このページの内容は最新ではありません。最新版の英語を参照するには、ここをクリックします。
産業機械と製造工程の条件モデルの作成
この例では、産業製造機械から収集されたセンサー データの条件モデルを作成します。分類学習器アプリを使用して、機械の条件を "保守後" または "保守前" と判別するバイナリ分類モデルを作成します。定期保守の直前と直後の両方で収集されたデータを使用してモデルに学習させます。定期保守の後に収集されたデータは正常な観測値を表し、保守前に収集されたデータは異常を表すと仮定します。学習済みモデルを使用して入力観測値を監視し、観測値の異常を検出することで新しい保守サイクルが必要かどうかを判断できます。
この例の分類ワークフローは次の手順で構成されます。
データを MATLAB® のワークスペースに読み込みます。
分類学習器アプリにデータをインポートし、一定の割合のデータをテスト用に確保します。
センサー データの異常を検出できるバイナリ分類モデルに学習させます。データ セット内のすべての特徴を使用します。
検証データでのモデルの精度を使用してモデルの性能を評価します。
アプリ セッションを中断し、モデルが分類タスクに指定されたリソース内のターゲット ハードウェアに収まるかどうかなど、モデル展開の側面について調べます。
アプリ セッションを再開し、サイズを縮小した新しいモデルを作成します。モデルのサイズを縮小するには、特徴のランク付けを使用して特徴を選択した後にモデルに学習させます。
最終モデルを選択し、テスト セットでその精度を確認します。
最終モデルをターゲット ハードウェアへの展開用にエクスポートします。
データの読み込み
この例では、産業機械の 3 軸振動測定値から抽出された 12 個の特徴を含むデータ セットを使用します。次のコマンドを実行し、データ セット ファイルをダウンロードして解凍します。
url = "https://ssd.mathworks.com/supportfiles/predmaint/" + ... "anomalyDetection3axisVibration/v1/vibrationData.zip"; outfilename = websave("vibrationData.zip",url); unzip(outfilename)
FeatureEntire.mat ファイル内の featureAll table を読み込みます。
load("FeatureEntire.mat")この table には、13 個の変数 (1 個のカテゴリカル応答変数と 12 個の予測子変数) に対する 17,642 個の観測値が含まれています。
冗長な語句 ("_stats/Col1_") を削除して予測子変数名を短くします。
for i = 2:13 featureAll.Properties.VariableNames(i) = ... erase(featureAll.Properties.VariableNames(i),"_stats/Col1_"); end
table の最初の 8 行をプレビューします。
head(featureAll)
ans=8×13 table
label ch1CrestFactor ch1Kurtosis ch1RMS ch1Std ch2Mean ch2RMS ch2Skewness ch2Std ch3CrestFactor ch3SINAD ch3SNR ch3THD
______ ______________ ___________ ______ ______ __________ _______ ___________ _______ ______________ ________ _______ _______
Before 2.3683 1.927 2.2225 2.2225 -0.015149 0.62512 4.2931 0.62495 5.6569 -5.4476 -4.9977 -4.4608
