たとえば、X,m,Name,Value)X のデータが共分散行列であると指定できます。
例
いくつかの疑似ランダム生データを作成します。
rng default % For reproducibility n = 100; X1 = 5 + 3*rand(n,1); % Factor 1 X2 = 20 - 5*rand(n,1); % Factor 2
生データから 6 つのデータ ベクトルを作成し、ランダム ノイズを追加します。
Y1 = 2*X1 + 3*X2 + randn(n,1); Y2 = 4*X1 + X2 + 2*randn(n,1); Y3 = X1 - X2 + 3*randn(n,1); Y4 = -2*X1 + 4*X2 + 4*randn(n,1); Y5 = 3*(X1 + X2) + 5*randn(n,1); Y6 = X1 - X2/2 + 6*randn(n,1);
データ ベクトルからデータ行列を作成します。
X = [Y1,Y2,Y3,Y4,Y5,Y6];
factoran を使用してノイズのあるデータ行列 X から 2 つの因子を抽出します。出力を表示します。
m = 2; [lambda,psi,T,stats,F] = factoran(X,m); disp(lambda)
0.8666 0.4828
0.8688 -0.0998
-0.0131 -0.5412
0.2150 0.8458
0.7040 0.2678
-0.0806 -0.2883
disp(psi)
0.0159
0.2352
0.7070
0.2385
0.4327
0.9104
disp(T)
0.8728 0.4880
0.4880 -0.8728
disp(stats)
loglike: -0.0531
dfe: 4
chisq: 5.0335
p: 0.2839
disp(F(1:10,:))
1.8845 -0.6568
-0.1714 -0.8113
-1.0534 2.0743
1.0390 -1.1784
0.4309 0.9907
-1.1823 0.6570
-0.2129 1.1898
-0.0844 -0.7421
0.5854 -1.1379
0.8279 -1.9624
データの相関行列を表示します。
corrX = corr(X)
corrX = 6×6
1.0000 0.7047 -0.2710 0.5947 0.7391 -0.2126
0.7047 1.0000 0.0203 0.1032 0.5876 0.0289
-0.2710 0.0203 1.0000 -0.4793 -0.1495 0.1450
0.5947 0.1032 -0.4793 1.0000 0.3752 -0.2134
0.7391 0.5876 -0.1495 0.3752 1.0000 -0.2030
-0.2126 0.0289 0.1450 -0.2134 -0.2030 1.0000
corrX を、factoran によって返された対応する値 lambda*lambda' + diag(psi) と比較します。
C0 = lambda*lambda' + diag(psi)
C0 = 6×6
1.0000 0.7047 -0.2726 0.5946 0.7394 -0.2091
0.7047 1.0000 0.0426 0.1023 0.5849 -0.0413
-0.2726 0.0426 1.0000 -0.4605 -0.1542 0.1571
0.5946 0.1023 -0.4605 1.0000 0.3779 -0.2611
0.7394 0.5849 -0.1542 0.3779 1.0000 -0.1340
-0.2091 -0.0413 0.1571 -0.2611 -0.1340 1.0000
factoran は、元のデータの相関行列に密接に対応する lambda と psi を取得します。
回転を使用せずに結果を表示します。
[lambda,psi,T,stats,F] = factoran(X,m,'Rotate','none'); disp(lambda)
0.9920 0.0015
0.7096 0.5111
-0.2755 0.4659
0.6004 -0.6333
0.7452 0.1098
-0.2111 0.2123
disp(psi)
0.0159
0.2352
0.7070
0.2385
0.4327
0.9104
disp(T)
1 0
0 1
disp(stats)
loglike: -0.0531
dfe: 4
chisq: 5.0335
p: 0.2839
disp(F(1:10,:))
1.3243 1.4929
-0.5456 0.6245
0.0928 -2.3246
0.3318 1.5356
0.8596 -0.6544
-0.7114 -1.1504
0.3947 -1.1424
-0.4358 0.6065
-0.0444 1.2789
