bootci
ブートストラップ信頼区間
構文
説明
例
統計的工程管理の能力指数に対する信頼区間を計算します。
平均 1 および標準偏差 1 をもつ正規分布から 30 個の乱数を生成します。
rng('default') % For reproducibility y = normrnd(1,1,30,1);
工程の下方仕様限界と上方仕様限界を指定します。能力指数を定義します。
LSL = -3; USL = 3; capable = @(x)(USL-LSL)./(6*std(x));
2000 個のブートストラップ標本を使用して、能力指数に対する 95% の信頼区間を計算します。既定では、bootci は BCa 法 (bias corrected and accelerated percentile method) を使用して信頼区間を作成します。
ci = bootci(2000,capable,y)
ci = 2×1
0.5937
0.9900
能力指数に対するスチューデント化された信頼区間を計算します。
sci = bootci(2000,{capable,y},'Type','student')sci = 2×1
0.5193
0.9930
非線形回帰モデルの係数に対するブートストラップ信頼区間を計算します。この例で使用する手法では、予測子と応答の値のブートストラッピングを行い、予測子変数を確率変数と見なします。予測子変数を固定変数と見なし、残差をブートストラッピングする手法については、線形回帰モデル係数に対するブートストラップ信頼区間を参照してください。
メモ: この例では nlinfit を使用します。これは、非線形回帰モデルの係数推定値または残差のみが必要な場合や、ブートストラッピングのようにモデルを複数回繰り返して当てはめる必要がある場合に便利です。当てはめた回帰モデルをさらに調べる必要がある場合は、fitnlm を使用して非線形回帰モデル オブジェクトを作成します。オブジェクト関数 coefCI を使用して結果のモデルの係数に対する信頼区間を作成できますが、この関数ではブートストラッピングは使用しません。
非線形回帰モデル からデータを生成します。ここで、、 および は係数です。予測子変数 x は、平均が 2 の指数分布に従います。誤差項 は、平均が 0、標準偏差が 0.1 の正規分布に従います。
modelfun = @(b,x)(b(1)+b(2)*exp(-b(3)*x)); rng('default') % For reproducibility b = [1;3;2]; x = exprnd(2,100,1); y = modelfun(b,x) + normrnd(0,0.1,100,1);
beta0 にある初期値を使用する非線形回帰モデルの関数ハンドルを作成します。
beta0 = [2;2;2]; beta = @(predictor,response)nlinfit(predictor,response,modelfun,beta0)
beta = function_handle with value:
@(predictor,response)nlinfit(predictor,response,modelfun,beta0)
非線形回帰モデルの係数に対する 95% のブートストラップ信頼区間を計算します。生成されたデータ x および y からブートストラップ標本を作成します。
ci = bootci(1000,beta,x,y)
ci = 2×3
0.9821 2.9552 2.0180
1.0410 3.1623 2.2695
最初の 2 つの信頼区間には、それぞれ真の係数値 および が含まれています。ただし、3 番目の信頼区間には真の係数値 が含まれていません。
ここで、モデル係数に対する 99% のブートストラップ信頼区間を計算します。
newci = bootci(1000,{beta,x,y},'Alpha',0.01)newci = 2×3
0.9730 2.9112 1.9562
1.0469 3.1876 2.3133
3 つすべての信頼区間に真の係数値が含まれています。
線形回帰モデルの係数に対するブートストラップ信頼区間を計算します。この例で使用する手法では、残差のブートストラッピングを行い、予測子変数を固定変数と見なします。予測子変数を確率変数と見なし、予測子と応答の値をブートストラッピングする手法については、非線形回帰モデル係数に対するブートストラップ信頼区間を参照してください。
メモ: この例では regress を使用します。これは、回帰モデルの係数推定値または残差のみが必要な場合や、ブートストラッピングのようにモデルを複数回繰り返して当てはめる必要がある場合に便利です。当てはめた回帰モデルをさらに調べる必要がある場合は、fitlm を使用して線形回帰モデル オブジェクトを作成します。オブジェクト関数 coefCI を使用して結果のモデルの係数に対する信頼区間を作成できますが、この関数ではブートストラッピングは使用しません。
標本データを読み込みます。
load hald線形回帰を実行し、残差を計算します。
x = [ones(size(heat)),ingredients]; y = heat; b = regress(y,x); yfit = x*b; resid = y - yfit;
線形回帰モデルの係数に対する 95% のブートストラップ信頼区間を計算します。残差からブートストラップ標本を作成します。'Type','normal' を指定して、バイアスと標準誤差をブートストラップした正規近似区間を使用します。この場合、既定の信頼区間のタイプは使用できません。
ci = bootci(1000,{@(bootr)regress(yfit+bootr,x),resid}, ...