Before 2.402 1.9206 2.1807 2.1803 -0.018269 0.56773 3.9985 0.56744 8.7481 -12.532 -12.419 -3.2353
Before 2.4157 1.9523 2.1789 2.1788 -0.0063652 0.45646 2.8886 0.45642 8.3111 -12.977 -12.869 -2.9591
Before 2.4595 1.8205 2.14 2.1401 0.0017307 0.41418 2.0635 0.41418 7.2318 -13.566 -13.468 -2.7944
Before 2.2502 1.8609 2.3391 2.339 -0.0081829 0.3694 3.3498 0.36931 6.8134 -13.33 -13.225 -2.7182
Before 2.4211 2.2479 2.1286 2.1285 0.011139 0.36638 1.8602 0.36621 7.4712 -13.324 -13.226 -3.0313
Before 3.3111 4.0304 1.5896 1.5896 -0.0080759 0.47218 2.1132 0.47211 8.2412 -13.85 -13.758 -2.7822
Before 2.2655 2.0656 2.3233 2.3233 -0.0049447 0.37829 2.4936 0.37827 7.6947 -13.781 -13.683 -2.5601
1 列目の値は観測値のラベル Before または After で、これらはそれぞれ、各観測値が定期保守の直前と直後のどちらで収集されたかを示します。残りの列には、Predictive Maintenance Toolbox™ の診断特徴デザイナー アプリを使用して振動測定値から抽出された 12 個の特徴が含まれています。抽出された特徴の詳細については、3 軸振動データを使用した産業機械の異常の検出 (Predictive Maintenance Toolbox)を参照してください。
アプリへのデータのインポートとデータの分割
featureAll table を分類学習器アプリにインポートし、データの 10% をテスト セットとして確保します。
[アプリ] タブで [さらに表示] 矢印をクリックしてアプリ ギャラリーを表示します。[機械学習および深層学習] グループの [分類学習器] をクリックします。
[学習] タブの [ファイル] セクションで、[新規セッション]、[ワークスペースから] をクリックします。

[ワークスペースからの新規セッション] ダイアログ ボックスで、[データ セット変数] のリストから table
featureAllを選択します。データ型に基づいて応答変数 (label) および予測子変数 (12 個の特徴) が選択されます。[テスト] セクションで、[テスト データ セットの確保] チェック ボックスをクリックします。インポートされたデータの 10% をテスト セットとして使用するように指定します。
featureAlltable には 17,642 個の標本が含まれているため、10% を確保するとテスト セットの標本は 1764 個、学習セットの標本は 15,878 個になります。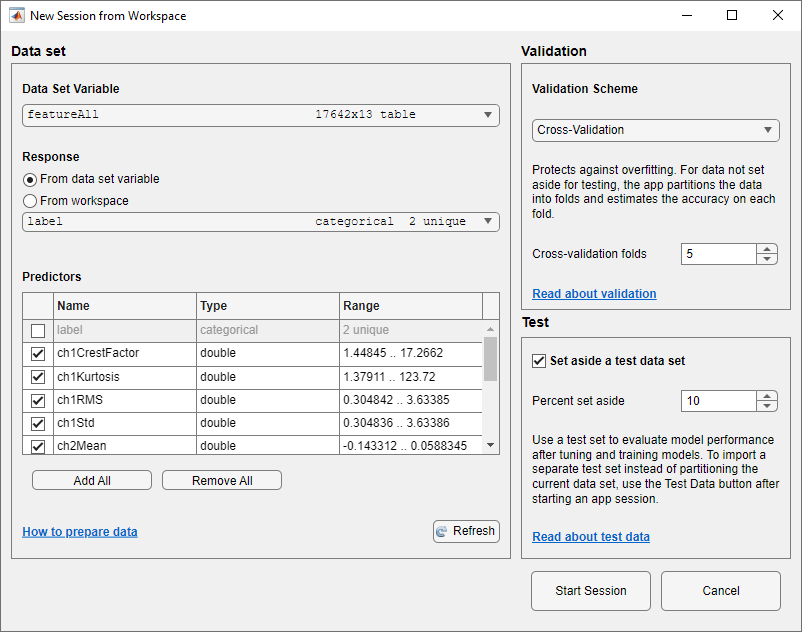
既定の検証方式をそのまま使用して続行するため、[セッションの開始] をクリックします。既定の検証オプションは 5 分割交差検証であるため、過適合が防止されます。
