generatePolicyBlock
Generate Simulink block that evaluates policy of an agent or policy object
Since R2022b
Syntax
Description
This function generates a Simulink® Policy evaluation block from an agent or policy object. It also creates a data file which stores policy information. The generated policy block loads this data file to properly initialize itself prior to simulation. You can use the block to simulate the policy and generate code for deployment purposes.
For more information on policies and value functions, see Create Policies and Value Functions.
generatePolicyBlock(___,MATFileName=
specifies the file name of the data file.dataFileName)
Examples
First, create and train a reinforcement learning agent. For this example, load the PG agent trained in Train PG Agent to Balance Discrete Cart-Pole System.
load("MATLABCartpolePG.mat","agent")
Then, create a policy evaluation block from this agent using default names.
generatePolicyBlock(agent);
This command creates an untitled Simulink® model, containing the policy block, and the blockAgentData.mat file, containing information needed to create and initialize the policy block (such as the trained deep neural network used by the actor within the agent). The block loads this data file to properly initialize itself prior to simulation.
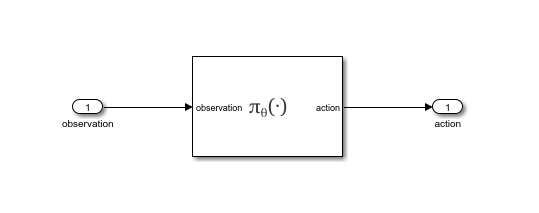
You can now drag and drop the block in a Simulink model and connect it so that it takes the observation from the environment as input and so that the calculated action is returned to the environment. This allows you to simulate the policy in a closed loop. You can then generate code for deployment purposes. For more information, see Deploy Trained Reinforcement Learning Policies.
Close the model.
bdclose("untitled")Create observation and action specification objects. For this example, define the observation and action spaces as continuous four- and two-dimensional spaces, respectively.
obsInfo = rlNumericSpec([4 1]); actInfo = rlNumericSpec([2 1]);
Alternatively use getObservationInfo and getActionInfo to extract the specification objects from an environment.
Create a continuous deterministic actor. This actor must accept an observation as input and return an action as output.
To approximate the policy function within the actor, use a recurrent deep neural network model. Define the network as an array of layer objects, and get the dimension of the observation and action spaces from the environment specification objects. To create a recurrent network, use a sequenceInputLayer as the input layer (with size equal to the number of dimensions of the observation channel) and include at least one lstmLayer.
layers = [
sequenceInputLayer(obsInfo.Dimension(1))
fullyConnectedLayer(10)
reluLayer
lstmLayer(8,OutputMode="sequence")
fullyConnectedLayer(20)
fullyConnectedLayer(actInfo.Dimension(1))
tanhLayer
];Convert the network to a dlnetwork object and display the number of weights.
model = dlnetwork(layers); summary(model)
Initialized: true
Number of learnables: 880
Inputs:
1 'sequenceinput' Sequence input with 4 dimensions
Create the actor using model, and the observation and action specifications.
actor = rlContinuousDeterministicActor(model,obsInfo,actInfo)
actor =
rlContinuousDeterministicActor with properties:
ObservationInfo: [1×1 rl.util.rlNumericSpec]
ActionInfo: [1×1 rl.util.rlNumericSpec]
Normalization: "none"
UseDevice: "cpu"
Learnables: {9×1 cell}
State: {2×1 cell}
Check the actor with a random observation input.
act = getAction(actor,{rand(obsInfo.Dimension)});
act{1}ans = 2×1 single column vector
-0.0742
0.0158
Create a policy object from actor.
policy = rlDeterministicActorPolicy(actor)
policy =
rlDeterministicActorPolicy with properties:
Actor: [1×1 rl.function.rlContinuousDeterministicActor]
Normalization: "none"
ObservationInfo: [1×1 rl.util.rlNumericSpec]
ActionInfo: [1×1 rl.util.rlNumericSpec]
SampleTime: -1
You can access the policy options using dot notation. Check the policy with a random observation input.
act = getAction(policy,{rand(obsInfo.Dimension)});
act{1}ans = 2×1
-0.0060
-0.0161
You can train the policy with a custom training loop.
Then, create a policy evaluation block from this policy object using the default name for the generated MAT file.
generatePolicyBlock(policy);
This command creates an untitled Simulink® model, containing the policy block, and the blockAgentData.mat file, containing information needed to create and initialize the policy block, (such as the trained deep neural network used by the actor within the agent). The block loads this data file to properly initialize itself prior to simulation.
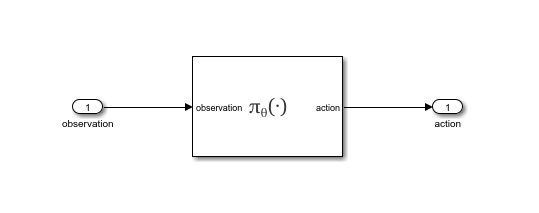
You can now drag and drop the block in a Simulink® model and connect it so that it takes the observation from the environment as input and so that the calculated action is returned to the environment. This allows you to simulate the policy in a closed loop. You can then generate code for deployment purposes. For more information, see Deploy Trained Reinforcement Learning Policies.
Close the model.
bdclose("untitled")Input Arguments
Version History
Introduced in R2022b
See Also
Functions
Objects
rlMaxQPolicy|rlEpsilonGreedyPolicy|rlAdditiveNoisePolicy|rlDeterministicActorPolicy|rlStochasticActorPolicy|rlHybridStochasticActorPolicy|dlnetwork