'Type','normal')ci = 2×5
-47.7130 0.3916 -0.6298 -1.0697 -1.2604
172.4899 2.7202 1.6495 1.2778 0.9704
切片項を省略して推定された係数 b をプロットし、係数の信頼区間を示す誤差範囲を表示します。
slopes = b(2:end)';
lowerBarLengths = slopes-ci(1,2:end);
upperBarLengths = ci(2,2:end)-slopes;
errorbar(1:4,slopes,lowerBarLengths,upperBarLengths)
xlim([0 5])
title('Coefficient Confidence Intervals')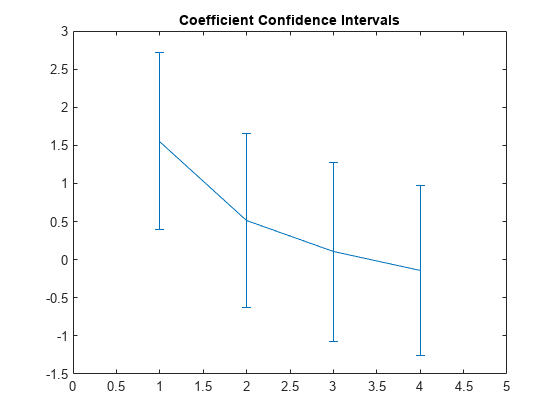
最初の非切片係数のみが 0 と有意に異なります。
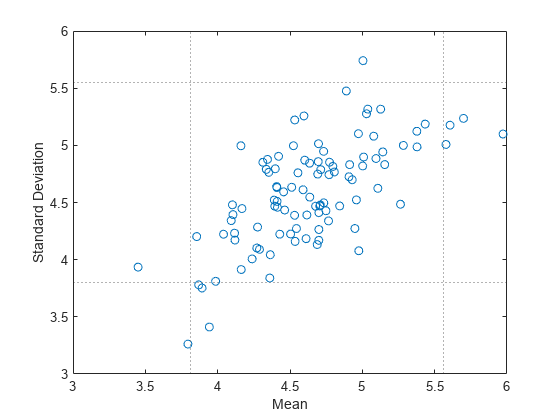
100 個のブートストラップ標本の平均値と標準偏差を計算します。各統計量に対する 95% 信頼区間を求めます。
平均 5 をもつ指数分布から 100 個の乱数を生成します。
rng('default') % For reproducibility y = exprnd(5,100,1);
ベクトル y から 100 個のブートストラップ標本を抽出します。各ブートストラップ標本について平均値と標準偏差を計算します。平均値と標準偏差に対する 95% のブートストラップ信頼区間を求めます。
[ci,bootstat] = bootci(100,@(x)[mean(x) std(x)],y);
ci(:,1) には平均値の信頼区間の下限と上限が格納され、c(:,2) には標準偏差の信頼区間の下限と上限が格納されます。bootstat の各行にはブートストラップ標本の平均値と標準偏差が格納されます。
各ブートストラップ標本の平均値と標準偏差を点としてプロットします。平均値の信頼区間の下限と上限を垂直方向の点線としてプロットし、標準偏差の信頼区間の下限と上限を水平方向の点線としてプロットします。
plot(bootstat(:,1),bootstat(:,2),'o') xline(ci(1,1),':') xline(ci(2,1),':') yline(ci(1,2),':') yline(ci(2,2),':') xlabel('Mean') ylabel('Standard Deviation')
入力引数
名前と値の引数
出力引数
参照
拡張機能
バージョン履歴
R2006a で導入