あるいは、MATLAB コマンド ウィンドウから「classificationLearner」と入力して分類学習器アプリを開くこともできます。予測子データ、応答変数、およびテスト用に確保するデータの割合を指定できます。
classificationLearner(featureAll,"label",TestDataFraction=0.1)すべての特徴を使用したモデルの学習
まず、データ セット内の 12 個すべての特徴を使用してモデルに学習させます。[モデル] ペインには複雑な木のモデルのドラフトが既に含まれています。[モデル] ギャラリーからドラフト モデルを選択して [モデル] ペインにさまざまなドラフト モデルを追加し、すべてのモデルに学習させることができます。
[学習] タブの [モデル] セクションで [さらに表示] 矢印をクリックしてギャラリーを開きます。
次の 3 つのモデルを選択します。
[アンサンブル分類器] グループで [バギング木] をクリックします。
[サポート ベクター マシン] グループで [細かいガウス SVM] をクリックします。
[ニューラル ネットワーク分類器] グループで [2 層ニューラル ネットワーク] をクリックします。
[モデル] ペインにドラフト モデルが含まれます。

各分類器オプションの詳細については、分類器のオプションの選択を参照してください。
[学習] タブの [学習] セクションで、[すべてを学習] をクリックして [すべてを学習] を選択します。12 個すべての特徴を使用して 4 つのモデルの学習が行われます。
メモ
Parallel Computing Toolbox™ がある場合は、[並列の使用] ボタンが既定でオンになります。[すべてを学習] をクリックして [すべてを学習] または [選択を学習] を選択すると、ワーカーの並列プールが開きます。この間、ソフトウェアの対話的な操作はできません。プールが開いた後、モデルの学習を並列で実行しながらアプリの操作を続けることができます。
Parallel Computing Toolbox がない場合は、[すべてを学習] メニューの [バックグラウンド学習を使用] チェック ボックスが既定でオンになります。オプションを選択してモデルに学習させると、バックグラウンド プールが開きます。プールが開いた後、モデルの学習をバックグラウンドで実行しながらアプリの操作を続けることができます。
モデルの性能評価
複数の特性に基づいて学習済みモデルを比較できます。たとえば、モデルの精度、モデルのサイズ (メモリまたはディスク ストレージのニーズに影響する)、モデルの学習とテストに関連する計算コスト、モデルの解釈可能性を評価できます。
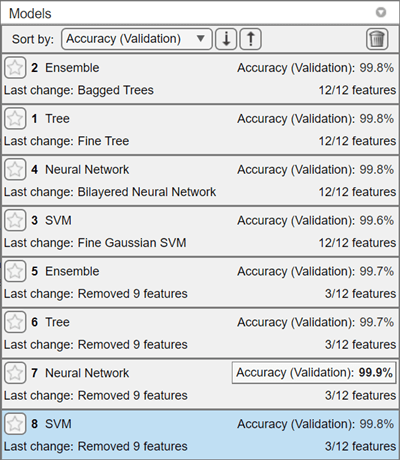
検証データで測定されたモデルの精度に基づいて 4 つの学習済みモデルを比較します。
[モデル] ペインに、各モデルの正しく予測された応答の割合を示す検証精度のスコアがあります。
メモ
検証により、結果に無作為性が導入されます。実際のモデルの検証結果は、この例に示されている結果と異なる場合があります。
検証精度に基づいて学習済みモデルを並べ替えます。[モデル] ペインで [並べ替え] 矢印をクリックし、
[精度 (検証)]を選択します。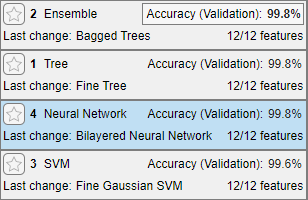
モデルのうち 3 つは検証精度について同じ割合を共有していますが、有効桁数 3 桁で表示すると、アンサンブル モデルが小さいマージンで最も高い精度を達成しています。アンサンブル モデルの精度スコアが縁取りで強調表示され、モデルを検証精度で並べ替えるとアンサンブル モデルが最初に表示されます。