-0.2350 2.1169
X の共分散行列のみを使用して因子を計算します。
X2 = cov(X); [lambda2,psi2,T2,stats2] = factoran(X2,m,'Xtype','covariance','Nobs',n)
lambda2 = 6×2
0.8666 0.4828
0.8688 -0.0998
-0.0131 -0.5412
0.2150 0.8458
0.7040 0.2678
-0.0806 -0.2883
psi2 = 6×1
0.0159
0.2352
0.7070
0.2385
0.4327
0.9104
T2 = 2×2
0.8728 0.4880
0.4880 -0.8728
stats2 = struct with fields:
loglike: -0.0531
dfe: 4
chisq: 5.0335
p: 0.2839
結果は生のデータを使用した場合と同じになりますが、factoran 以外は共分散データの因子スコア行列 F を計算することができません。
標本データを読み込みます。
load carbig可変行列を定義し、欠損値を含む観測値を削除します。
X = [Acceleration Displacement Horsepower MPG Weight]; X = X(all(~isnan(X),2),:);
2 つの共通因子による因子分析で、最小平均二乗誤差予測を使用して、因子負荷量を推定します。リッジ回帰モデルを使用して因子スコアを予測するように指定します。
[Lambda,Psi,T,~,F] = factoran(X,2,Scores="regression")Lambda = 5×2
-0.2432 -0.8500
0.8773 0.3871
0.7618 0.5930
-0.7978 -0.2786
0.9692 0.2129
Psi = 5×1
0.2184
0.0804
0.0680
0.2859
0.0152
T = 2×2
0.9476 0.3195
0.3195 -0.9476
F = 392×2
0.4568 0.9158
0.5897 1.6438
0.2573 1.6383
0.3108 1.4154
0.2700 1.4815
1.2534 2.0922
1.1607 2.7986
1.0866 2.8106
1.2923 2.6269
0.5558 2.6860
0.3443 2.2636
0.2945 2.3158
0.6351 1.7573
-0.3769 4.1067
-0.8074 0.4072
⋮
因子分析モデルでは、 であり、 の要素が独自因子の分散であると仮定されます。
因子スコア (F) の推定共分散行列を計算します。
inv(T'*T) % Estimated covariance matrix of Fans = 2×2
1.0000 0
0 1.0000
factoran の既定の回転方法は varimax であるため、T は直交行列で、F の推定共分散行列は単位行列です。
因子分析モデルを使用して X の推定共分散行列を計算します。
Lambda*Lambda' + diag(Psi) % Estimated covariance matrix of Xans = 5×5
1.0000 -0.5424 -0.6893 0.4309 -0.4167
-0.5424 1.0000 0.8979 -0.8078 0.9328
-0.6893 0.8979 1.0000 -0.7730 0.8647
0.4309 -0.8078 -0.7730 1.0000 -0.8326
-0.4167 0.9328 0.8647 -0.8326 1.0000
に主軸回転行列を乗算することで、回転していない因子負荷量を計算します。
Lambda*inv(T) % Unrotate the loadingsans = 5×2
-0.5020 0.7277
0.9550 -0.0865
0.9113 -0.3185
-0.8450 0.0091
0.9865 0.1079
F に T' を乗算することで、回転していない因子スコアを計算します。
F*T' % Unrotate the factor scoresans = 392×2
0.7255 -0.7219
1.0840 -1.3692
0.7673 -1.4702
0.7467 -1.2419
0.7292 -1.3176
1.8562 -1.5820
1.9940 -2.2811
1.9276 -2.3161
2.0638 -2.0764
1.3848 -2.3676
1.0494 -2.0349
1.0190 -2.1003
1.1633 -1.4622
0.9549 -4.0119
-0.6349 -0.6438
⋮
2 つの因子のバイプロットを作成します。
biplot(Lambda,LineWidth=2,MarkerSize=20)
