CalinskiHarabaszEvaluation
Calinski-Harabasz 基準クラスタリング評価オブジェクト
説明
CalinskiHarabaszEvaluation は、最適なクラスター数 (OptimalK) を評価するために使用される標本データ (X)、クラスタリング データ (OptimalY)、および Calinski-Harabasz 基準値 (CriterionValues) で構成されるオブジェクトです。Calinski-Harabasz 基準は分散比基準 (VRC) と呼ばれる場合もあります。適切に定義されたクラスターでは、クラスター間の分散は大きくなり、クラスター内の分散は小さくなります。最適なクラスターの数は、最も大きな Calinski-Harabasz インデックス値をもつ解に対応します。詳細は、Calinski-Harabasz 基準を参照してください。
作成
Calinski-Harabasz 基準クラスタリング評価オブジェクトを作成するには、関数 evalclusters を使用し、基準を "CalinskiHarabasz" と指定します。
その後、compact を使用して、コンパクトなバージョンの Calinski-Harabasz 基準クラスタリング評価オブジェクトを作成できます。この関数は、プロパティ X、OptimalY、および Missing の内容を削除します。
プロパティ
例
Calinski-Harabasz クラスタリング評価基準を使用して最適なクラスター数を評価します。
fisheriris データ セットを読み込みます。このデータには、3 種のアヤメの花のがく片と花弁からの長さと幅の測定値が含まれています。
load fisheririsCalinski-Harabasz 基準を使用して最適なクラスター数を評価します。データのクラスタリングには kmeans を使用します。
rng("default") % For reproducibility evaluation = evalclusters(meas,"kmeans","CalinskiHarabasz","KList",1:6)
evaluation =
CalinskiHarabaszEvaluation with properties:
NumObservations: 150
InspectedK: [1 2 3 4 5 6]
CriterionValues: [NaN 513.9245 561.6278 530.4871 456.1279 469.5068]
OptimalK: 3
Properties, Methods
OptimalK の値は、Calinski-Harabasz 基準に基づく最適なクラスター数が 3 つであることを示しています。
テストした各クラスター数について、Calinski-Harabasz 基準値をプロットします。
plot(evaluation)
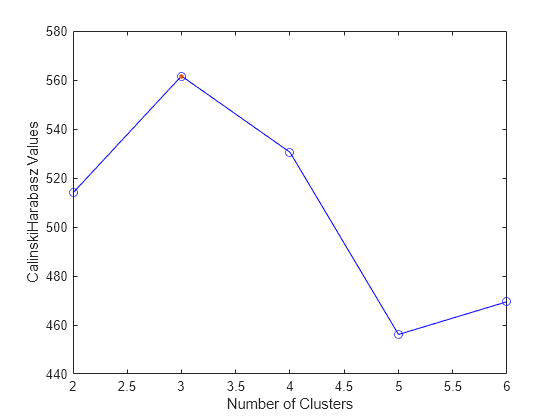
このプロットは Calinski-Harabasz の最大値が 3 個のクラスターのときに発生することを示しており、最適なクラスター数が 3 であることを示唆しています。
グループ化した散布図を作成して花弁の長さと幅の関係を調べます。データは推奨されるクラスターごとにグループ化します。
PetalLength = meas(:,3);
PetalWidth = meas(:,4);
clusters = evaluation.OptimalY;
gscatter(PetalLength,PetalWidth,clusters,[],"xod");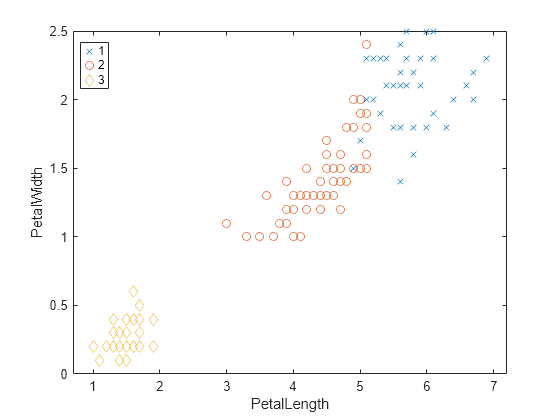
このプロットは、左下のクラスター 3 が他の 2 つのクラスターから完全に分離されていることを示しています。クラスター 3 には花弁の幅と長さが最も小さい花が含まれています。クラスター 1 は右上にあり、花弁の幅と長さが最も大きい花が含まれています。クラスター 2 はプロットの中央近くにあり、これら 2 つの極値の間にある測定値の花が含まれています。
詳細
参照
[1] Calinski, T., and J. Harabasz. “A dendrite method for cluster analysis.” Communications in Statistics. Vol. 3, No. 1, 1974, pp. 1–27.
バージョン履歴
R2013b で導入