結果について理解を深めるために、プロットのレイアウトを再編成して、4 つのモデルの混同行列を比較できるようにします。モデル プロットのタブの右端にある [ドキュメント アクション] ボタンをクリックします。
[すべて並べて表示]オプションを選択し、2 行 2 列のレイアウトを指定します。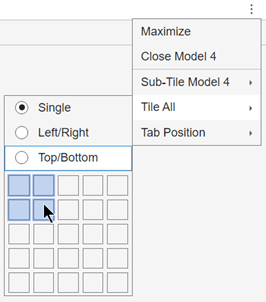
各プロットの右上で [プロット オプションを非表示] ボタン
 をクリックして、プロットのスペースを大きくします。
をクリックして、プロットのスペースを大きくします。
他のモデルに比べ、アンサンブル モデル (モデル 2) では、誤って分類された観測値に対応する対角線外のセルが少なくなっています。
モデルの性能評価の詳細については、分類学習器における分類器の性能の可視化と評価を参照してください。
ワークスペースへのモデルのエクスポートとアプリ セッションの保存
最適なモデルをワークスペースにエクスポートし、モデルのサイズを確認します。
[モデル] ペインでアンサンブル モデルをクリックして選択します。
[学習] タブの [エクスポート] セクションで、[モデルのエクスポート] をクリックして [モデルをワークスペースにエクスポート] を選択します。[分類モデルのエクスポート] ダイアログ ボックスでチェック ボックスをクリアして、エクスポートするモデルから学習データを除外します。コンパクトなモデルも新しいデータの予測に使用できます。
メモ
分類学習器がエクスポートする最終的なモデルの学習には、常にテスト用に確保されたデータを除くデータ セット全体が使用されます。使用する検証方式は、アプリによる検証メトリクスの計算方法のみに影響を与えます。
必要な場合は、エクスポートする変数の名前を [分類モデルのエクスポート] ダイアログ ボックスで編集します。[OK] をクリックします。エクスポートされた既存のモデルが上書きされないようにするため、エクスポートするモデルの既定名
trainedModelは、エクスポートを行うたびにインクリメントされます (trainedModel1など)。新しい変数
trainedModelがワークスペースに表示されます。現在のアプリ セッションを保存して閉じます。[学習] タブの [ファイル] セクションで [保存] をクリックします。セッション ファイルの名前と場所を指定し、アプリを閉じます。
モデルのサイズの確認
コマンド ウィンドウで関数 whos を使用して、エクスポートしたモデルのサイズを確認します。
mdl = trainedModel.ClassificationEnsemble;
whos mdlName Size Bytes Class Attributes mdl 1x1 315622 classreg.learning.classif.CompactClassificationEnsemble
メモリに制限があるプログラマブル ロジック コントローラー (PLC) にモデルを展開するため、12 個すべての特徴をもつアンサンブル モデルは PLC 上で指定されたリソース内に収まらないと仮定します。
アプリ セッションの再開
分類学習器で、以前に保存したアプリ セッションを開きます。[ファイル] セクションで [開く] をクリックします。[開くファイルを選択] ダイアログ ボックスで、保存済みセッションを選択します。
特徴のランク付けを使用した特徴の選択
モデルのサイズを縮小する方法の 1 つとして、特徴のランク付けと選択を使用してモデルの特徴数を減らす方法があります。特徴セットの数を絞った新しいモデルを作成し、モデルの精度を評価します。
モデルを右クリックして [複製] を選択し、学習済みの各モデルのコピーを作成します。