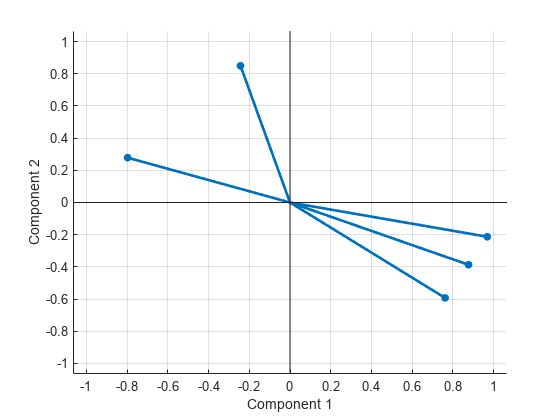
共分散 (または相関) 行列を使用して因子負荷量を推定します。
[Lambda,Psi,T] = factoran(cov(X),2,Xtype="covariance")Lambda = 5×2
-0.2432 -0.8500
0.8773 0.3871
0.7618 0.5930
-0.7978 -0.2786
0.9692 0.2129
Psi = 5×1
0.2184
0.0804
0.0680
0.2859
0.0152
T = 2×2
0.9476 0.3195
0.3195 -0.9476
cov(X) の代わりに corrcoef(X) を使用して factoran のデータを作成することもできます。
推定値は同じですが、生データではなく共分散行列を使用することで、スコアや有意水準が不要になります。
プロマックス法を使用して因子とスコアを回転します。
[Lambda,Psi,T,stats,F] = factoran(X,2,Rotate="promax"); inv(T'*T) % Estimated covariance matrix of F, no longer eye(2)
ans = 2×2
1.0000 -0.6391
-0.6391 1.0000
Lambda*inv(T'*T)*Lambda'+diag(Psi) % Estimated covariance matrix of Xans = 5×5
1.0000 -0.5424 -0.6893 0.4309 -0.4167
-0.5424 1.0000 0.8979 -0.8078 0.9328
-0.6893 0.8979 1.0000 -0.7730 0.8647
0.4309 -0.8078 -0.7730 1.0000 -0.8326
-0.4167 0.9328 0.8647 -0.8326 1.0000
斜交軸を重ね合わせて表示し、回転していない変数をプロットします。
invT = inv(T); Lambda0 = Lambda*invT; figure() line([-invT(1,1) invT(1,1) NaN -invT(2,1) invT(2,1)], ... [-invT(1,2) invT(1,2) NaN -invT(2,2) invT(2,2)], ... Color="b",LineWidth=2) grid on hold on biplot(Lambda0,LineWidth=2,MarkerSize=20) xlabel("Loadings for Unrotated Factor 1") ylabel("Loadings for Unrotated Factor 2")
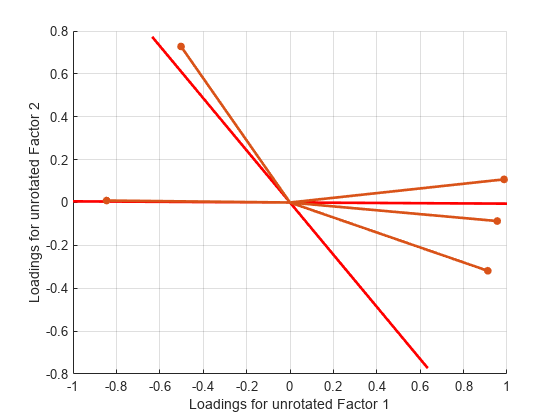
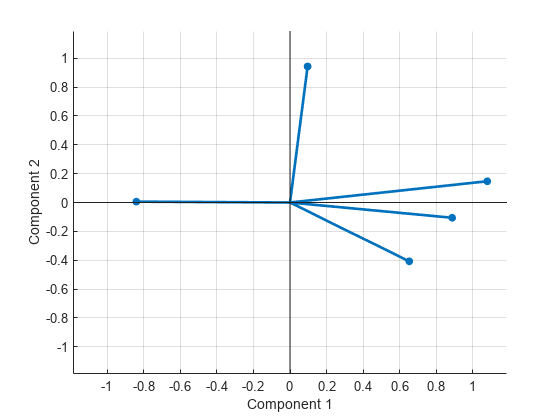
斜交軸に対して回転される変数をプロットします。
figure() biplot(Lambda,LineWidth=2,MarkerSize=20)
入力引数
名前と値の引数
出力引数
詳細
参照
[1] Harman, Harry Horace. Modern Factor Analysis. 3rd Ed. Chicago: University of Chicago Press, 1976.
[2] Jöreskog, K. G. “Some Contributions to Maximum Likelihood Factor Analysis.” Psychometrika 32, no. 4 (December 1967): 443–82. https://doi.org/10.1007/BF02289658
[3] Krzanowski, W. J. Principles of Multivariate Analysis: A User's Perspective. New York: Oxford University Press, 1988.
[4] Lawley, D. N., and A. E. Maxwell. Factor Analysis as a Statistical Method. 2nd Ed. New York: American Elsevier Publishing Co., 1971.
拡張機能
pcacov と factoran では、tall 配列を直接操作することはできません。代わりに、C = gather(cov(X)) を使用して tall 配列の共分散行列を計算します。このようにすると、インメモリの共分散行列で処理するために、pcacov または factoran を使用できます。または、pca を tall 配列に対して直接使用できます。

詳細は、メモリに収まらないデータの tall 配列を参照してください。
バージョン履歴
R2006a より前に導入