分類学習器で特徴ランク付けアルゴリズムを使用するには、[学習] タブの [オプション] セクションで [特徴選択] をクリックします。[既定の特徴選択] タブが開きます。
[既定の特徴選択] タブで、[特徴のランク付けアルゴリズム] の [MRMR] をクリックします。特徴量の重要度スコアに応じて並べ替えられた棒グラフが表示されます。スコアが高いほど (
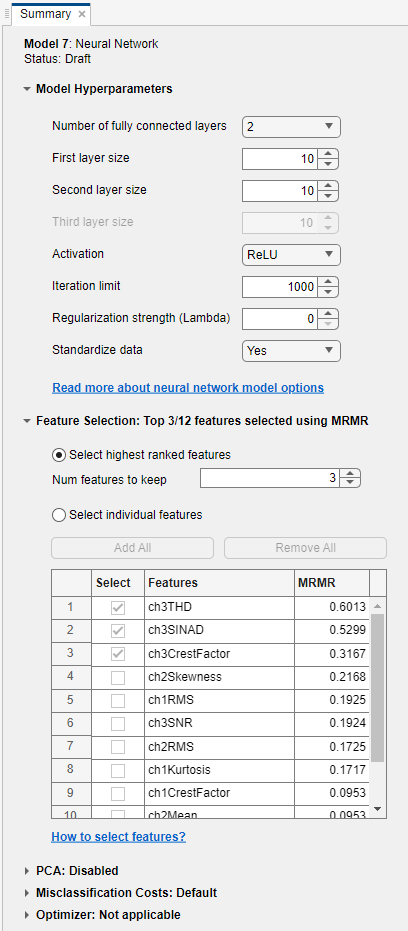
Infも含む)、特徴量の重要度が高いことを示します。ランク付けされた特徴とそのスコアの表が右側に表示されます。[特徴選択] で、検証メトリクスのバイアスを回避するために、最も高ランクの特徴を選択する既定のオプションを使用します。3 つの特徴をモデルの学習で保持するように指定します。
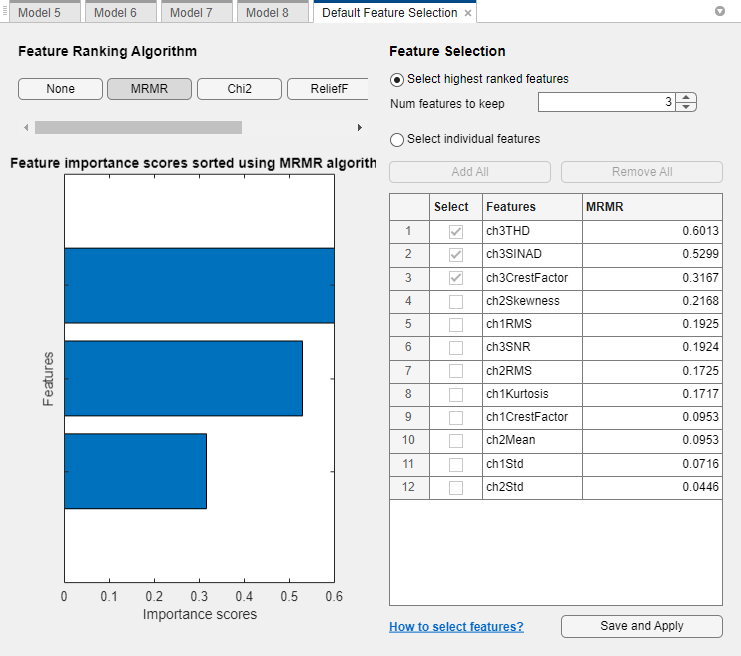
The feature ranking results are based on the full data set, including the training and validation data but not the test data. The app uses the highest ranked features to train the full model (that is, the model trained on the full data set). For each training fold, the app performs feature selection before training the model. Different folds can choose different predictors as the highest ranked features.
[保存して適用] をクリックします。特徴選択の変更が [モデル] ペインの新しいドラフト モデルに適用されます。ドラフト モデルで 3/12 個の特徴 (12 個の特徴のうち 3 個) が使用されることに注意してください。
[学習] セクションで、[すべてを学習] をクリックして [すべてを学習] を選択します。3 個の特徴を使用してすべての新しいドラフト モデルの学習が行われます。
3 つの特徴のみを使用して学習させたモデルは、すべての特徴で学習させたモデルと同程度に機能します。この結果は、上位 3 つの特徴のみに基づくモデルがすべての特徴に基づくモデルと同様の精度を達成できることを示しています。
すべての学習済みモデルの中で最も高性能なモデルは、3 つの特徴をもつニューラル ネットワーク モデルです。
特徴選択の詳細については、分類学習器アプリの使用による特徴選択と特徴変換を参照してください。
散布図における重要な特徴の調査
上位 2 つの特徴 ch3THD および ch3SINAD を使用して、最も高性能なモデルの散布図を確認します。観測されたモデルの精度が高いことを考慮すると、このプロットはクラス間の明確な分離を示すはずです。
[モデル] ペインで、最も高性能なモデル (モデル 7、ニューラル ネットワーク モデル) を選択します。
[学習] タブの [プロットと結果] セクションで [散布] をクリックします。
[予測子] の [X] と [Y] のリストを使用して、上位 2 つの重要な予測子
ch3THDおよびch3SINADを選択します。モデル予測別にグループ化した、選択した 2 つの予測子の散布図が作成されます。交差検証を使用しているため、これらの予測は検証観測値に対する予測です。つまり、ソフトウェアでは、対応する観測値を使用せずに学習させたモデルを使用して各予測値を取得します。
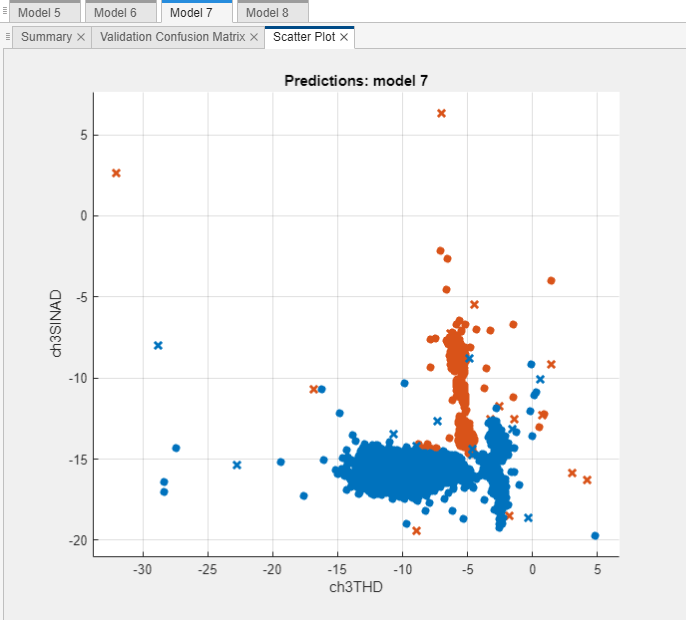
このプロットは、2 つの特徴の
BeforeカテゴリとAfterカテゴリ間の明確な分離を示しています。
詳細については、散布図における特徴量の調査と分類器の結果のプロットを参照してください。
追加の実験
最終モデルを選択するために、必要に応じて次の点についてさらに調べることができます。
モデルの精度 — 精度を向上させるには、追加のモデル タイプ ([モデル] ギャラリーの [すべて] を試すなど)、さらなる特徴選択、またはハイパーパラメーター調整を調べることができます。たとえば、学習前に [モデル] ペインでドラフト モデルを選択し、モデルの [概要] タブをクリックします。[モデルのハイパーパラメーター] セクションで分類器のハイパーパラメーターのオプションを指定できます。このタブの [特徴選択] セクションと [PCA] セクションでもオプションを設定できます。
特定のモデル タイプのハイパーパラメーターを自動的に調整する場合、[モデル] ギャラリーで対応する最適化可能なモデルを選択してハイパーパラメーターの最適化を実行できます。詳細は、分類学習器アプリのハイパーパラメーターの最適化を参照してください。
計算量 — 学習済みモデルの [概要] タブで、学習時間と予測速度を確認できます。たとえば、学習済みモデルの [概要] タブを見てみます。

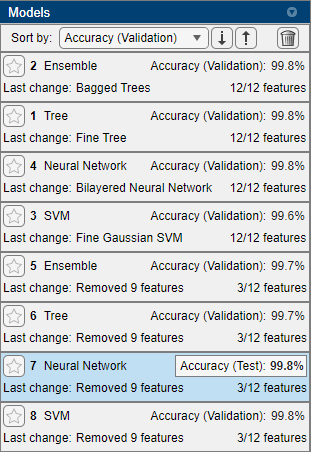
検証精度と計算量に基づいて上位 3 つの特徴で学習させたニューラル ネットワーク モデルを使用することに決めたと仮定します。
テスト セットでのモデルの精度評価
テスト セットの精度を未観測データでのモデルの精度推定値として使用できます。テスト セットを使用してニューラル ネットワーク モデルを評価します。
[モデル] ペインで、ニューラル ネットワーク モデルを選択します。
[テスト] タブの [テスト] セクションで [選択項目をテスト] をクリックします。
データ セット全体で学習させたモデルのテスト セットの性能が計算されます。予想どおり、モデルは検証精度と比較してテスト データで同様の精度 (99.8%) を達成します。
テスト セットの混同行列を表示します。[テスト] タブの [プロットと結果] セクションで [混同行列 (テスト)] をクリックします。

詳細については、テスト データ セットを使用したモデルの性能の評価を参照してください。
最終モデルのエクスポート
最終モデルをワークスペースにエクスポートし、モデルのサイズを確認します。
分類学習器で、ニューラル ネットワーク モデルを [モデル] ペインから選択します。
[学習] タブの [エクスポート] セクションで、[モデルのエクスポート] をクリックして [モデルをワークスペースにエクスポート] を選択します。
必要な場合は、エクスポートする変数の名前を [分類モデルのエクスポート] ダイアログ ボックスで編集します。[OK] をクリックします。既定の名前は
trainedModel1です。関数
whosを使用してモデルのサイズを確認します。mdl_final = trainedModel1.ClassificationNeuralNetwork; whos mdl_finalName Size Bytes Class Attributes mdl_final 1x1 7842 classreg.learning.classif.CompactClassificationNeuralNetwork
最終モデル (
trainedModel1のmdl_final) のサイズは、アンサンブル モデル (trainedModelのmdl) のサイズより小さくなっています。
予測用のコードの生成や予測の展開といった次に行う可能性のある手順の詳細については、新しいデータを予測するための分類モデルのエクスポートを参照してください。